Cloud Run 콜드 스타트 삽질기
들어가며
서비스를 배포 비용을 최소화 하기위해 노력해본 사람들은 콜드 스타트에 대한 경험이 있을 것이다. 필자도 Hit Me Up 이라는 서비스를 운영하며 겪었던 콜드 스타트에서 벗어나기까지의 과정을 기록해 보고자 한다.
콜드 스타트란?
클라우드 환경에서 일정 시간 요청이 없으면 인스턴스가 자동 종료되고, 다시 요청이 들어올 때 서버가 재시작되면서 초기화 지연이 발생하는 현상을 콜드 스타트라고 한다.
이로 인해 사용자에게 서비스 응답 지연이 발생해 불편함을 줄 수 있다. 특히 Cloud Run 같은 서버리스 환경에서 빈번히 나타난다.
문제 상황
처음 Cloud Run에 Spring Boot 애플리케이션을 배포했을 때 콜드 스타트 문제는 간단히 해결될 줄 알았다. Google 문서에 따르면 Cloud Run 인스턴스는 요청이 없으면 15분 후에 자동으로 종료된다고 했기 때문이다.
“그럼 15분마다 한 번씩 ping 보내면 되겠네!” 라고 생각했고 그래서 다음과 같이 간단한 github actions 자동화 스크립트를 작성했다.
1
2
3
4
# 첫 번째 시도: 15분 간격
on:
schedule:
- cron: '*/15 * * * *' # 15분마다 실행
여기 cron 표현식은 공백으로 구분된 다섯 개의 필드로 이루어져 있고, 각 필드는 다음을 나타낸다.
-
분(Minute): 0부터 59까지 -
시(Hour): 0부터 23까지 -
일(Day of Month): 1부터 31까지 -
월(Month): 1부터 12까지 -
요일(Day of Week): 0부터 6까지 (0은 일요일, 6은 토요일)
15분 외 *은 모든 항목을 선택한다는 의미다.
테스트 해보니 여전히 콜드 스타트가 발생했고, 응답 시간이 10초가 넘는 상황이 반복됐다.
첫 번째 시도: 10분으로 단축
“10분으로 줄여보자”
1
2
3
4
# 두 번째 시도: 10분 간격
on:
schedule:
- cron: '*/10 * * * *' # 10분마다 실행
하지만 여전히 콜드 스타트는 계속 발생했다. 뭔가 근본적으로 잘못되었다는 것을 깨닫고 분석해보았다.
GitHub Actions의 불안정성
Cloud Run 로그를 살펴보았다.
로그 데이터:
1
2
3
4
5
6
7
8
9
10
11
12
23:50 ping (9월 6일) → 01:49 ping (9월 7일) = 1시간 59분
01:49 ping → 02:57 ping = 1시간 8분
02:57 ping → 03:36 ping = 39분
03:36 ping → 03:52 ping = 16분
03:52 ping → 04:25 ping = 33분
...
20:21 ping 성공
20:38 ping (10.503s) - 콜드스타트 (17분 후)
20:50 ping 성공
21:39 ping (10.741s) - 콜드스타트 (49분 후!!)
GitHub Actions의 cron 스케줄이 정확히 실행되지 않고 있었던 것이다. */10 설정에도 불구하고 완전히 불규칙하게 실행되고 있었다.
이에 Github Actions 공식문서를 통해 다음과 같은 명시적인 경고를 찾을 수 있었다.
Note: The schedule event can be delayed during periods of high loads of GitHub Actions workflow runs. High load times include the start of every hour. If the load is sufficiently high enough, some queued jobs may be dropped. To decrease the chance of delay, schedule your workflow to run at a different time of the hour.
즉, 워크플로우 실행량이 많으면 예약 이벤트가 지연되거나 누락될 수 있다는 것이다.
두 번째 시도: 5분 교차 워밍 전략
문제를 해결하기 위해 이중 스케줄 전략을 고안했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
name: Keep Cloud Run Warm
on:
schedule:
- cron: '*/5 * * * *' # 0,5,10,15,20,25,30,35,40,45,50,55분
- cron: '2-59/5 * * * *' # 2,7,12,17,22,27,32,37,42,47,52,57분
workflow_dispatch:
jobs:
warm-service:
runs-on: ubuntu-latest
timeout-minutes: 3
steps:
- name: Primary ping
id: primary
run: |
if curl -f -s -o /dev/null --max-time 20 \
"https://hitmeup-backend-593087166771.asia-northeast1.run.app/api/ping"; then
echo "success=true" >> $GITHUB_OUTPUT
else
echo "success=false" >> $GITHUB_OUTPUT
fi
- name: Backup ping
if: steps.primary.outputs.success != 'true'
run: |
sleep 30
curl -f -s -o /dev/null --max-time 20 \
"https://hitmeup-backend-593087166771.asia-northeast1.run.app/api/ping"
이 방법의 핵심은 다음과 같다.
- 5분 간격 이중 스케줄링: 두 개의 cron이 번갈아가며 실행되어 실질적으로 2.5분마다
ping - 백업 메커니즘: 첫 번째 ping이 실패하면 30초 후 재시도
- 안전 마진: 한 스케줄이 지연되어도 다른 스케줄이 백업 역할
스케줄링 시간 간격을 극단적으로 줄여버려서 그런지, 이 방법으로 콜드 스타트 오류는 면하게 되었다!
새로운 문제: 비용 폭탄 위험
Github Actions도 무제한이 아니다. 한달에 사용 가능한 시간 제한이 있다.
Github Actions Billing 에서 Free 플랜을 보면 아래 표와 같다.
| 계획 | 스토리지 | 분(월) |
|---|---|---|
| GitHub Free | 500 MB | 2,000 |
필자는 현재 Github Education으로 다음과 같은 사용량 제한이 있다.
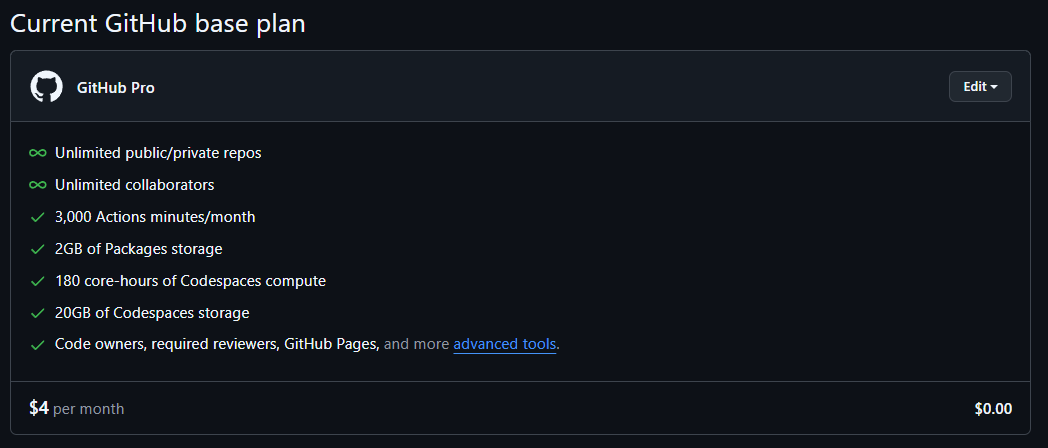
사진을 보면 3000 Actions 분/월 인데 이 제한을 넘어가면 비용이 청구되는 것이다.
5분 교차 전략을 적용하려고 비용을 계산해보았다.
- 5분 이중 스케줄 : 월 17,280분 → 576% 초과 ❌
- 10분 단일 스케줄 : 월 4,320분 → 144% 초과 ❌
- 예상 추가 비용 : $10.56/월 (10분) ~ $114.24/월 (5분 이중)
Pro 계정이어도 둘 다 할당량을 초과한다는 현실을 깨달았다.
최소 인스턴스수를 0으로 만들며 몇달러 줄이려다, 오히려 비용이 여기서 더 발생하는 상황을 만든 것이다.
마지막 해결책: UptimeRobot
이에 Github Actions가 아닌 외부 모니터링 서비스를 검색했다.
그리고 발견한 서비스가 UptimeRobot 이다.
UptimeRobot을 선택한 이유는 다음과 같은 무료 플랜의 장점때문이다.
- 50개 모니터 - 1개도 충분하고 여유롭게 여러개 사용 가능
- 짧은 시간 간격 - 최소 30초부터 가능하고 디폴트값인 5분으로 충분히 콜드스타트 방지 가능
- 전용 모니터링 서비스 - GitHub Actions보다 안정적으로 정확히 작동함
- 즉시 알림 - 문제 발생 시 이메일, SMS, 전화, 전용 앱 푸시 등으로 바로 확인가능
설정 방법도 매우 간단했다.
- 무료로 사이트 가입을 한다.
- 모니터 타입을 선택한다.(필자의 서비스는 웹 서비스 엔드포인트로 요청을 보내는 것이 목표이므로 “HTTP / website monitoring” 선택)
- 타겟 URL 등 설정을 한다
- 자신이 원하는 작업 엔드 포인트
ex)
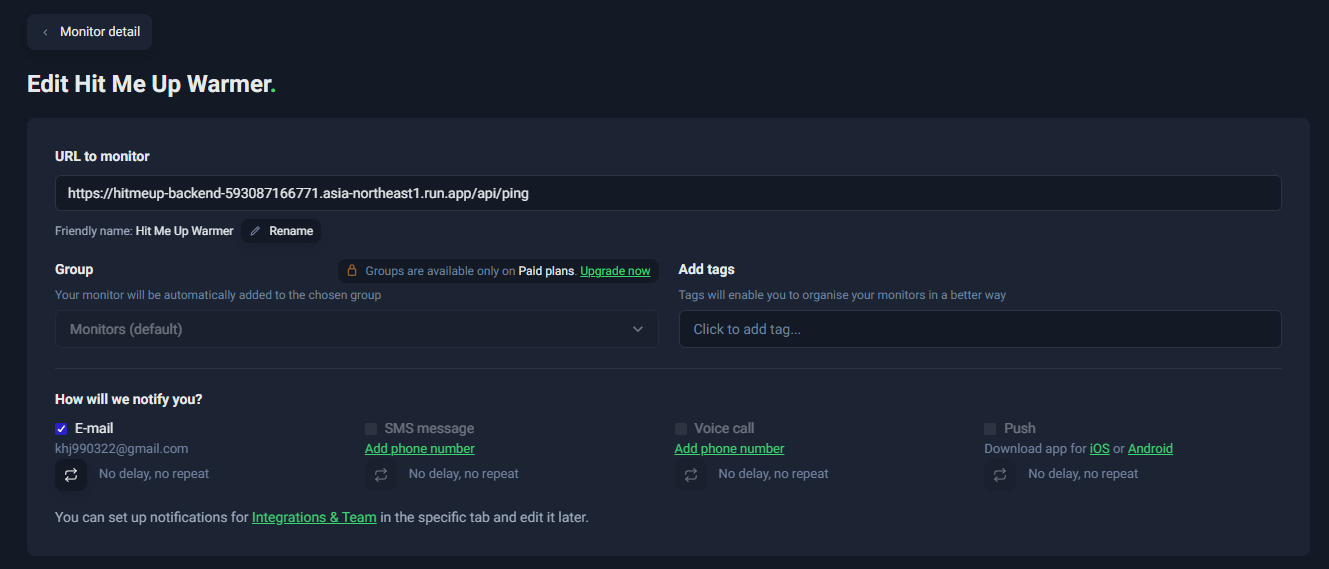
https://hitmeup-backend-593087166771.asia-northeast1.run.app/api/ping - Friendly Name: Hit Me Up Warmer
- Monitoring Interval: 5 minutes (Default값)
- Request Timeout: 30 seconds (Default값)
- 자신이 원하는 작업 엔드 포인트
ex)
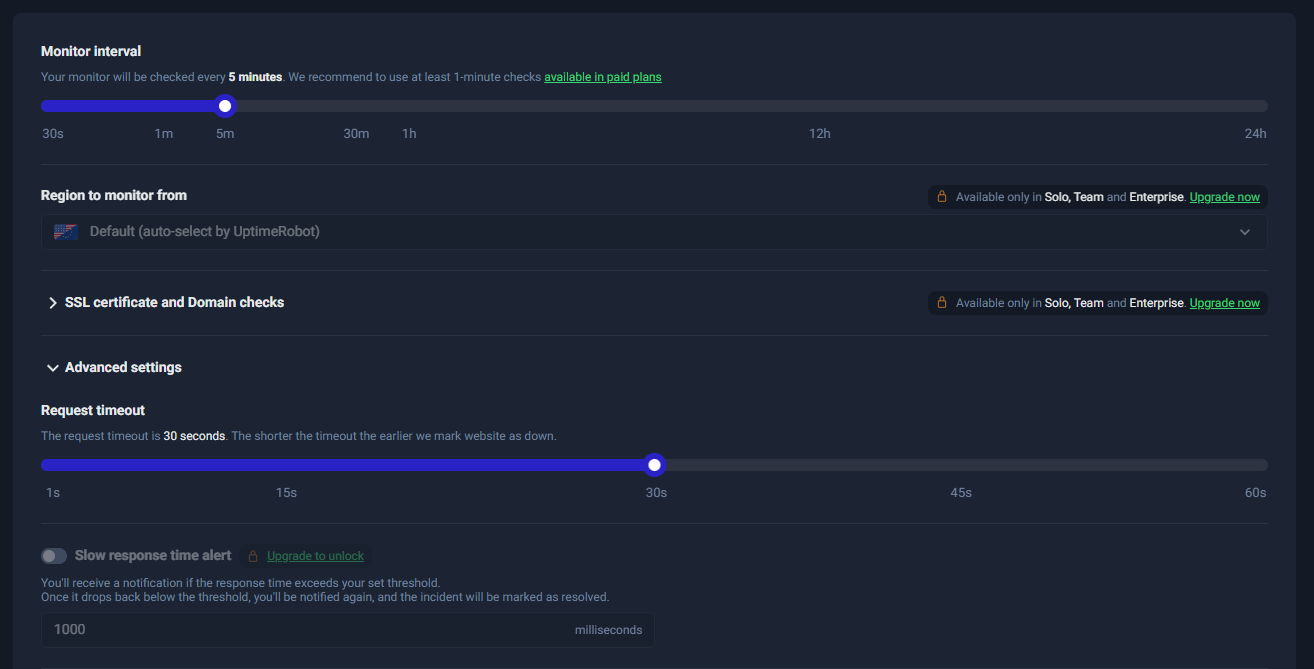
결과
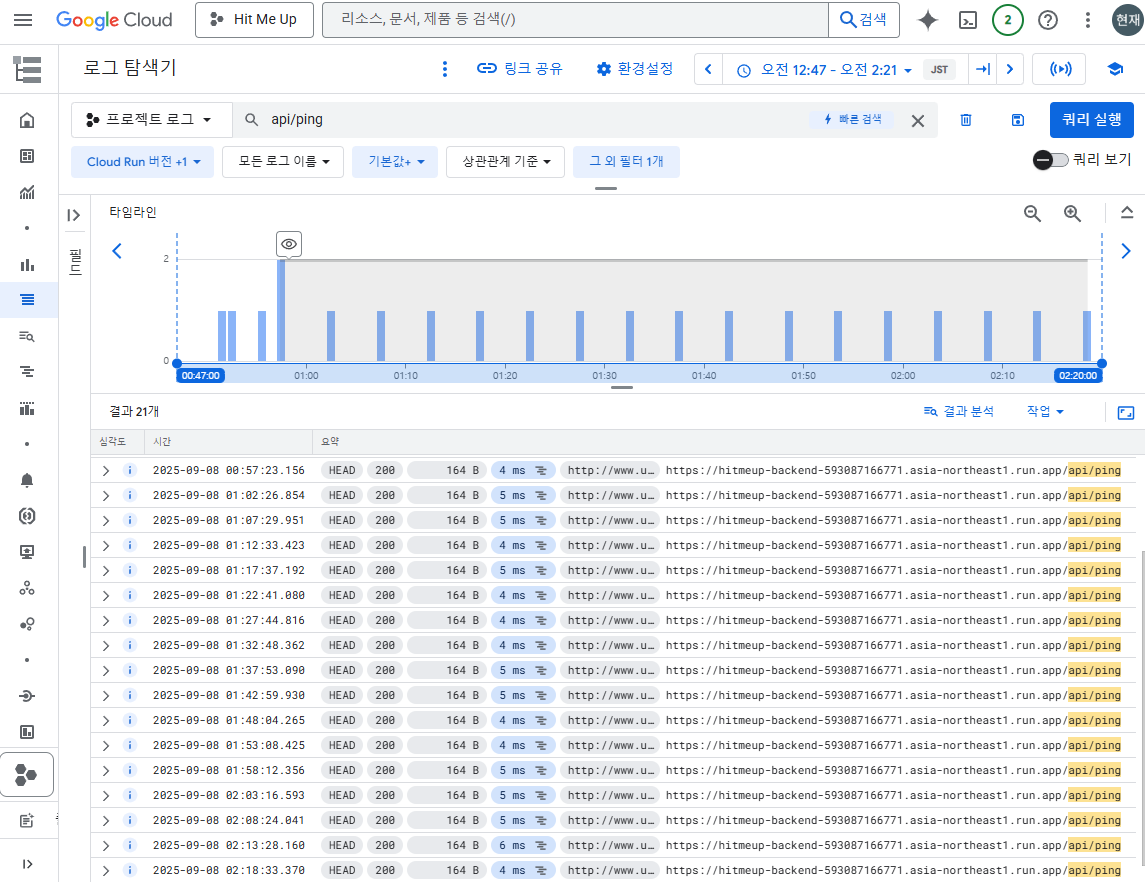
위 사진은 Cloud Run 로그 탐색기에서 warmer 요청인 ping 엔드포인트 로그를 확인한 결과다.
몇초 이하의 딜레이를 제외하고 거의 정확히 5분간격으로 잘 실행되는것을 볼 수 있다.
또한 UptimeRobot 대시보드에서도 문제없이 잘 작동함을 확인할 수 있다.
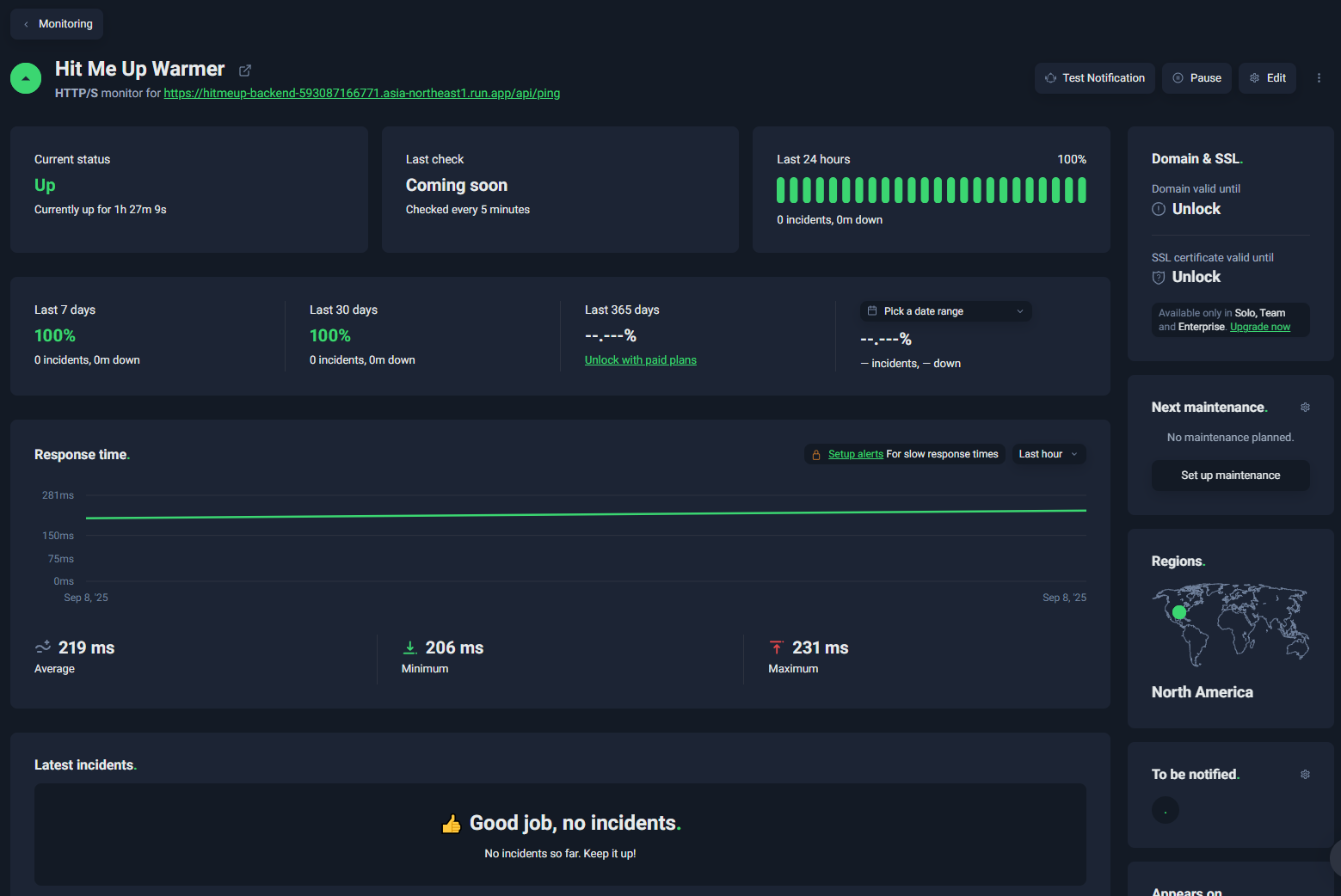
요약하자면 아래와 같은 개선이 있었다.
이전 상황 (GitHub Actions) :
1
2
3
20:38 ping (10.503초) - 콜드스타트
21:39 ping (10.741초) - 콜드스타트
간격: 17분, 49분, 최대 1시간 59분!
이후 상황 (UptimeRobot 5분 간격) :
1
2
3
4
00:57:23 - UptimeRobot 요청 (4ms 응답) ✅
01:02:26 - UptimeRobot 요청 (5ms 응답) ✅
01:07:29 - UptimeRobot 요청 (5ms 응답) ✅
간격: 오차범위 내에서 거의 정확히 5분!
성능 개선: 10초 → 5ms (2,000배 개선!)
이렇게 완전히 무료로 콜드 스타트를 해결할 수 있었다.
마치며
15분이면 충분할 줄 알았던 단순한 생각에서 시작해, GitHub Actions의 불안정성을 발견하고, 무료 할당량의 현실을 깨달으며, 최종적으로 UptimeRobot이라는 완벽한 해결책을 찾아가는 여정이었다.
때로는 문제의 원인이 예상과 전혀 다른 곳에 있을 수 있다는 것을 배웠다. Cloud Run 자체의 문제가 아니라 GitHub Actions의 스케줄링 이슈였던 것처럼 말이다.
ps. 무료로 콜드 스타트를 해결하고 싶다면, UptimeRobot을 강력히 추천한다. GitHub Actions의 불안정함과 비용 문제를 모두 해결해주는 완벽한 솔루션이다. (광고아님)