Computer Networking: a Top Down Approach - (7)

Transport Layer - (4)

TCP 특징
- Point-to-point
- 한 프로세스와 한 프로세스(한 소켓 쌍) 간의 연결만 처리 (One Sender, One Receiver)
- Reliable, in-order byte stream : 신뢰 가능하게 유실되지 않으면서, 순서대로 처리
- pipelined : 한방에 덩어리로 보냄
- full-duplex data : 양쪽다 서로 보냄(ACK도 보내는거니까)
- Send & Receive Buffer : 양쪽 다 2개의 버퍼가 있음
- Sender에선 재전송하기 위해서.
- Receiver에선 Out of Order로 들어오는 패킷들 Sequence # 체크해서 버리지 않고 잘 보관해두려고.
- connection-oriented : Hand Shake
- flow controlled : Receiver에서 받을 수 있는만큼 조절해서 보냄
- Congestion controlled : 내부 네트워크 상황 보고 네트워크가 받아들일 수 있는 양만큼 네트워크에 보냄
TCP Segment Structure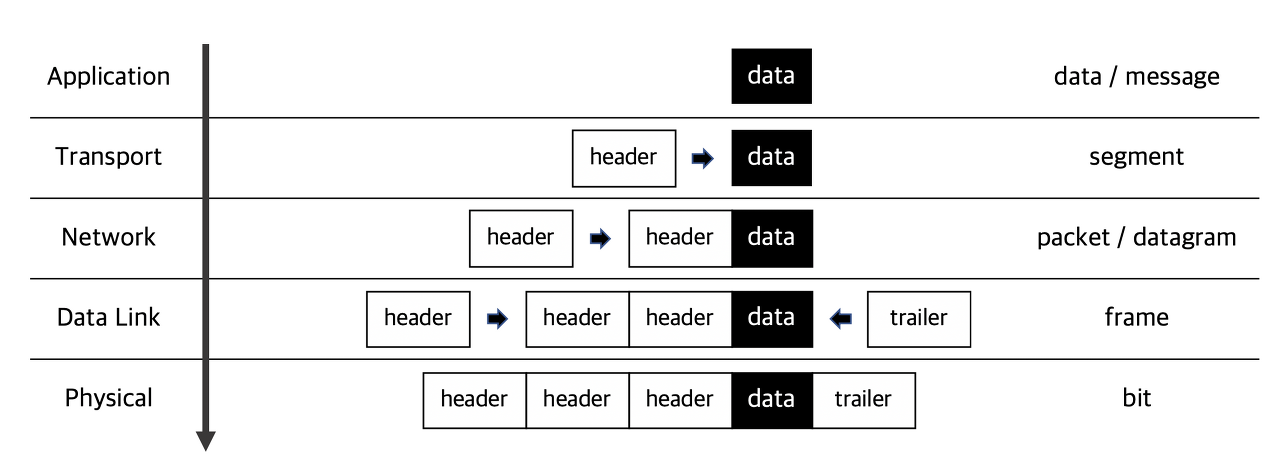
Transport (TCP) 계층 전송단위는 Segment, Header에 메타데이터, Data에 application계층의 Data 들어감. 전송하는 입장에선 Header(메타데이터) 만 보고 전송하면 된다. 내부 데이터는 보지않는다. 예를들어 우편배달부가 편지를 전송할 때 편지봉투에 적힌 이름, 주소정보(메타데이터) 들을 보고 전달하지 편지봉투를 열어 편지 내용을 보고 전달하지 않는 것과 같다.
Header이 layer에서 매우매우 중요함.
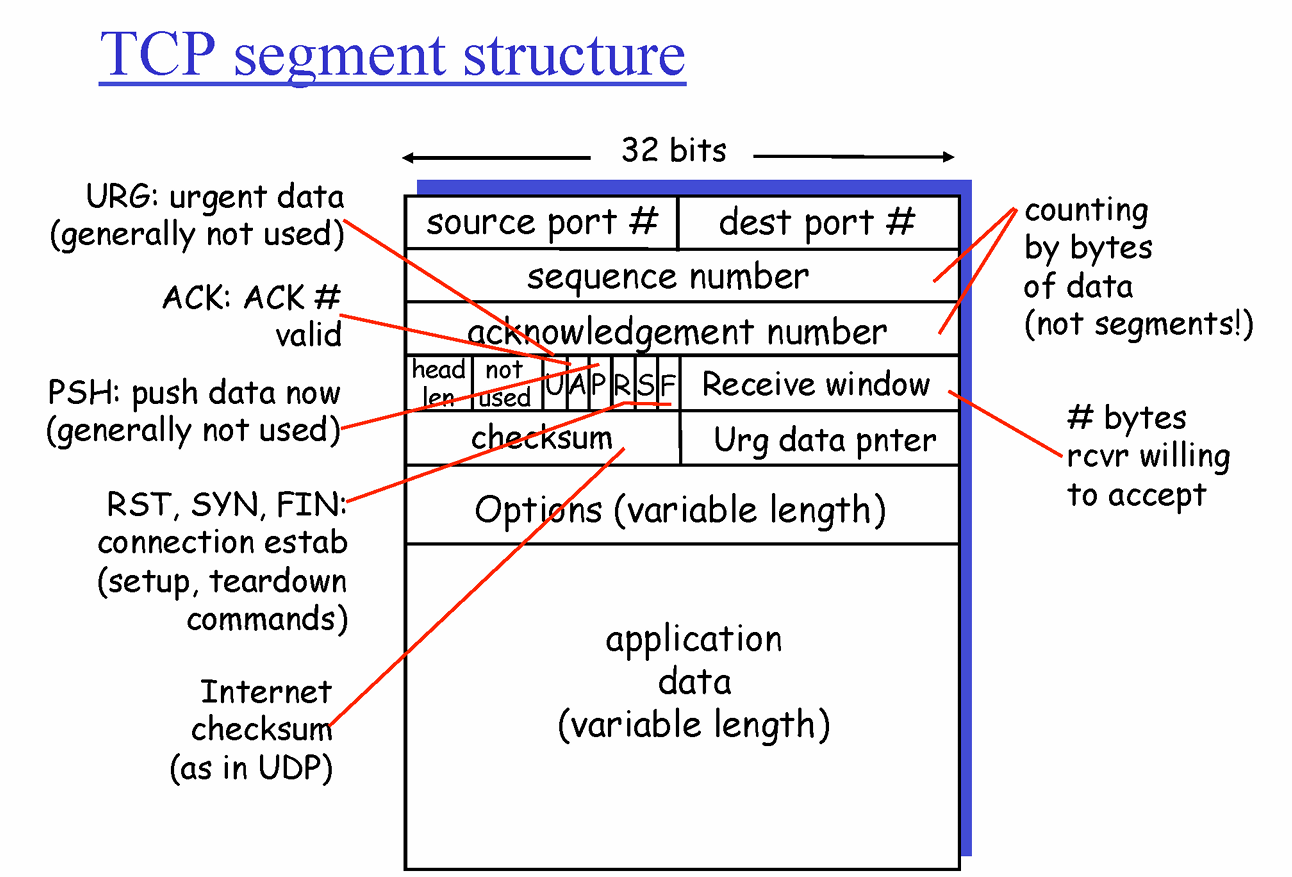
TCP 세그먼트 구조
Source Port(16 bits): 송신자의 포트 번호. Sender Application이 사용하는 포트 번호.Destination Port(16 bits): 수신자의 포트 번호를 나타냅니다. 데이터를 Receiver Application이 사용하는 포트 번호.- 16bit -> 0 ~ $2^{16} - 1$ 개 -> 동시에 동작할 수 있는 네트워크 애플리케이션 수 이론상 65536개
Sequence Number(32 bits): 데이터의 순서를 추적하는 번호. 처음 연결 시에는 랜덤한 값으로 시작하며, 이후 전송된 바이트 수에 따라 증가한다. 수신자가 데이터의 순서를 정확히 재조립할 수 있게 함.Acknowledgment Number(32 bits): 송신자가 수신한 데이터의 다음 예상 시퀀스 번호. 이전에 받은 데이터에 대한 확인 응답을 나타낸다.Data Offset(4 bits): TCP 헤더의 크기. 일반적으로 20 바이트가 기본이지만, 선택적으로 헤더가 확장될 수 있기 때문에 이 필드는 데이터가 시작되는 위치를 나타낸다.Window Size(16 bits): 수신자가 한 번에 받을 수 있는 데이터의 양. 흐름 제어를 위해 사용한다.Checksum(16 bits): 헤더와 데이터의 무결성을 확인하기 위한 오류 검사 값. 송신자는 이 필드를 계산하고, 수신자는 이 값으로 데이터가 손상되었는지 확인한다.Urgent Data Pointer(16 bits): URG 플래그가 설정된 경우, 긴급 데이터의 끝을 나타낸다. 일반적으로 잘 사용되지 않지만, 긴급 데이터를 처리할 때 유용하다.Options(Variable Length): 선택적으로 사용하는 필드로, TCP 연결을 설정할 때 다양한 추가 정보를 제공하는 데 사용됩니다. 대표적으로 Maximum Segment Size (MSS)와 Window Scaling 옵션이 있습니다.Padding: 옵션 필드를 32비트 경계로 맞추기 위해 사용된다. 옵션 필드의 길이가 32비트로 나누어 떨어지지 않으면 패딩을 추가한다.
TCP seq# & ACKs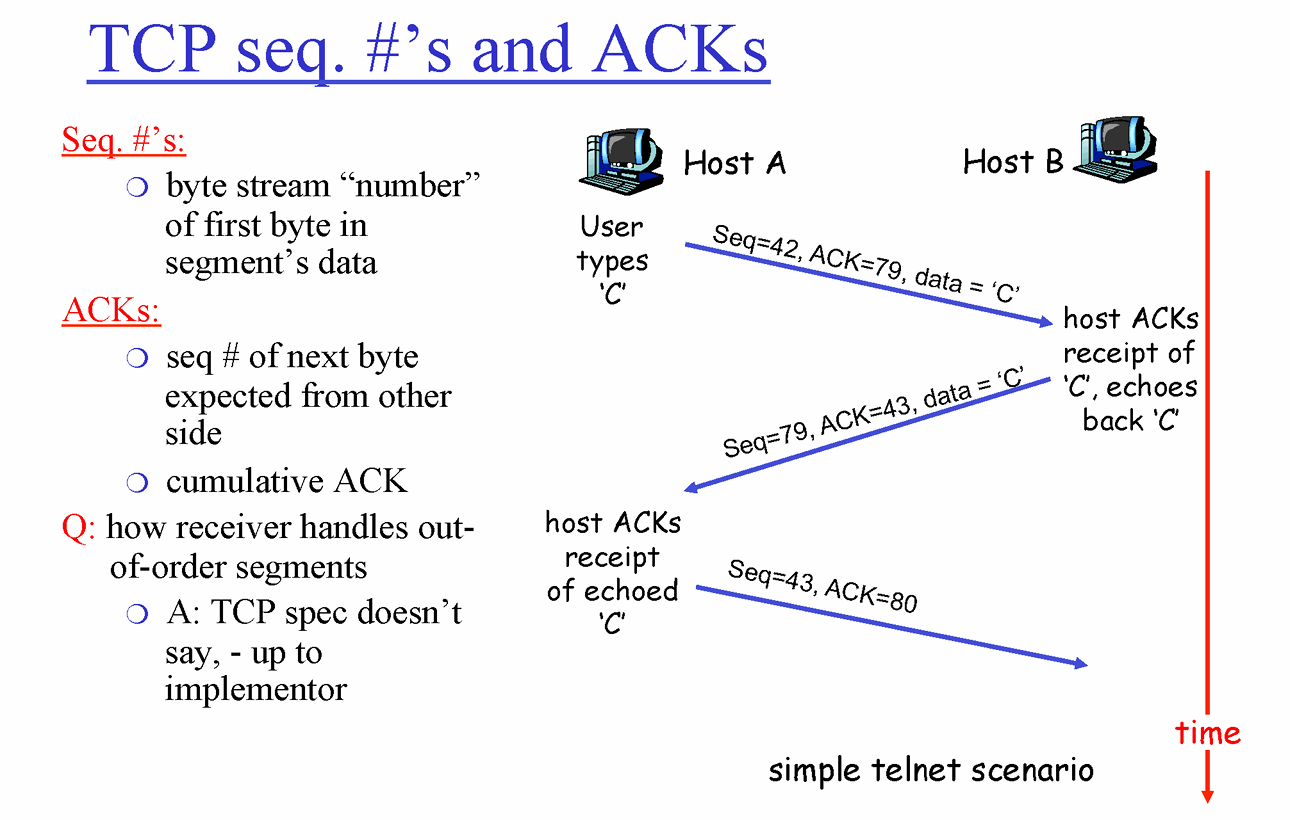
- C 라는 char이 TCP Segment에 담긴다.
- TCP에서 사용하는 Sequence Number은 Data를 Window Size만큼 잘라보낼때 제일 앞에 있는 데이터 Byte 번호다. ex) 100Byte짜리 메시지를 10Byte짜리 Segment씩 보낸다고 가정해보자. 그럼 [ 0~9 ], [ 10~19 ], . . . 이런식으로 나뉘어 질 것이다. 그러면 첫번째 [ 0~9 ] 의 Sequence # 는 이 중 맨 앞인 0번이 된다. 다음 세그먼트의 Seqence # 는 10번이 된다. TCP는 이런식으로 번호가 매겨지게된다.
- TCP에서 ACK는 이전 Go-Back-N의 ACK와 헷갈리게도 좀 다르다. 이전에 GBN에서는 ACK 10은 “10번까지 잘 받았다” 라는 의미였다. 하지만 TCP에서는 ACK 10의 의미는 “9까지 잘 받았고 다음 10번을 받을 차례다” 라는 의미다. 그래서 그림에서 호스트 A에 보이는 Seq # = 42, ACK = 79라는 의미는 Send Buffer이 있는 C의 Byte번호가 42라는 뜻이고, Receive Buffer에 78번까지 잘 받았으니 79을 받아야한다는 뜻이다.
- A의 ACK = 79였으므로 (78까지 받았고 79 필요함) B가 응답할 Sequence #는 79번이다. B의 ACK = 43 이었으므로 (42까지 받았고 43필요함) 다음에 A가 응답하는 Sequenc # 는 43번이다.
*Advanced A의 응답에 대해 ACK를 보내고 B가 보낼때 Data보내고 이런방식인데 그냥 한번에 데이터보낼때 응답도 한번에 보내면 안되는가? -> 바로 ACK하지 않고 기다릴 Time을 설정하도록 권고한다 (500ms정도 기다리고 ACK를 보내라)
- 이유 1 : 내가 보내는 데이터가 생길 수 있으므로 거기에 같이 ACK를 한번에 보내면 되니까.
- 이유 2 : 실제로 Pipeline방식이기 때문에 데이터가 마구잡이로 들어온다. 그것에 대해 일일이 응답하지 않고 cumulative ACKs로 동작하는게 이득이다. 예를들어 segment 0~99를 보내면 ACK 1, ACK 2, … ACK 100이 아니라 마지막에 ACK 100만 보내면 되기 때문.
Timeout - function of RTT
중간에 Segment가 유실됐을 때 Timer을 통해 탐지한다고 했었다. Timeout Value를 작게 크게할 때 장단점 복습
- 값 작을때 : Recovery 빠르지만 네트워크 오버헤드 줄 수 있음
- 값 클때 : 네트워크 오버헤드 적지만 Recovery 느림.
적절한 Timer 값 설정 방법은?
- 왕복 시간 (Round Trip Time, RTT) 은 데이터 패킷이 대상으로 전송되는 데 걸리는 시간과 해당 패킷에 대한 승인이 원본에서 다시 수신되는 데 걸리는 시간을 더한 것
- RTT값이 각 세그먼트마다 다르다. 각각 지나는 경로가 다르면 RTT값이 다르고, 같은 라우터를 지나는 패킷 경로라 하더라도 Queueing Delay에 따라 값이 바뀔 수 있다.
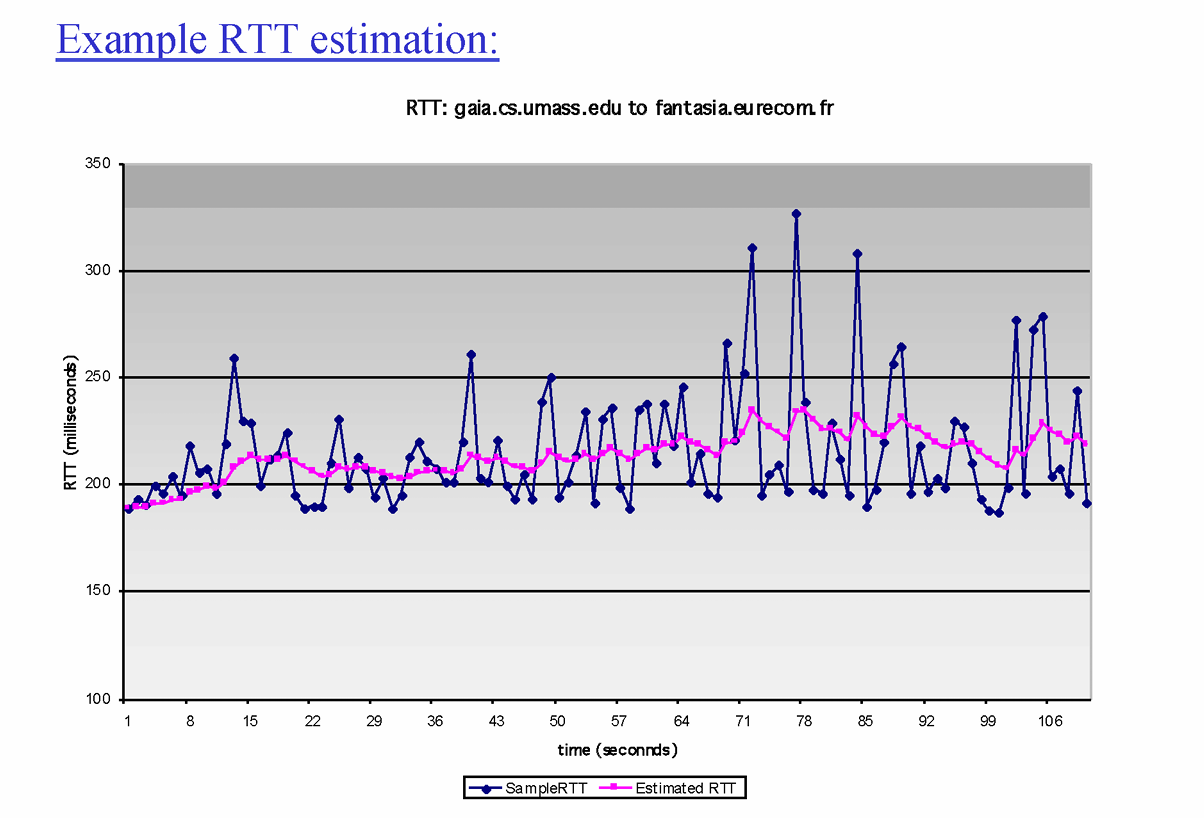 (편차가 매우 큼)
(편차가 매우 큼)

그래서 사용하는 것이 EstimatedRTT
우리가 측정한 SampleRTT값을 사용하면 너무 편차가 크기 때문에 여기 가중치 $α$ 를 곱해 보정해서 사용한다.
실제로 이렇게 Estimated RTT값을 사용해도 괜찮을까?
이렇게 사용해도 위 그래프를 보면 알 수 있듯 튀는 Peak들이 있고, 실제 유실이 일어나지 않아도 timeout이 발생한다. Timeout이라는 것은 유실이 확실시 되었을때만 발생해야하는 엄격한 조건이기 때문에 마진을 붙였다.
아래 식에서 볼 수 있듯 Estimated RTT 에 4 * DevRTT라는 마진을 붙여 보정해서 사용한다. 
Reliable Data Transfer
- Pipeline 방식
- Cumulative ACKs (ACK 10 이면 9까지 잘 받았고 10을 받아야한다는 뜻!)
- Timer 1개 사용 -> Go-Back-N과 유사함
- GBN에서는 Timeout된 Window크기 버퍼 전체 재전송이지만 TCP는 그 세그먼트 하나만 재전송.
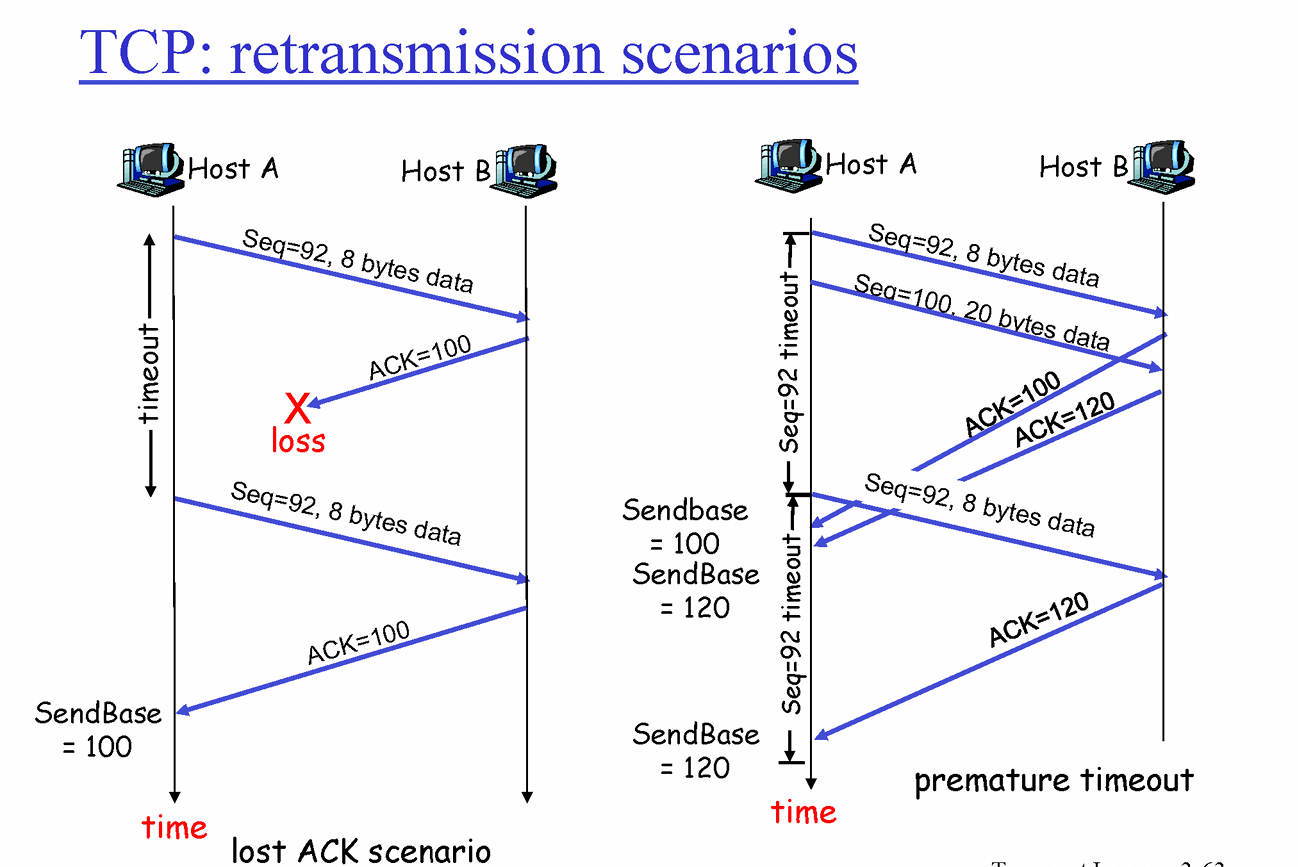
Case 1) Lost ACK
- A가 8Byte짜리 데이터로 Sequence # 92 세그먼트를 보낸다. ( 92~99 )
- B에서 92~99번을 받고 100번 기다리므로 ACK 100을 보낸다.
- ACK가 유실되었으므로 A는 ACK를 받지 못했고 다시 92번과 데이터를 보낸다.
- B는 ACK 100을 다시 보낸다.
Case 2) Premature Timeout
- A가 8Byte짜리 데이터로 Sequence # 92인 세그먼트를 보낸다. ( 92~99 )
- A가 추가로 다음데이터 20Byte짜리 Sequence # 100인 세그먼트를 보낸다 ( 100~119 )
- B는 잘 받았기 때문에 먼저 ACK 100을 보내고 다음으로 ACK 120을 보낸다.
- 모종의 네트워크 이슈로 ACK가 A에 너무 늦게 도착하는 상황이다. 즉, ACK가 도착하기 전에 Time out이 발생.
- A가 ACK 100을 받지 못했으므로, 다시 처음과 같은 8Byte짜리 데이터로 Sequence # 92인 세그먼트를 재전송한다. ( 92~99 )
- B는 ACK 120을 보냈으므로 재전송한 Sequence# 92 는 버린다.
- 원하는 데이터를 받지 못한 B는 다시 필요한 걸 받기위해 ACK 120을 재전송한다.
- 재전송한 후 ACK 100을 받는다.
- 여기서 재전송한 ACK를 받은 A는 Sequence# 92를 재전송한 상황이기에 ( Sequence# 92에 해당하는 Timeout만 터짐. 타이머 하나임 ) ACK 120을 보고 이 타임아웃은 해결되었음을 알게됨( ACK 100아니므로 ). 타임아웃을 초기화하여 종료함.
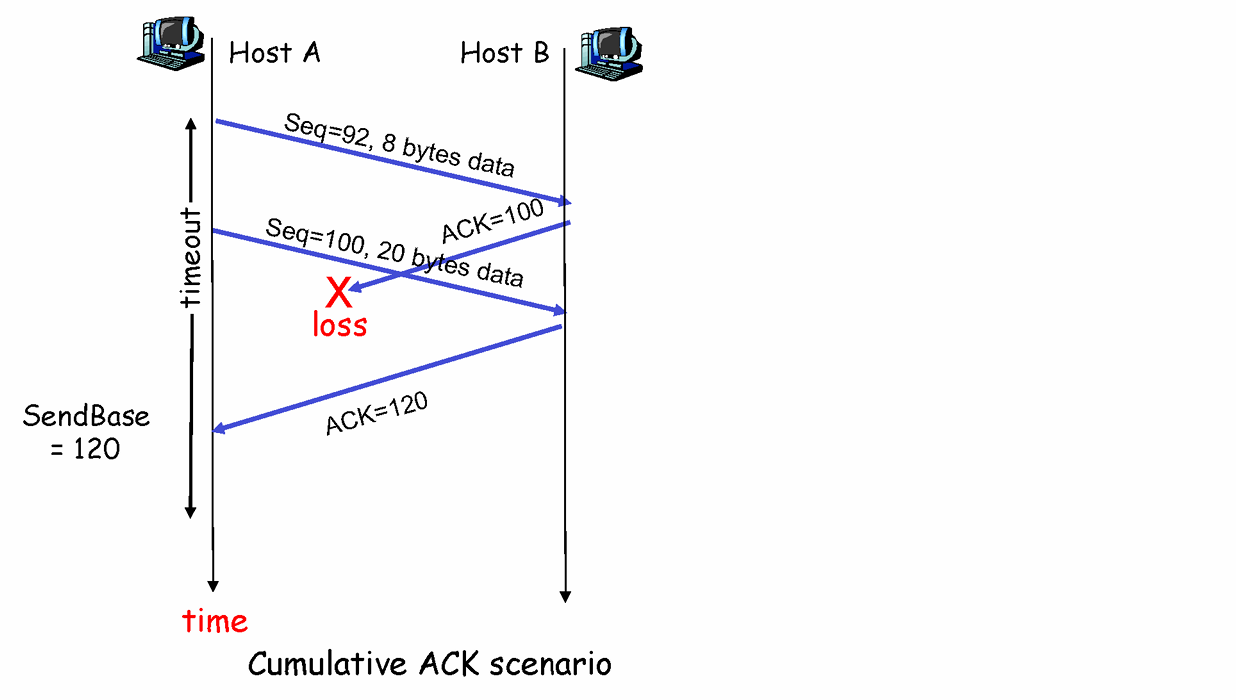
Case 3) Cumulative ACK
- A가 8Byte짜리 데이터로 Sequence # 92인 세그먼트를 보낸다. ( 92~99 )
- A가 추가로 다음데이터 20Byte짜리 Sequence # 100인 세그먼트를 보낸다 ( 100~119 )
- B는 잘 받았기 때문에 먼저 ACK 100을 보내고 다음으로 ACK 120을 보낸다.
- ACK 100은 유실되었고, ACK 120은 잘 보내진 상황이다.
- 데이터 순서가 Sequence# 92, Sequence# 100이고, 앞선 데이터의 ACK 100은 받지 못했지만 뒤쪽 ACK 120은 잘 받았기 때문에 “119번까지 잘 받았고 120번을 주면 되겠구나!” 라고 생각함.
-
문제 없다고 판단하고 정상 진행됨. (Cumulative ACK의 장점이다. 마지막 ACK 하나만 잘 받으면 된다!)
TCP가 좀 더 스마트 하려면?
RTT보정하기위해 더해준 마진 4 * DevRTT는 꽤나 넉넉한 값이다. 즉, Timeout이 생기기까지 시간이 매우 널널한 편. 그래서 0번부터 99번까지 보냈는데 10번에서 유실되었다고 가정해보자. 사실 타이머는 이 100개가 도착하기에 충분한 값이기 때문에 다시 ACK를 받고 재전송하기까지 너무 오래 기다려야한다. **타이머 시간이 너무 길기 때문에 비효율적인 상황이 발생할 수 있다. **
타이머가 터지기 전에 패킷 유실을 판단할 수 있다.
위의 상황을 다시 생각해보자. 0 ~ 99번까지 100개를 한번에 보냈고 10번이 유실되었다.
- B에게 0부터 9번까지 유실없이 잘 전달되었으므로 A에서는 달라고 하는 번호인 ACK 1, ACK 2, … ACK 8, ACK 10까지 다시 잘 받는다.
- A에서 10을 보내다가 유실되었다.
- 받지못한 B에서 Receiver는 반드시 ACK는 보내줘야 하므로 ACK 10을 보낸다. (10 필요해 보내줘)
- Receiver에서는 버퍼에 10번 자리만 비워놓고 11, 12, 13, … 이렇게 쌓여간다.
- A는 계속 11, 12, 13, … 을 보내며 Timeout발생하기 전까지 진행한다.
- A가 이렇게 진행해도 B에서 응답하는 ACK는 필요한 것의 번호이기 때문에 ACK 10, ACK 10, ACK 10, … 이다.
같은 Duplicate ACK가 여러번 오는 상황이 발생하고, 이것을 “중간에 10이 유실되었구나” 라고 해석할 수 있다.
이를 Fast Retransmit 라고 한다.
권고 사항으로 Duplicate ACK가 3번 반복되면 ( 총 같은 ACK를 4번 받으면! ) 타이머에 관계없이 재전송하라고 권장한다.
Fast Retransmit은 없어도 문제되지 않는 메커니즘이다. 다만, 최적화를 위한 권고 사항이다.