Computer Science Note - Database

본 게시글의 그림들은 참고 레퍼런스들을 토대로 직접 그렸음을 미리 밝힙니다.
Database
1. 데이터베이스의 기본
1-1. 엔티티
- 사람, 장소, 물건 등 여러개의 속성을 지닌 명사를 의미
- ex) 회원이라는 엔티티 -> 속성 : 이름, 아이디, 주소, 전화번호를 속성으로 가짐 서비스의 요구사항에 맞춰 속성이 정해짐
약한 엔티티와 강한 엔티티
- A가 혼자서는 존재하지 못하고 B의 존재 여부에 따라 종속적일 때
- 강한 엔티티 : B
- 약한 엔티티 : A
1-2. 릴레이션
- 데이터베이스에서 정보를 구분하여 저장하는 기본 단위
- 엔티티에 관한 데이터를 릴레이션 하나에 담아서 관리함
- RDBS에서는 “테이블” 이라고 부름
- NoSQL에서는 “컬렉션” 이라고 부름
테이블과 컬렉션
- 관계형 데이터베이스 (MySQL) : 레코드 - 테이블 - 데이터베이스
- NoSQL 데이터베이스 (MongoDB) : 도큐먼트 - 컬렉션 - 데이터베이스
1-3. 속성 (attribute)
- 릴레이션에서 관리하는 구체적이며 고유한 이름 갖는 정보
1-4. 도메인 (Domain)
- 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합
- ex) 속성 : 성별 -> 도메인(값) : 남, 여
1-5. 필드와 레코드
회원이라는 테이블로 설명해보자.
- 회원이란 엔티티는 member라는 테이블
- 속성이 이름, 아이디 등이 있으면 필드로 name, ID 등
- 테이블에 쌓이는 행(row)로 Alex, Kguswo가 들어가는데 이걸 레코드(= 튜플) 라고 한다
필드 타입
숫자 타입
| 타입 | 용량(바이트) | 최솟값(부호있음) | 최댓값(부호있음) | 최솟값(부호없음) | 최댓값(부호없음) | |——|————|—————-|—————-|—————-|—————-| | TINYINT | 1 | -128 | 127 | 0 | 255 | | SMALLINT | 2 | -32,768 | 32,767 | 0 | 65,535 | | MEDIUMINT | 3 | -8,388,608 | 8,388,607 | 0 | 16,777,215 | | INT | 4 | -2,147,483,648 | 2,147,483,647 | 0 | 4,294,967,295 | | BIGINT | 8 | -263 | 263-1 | 0 | 264-1 |
날짜 타입
- DATE
- 날짜 부분만 있고 시간 부분은 없음
- 지원범위 :
1000-01-01~9999-12-31 - 3 바이트
- DATETIME
- 날짜 + 시간
- 지원 범위 :
1000-01-01 00:00:00~9999-12-31 23:59:59 - 8 바이트
- TIMESTAMP
- 날짜 + 시간
- 지원 범위 :
1970-01-01 00:00:01~2038-01-19 03:14:07 - 4 바이트
문자 타입
- CHAR
- 고정 길이 문자열, 길이 : 0 ~ 255
- 레코드를 저장할 때 무조건 선언한 길이 값으로 “고정”해서 저장
- 수를 입력해서 몇 자까지 입력할지 정함. ex) CHAR(30) : 최대 30글자
- ex) CHAR(100) 선언 후 10글자 저장해도 100바이트로 저장
- VARCHAR
- 가변 길이 문자열, 길이 : 0 ~ 255
- 입력한 데이터에 따라 용량을 가변시켜 저장
- ex) 10글자의 이메일을 저장할 경우 VARCHAR(1000)이라고 선언했어도 10글자에 해당하는 바이트 + 길이 기록용 1 바이트로 저장
- TEXT
- 큰 문자열 저장할 때 사용
- 게시판의 본문 저장할 때
- BLOB
- 이미지, 동영상 등 큰 데이터 저장할 때 사용
- 하지만 AWS S3 이용하는 등 서버에 파일 올리고 파일에 관한 경로를 VARCHAR 로 저장하는게 일반적임
- ENUM
- ENUM(‘x-small’, ‘small’, ‘medium’, ‘large’, ‘x-large’) 형태로 쓰임, 이 중에서 하나만 선택하는 단일 선택만 가능.
- ENUM 리스트에 없는 잘못된 값을 삽입하면 빈 문자열이 대신 삽입됨
- 장점 : ENUM 사용시 x-small 등이 0, 1 등으로 매핑되어 메모리 적게 사용
- 최대 65535개의 요소 넣을 수 있음
- SET
- ENUM과 비슷하지만 여러개의 데이터 선택할 수 있음.
- 비트 단위의 연산을 할 수 있음
- 최대 64개의 요소 넣을 수 있음
ENUM이나 SET 사용시 공간적으로 이점을 볼 수 있지만 애플리케이션 수정에 따라 데이터베이스의 ENUM or SET에 정의한 목록을 수정해야 한다는 단점이 있다.
1-6 관계
DB에는 여러개의 테이블이있고 테이블간의 관계가 있다
1:1 관계
유저 - 유저이메일 테이블에서 유저당 이메일은 한개씩 있다. 이 경우 1:1 관계다. 1:1 관계는 테이블을 2개의 테이블로 나눠 구조를 더 이해하기 쉽게 만들어준다.
1:N 관계
쇼핑몰의 경우 한 유저당 여러 상품을 장바구니에 넣을 수 있다. 이 경우 1:N 관계다. 하나도 넣지 않을수도 있으니 0도 포함된다.
N:M 관계
학생과 강의의 관계에서 한 학생이 여러 강의 들을 수 있고 한 강의도 여러 학생을 포함할 수 있다. 이 경우 N:M 관계다. N:M 관계는 테이블 2개를 직접 연결하지 않고 중간에 1:N, 1:M 관계를 갖는 테이블 2개로 나눠서 중간에 학생_강의 테이블을 둔다(학생 ID, 강의 ID).
1-7 키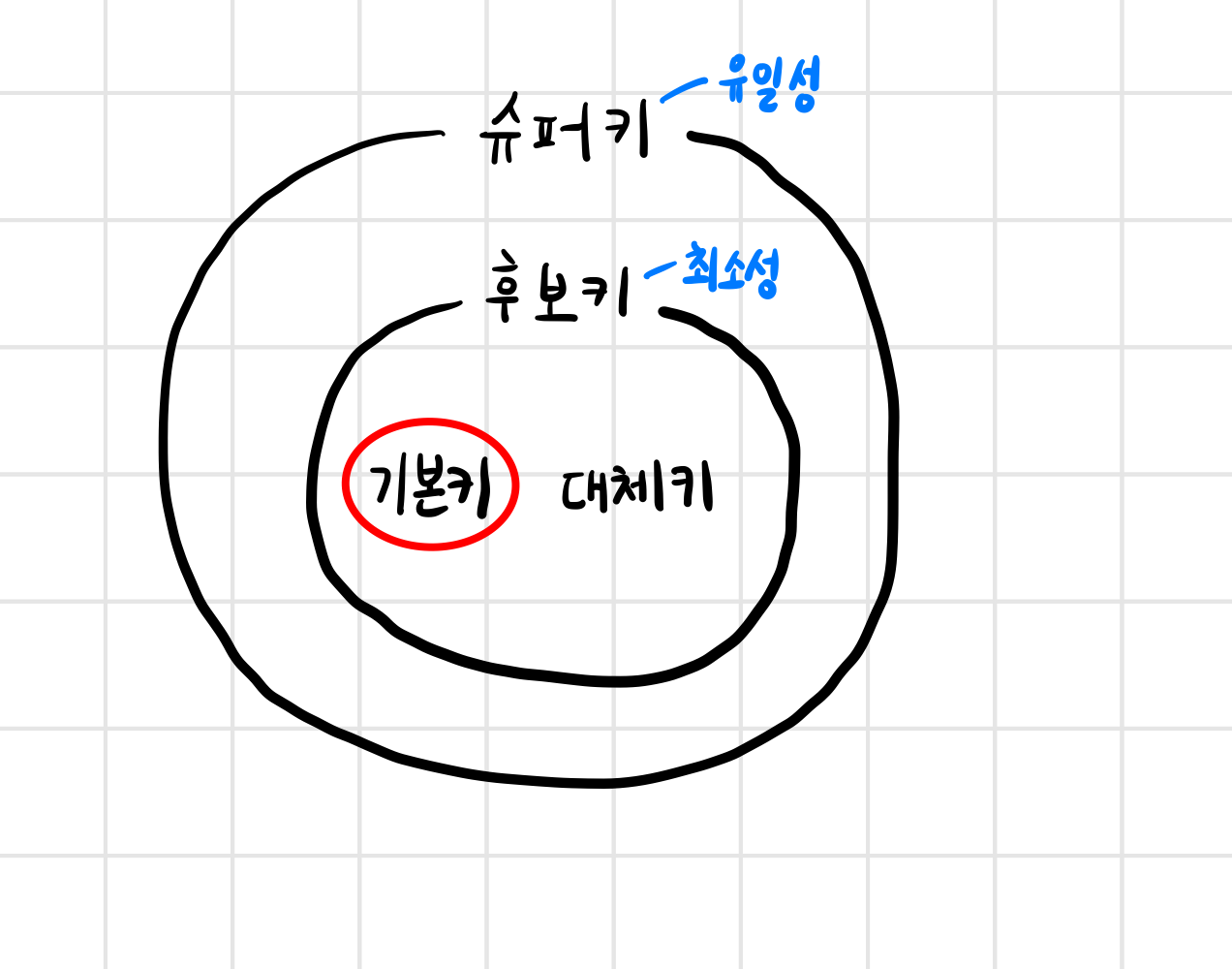
- 슈퍼키 : 유일성이 있다 ( 중복값 없음 )
- 후보키 : 최소성을 갖춘 키 ( 필드 조합없이 최소 필드만 써서 키 형성가능)
- 기본키 : 기본키로 선택된 키
- 대체키 : 기본키로 선택되지 못한 키
- 후보키 : 최소성을 갖춘 키 ( 필드 조합없이 최소 필드만 써서 키 형성가능)
기본키 (Primary Key)
- 유일성과 최소성을 만족하는 키
- 테이블의 데이터 중 고유하게 존재하는 속성이며, 기본키에 해당하는 데이터는 중복되어서는 안된다.
자연키
- 중복되지 않는 것을 “자연스럽게” 뽑다가 나오는 키
- 언젠가는 변하는 속성
- ex) 유저테이블에서 주민등록번호, 이름, 성별 등이 있을 때 중복된 값으로 이름, 성별은 제외하면 주민등록번호가 자연스레 남는다. 자연키는 주민등록번호가 된다.
인조키
- 인위적으로 ID를 부여 -> 고유 식별자가 생김
- Oracle은 sequence, MySQL은 auto increment등으로 설정
- 자연키와는 달리 변하지 않으므로 보통 기본키는 인조키
외래키 (Foreign Key)
- 다른 테이블의 기본키를 그대로 참조하는 값으로 개체와의 관계를 식별하는데 사용
- 외래키는 중복되어도 괜찮다.
후보키 (candidate key)
- 기본키가 될 수 있는 후보들
- 유일성과 최소성을 만족
슈퍼키 (super key)
- 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키
2. ERD 정규화 과정
ERD(Entity Relationship Diagram)는 릴레이션 간의 관계를 정의한 것이다.
2-1. ERD의 중요성
- 시스템 요구사항을 기반으로 작성됨, 이를 기반으로 DB 구축
- 이후 디버깅 or 비즈니스 프로세스 재설계시 설게도 역할도 함
- *비정형 데이터는 충분히 표현할 수 없다.
*비정형 데이터 : 비구조화 데이터, 미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보
2-2. 정규화 과정
릴레이션 간의 잘못된 종속관계로 인해 데이터베이스 이상현상 생겨서 이를 해결하거나, 저장공간 효율적으로 사용하기 위해 릴레이션 여러개로 분리하는 과정
정규형 원칙
- 같은 의미를 표현하는 릴레이션이지만 좀 더 좋은 구조로 만들어야 함
- 자료의 중복성은 감소해야 함
- 독립적인 관계는 별개의 릴레이션으로 표현해야함
- 각각의 릴레이션은 독립적인 표현이 가능해야 함
제1정규형
- 릴레이션의 모든 도메인이 더이상 분해될 수 없는 원자값만으로 구성되어야 한다
- 릴레이션의 속성 값 중 한개의 기본키에 대해 두 개 이상의 값을 가지는 반복 집합이 있어서는 안된다
제2정규형
- 릴레이션이 제 1 정규형이며 부분 함수의 종속성을 제거한 형태
- 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속적인 것
- 릴레이션을 분해할 때 동등한 릴레이션으로 분해해야하고, 정보 손실이 발생하지 않는 무손실 분해여야한다
제3정규형
- 제2정규형이고 기본키가 아닌 모든 속성이 이행적 함수 종속을 만족하지 않는 상태
이행적 함수 종속 : A->B 와 B->C 가 존재하면 논리적으로 A->C가 성립하는데 이때 집합 C가 집합 A에 이행적으로 함수 종속이다.
보이스/코드 정규형
3. 트랜잭션과 무결성
3-1. 트랜잭션
- 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위
- 여러개의 쿼리를 하나로 묶는 단위
- ACID : 원자성, 일관성, 독립성, 지속성
(1) 원자성
- 트랜잭션과 관련된 이리 모두 수행되었거나 되지 않았거나를 보장하는 특징
- “all or nothing”
커밋과 롤백
- 커밋(commit) : 여러 쿼리가 성공적으로 처리되었다고 확정하는 명령어
트랜잭션 단위로 수행되며 변경된 내용이 모두 영구적으로 저장됨
- ex) 커밋 시작 (update-insert-delete) 커밋 종료 로 하나의 트랜잭션 단위로 수행되고 이후 데이터베이스에 영구 저장됨
Q. 하지만 에러나 여러 이슈 때문에 트랜잭션 전으로 돌려야 한다면? A : 롤백!
- 롤백이란 트랜잭션으로 처리한 하나의 묶음 과정을 일어나기 전으로 돌리는 일.
- 커밋과 롤백 덕분에 데이터의 무결성이 보장된다.
트랜잭션 전파
- 트랜잭션 수행시 커넥션 단위로 수행하기 때문에 커넥션 객체를 넘겨서 수행해야함, 하지만 매번 넘기기 어렵고 귀찮음
- 이를 넘겨서 수행하지 않고 여러 트랜잭션 관련 메서드의 호출을 하나의 트랜잭션에 묶이도록 하는 것을 트랜잭션 전파라고 한다.
- ex) Spring에서의 @Transactional
(2) 일관성
- “허용된 방식”으로만 데이터를 변경해야 하는 것을 의미
- 데이터베이스에 기록된 모든 데이터는 여러 조건, 규칙에 따라 유효함을 가짐
- ex) 자금 100만원인 사람이 200만원을 빌려줄 수 없음.
(3) 격리성
- 트랜잭션 수행 시 서로 끼어들지 못하는 것
- 복수의 병렬 트랜잭션은 서로 격리되어 마치 순차적으로 실행되는 것처럼 작동되어야함
- 데이터베이스는 여러 사용자가 같은 데이터에 접근할 수 있어야함
- 쉽게 생각하면 트랜잭션 순차적으로 실행하면 되는데 이는 성능 저하를 일으킴!
- => 격리성은 여러개의 격리 수준으로 나뉘어 격리성을 보장
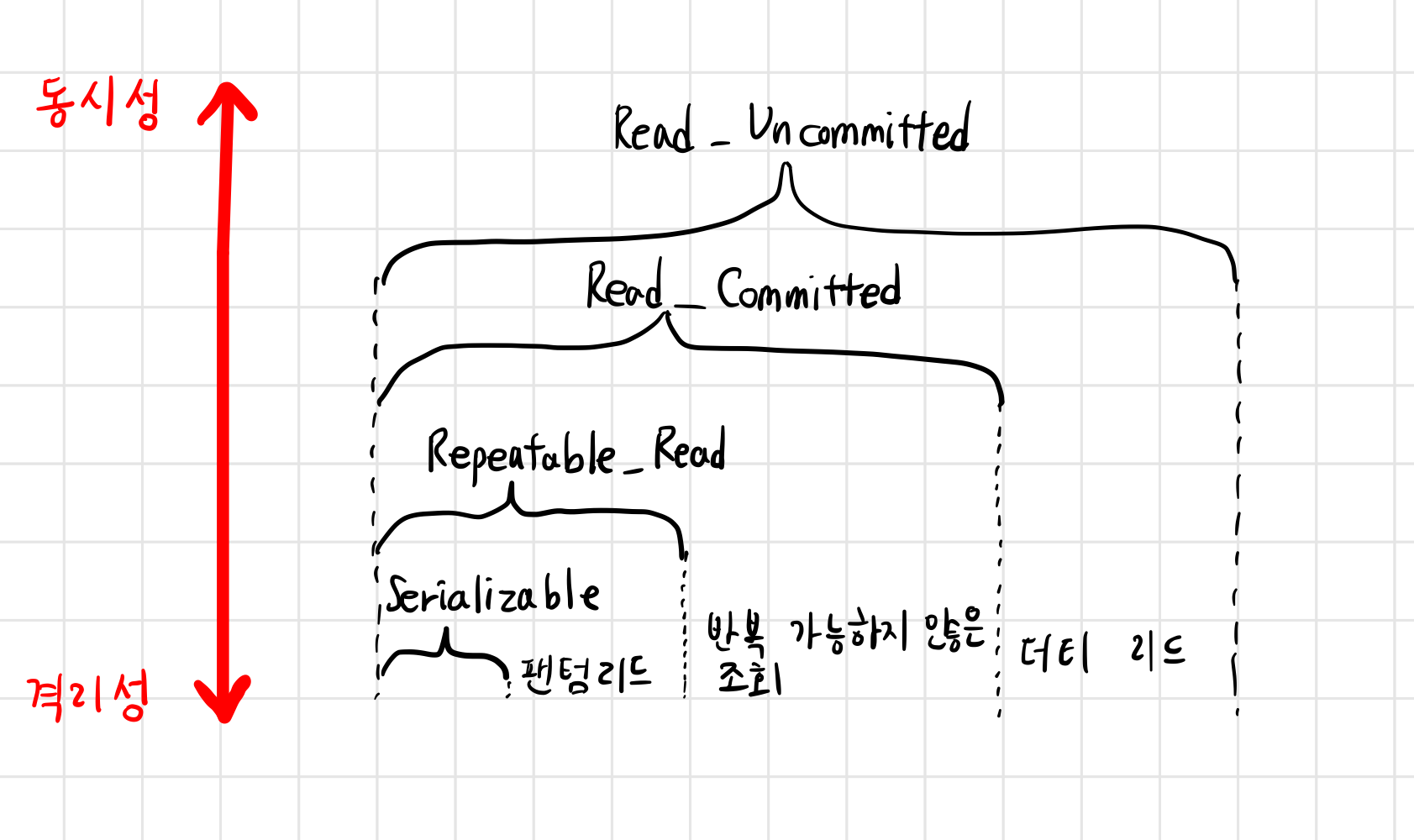
- 격리 수준은 SERIALIZABLE, REPEATABLE_READ, READ_COMMITTED, READ_UNCOMMITTED가 있으며 위로 갈수록 동시성이 강하지만 격리성은 약해짐
격리 수준에 따라 발생하는 현상
- 팬텀 리드
- 한 트랜잭션 내에서 동일한 쿼리 보냈을 때 해당 조회 결과가 다른 경우
- ex) 10살 이상인 회원 조회 쿼리 보낸 후 결과가 3명일 때, 15살인 회원 추가시 4개가 조회되는 것
- 반복 가능하지 않은 조회
- 한 트랜잭션 내의 같은 행에 두 번 이상 조회가 발생했는데, 그 값이 다른 경우
- ex) A의 자금이 100만원이라고 조회했는데 이후 B가 그 값을 0으로 변경해서 커밋하면 이후 A는 0을 조회하게 된다.
- 팬텀 리드와 다른 점은 반복 가능하지 않은 조회는 행 값이 달라질 수 있는데, 팬텀 리드는 다른 행이 선택될 수도 있다는 점.
- 더티 리드
- 반복가능하지 않은 조회와 유사함
- 한 트랜잭션이 실행중일 때 다른 트랜잭션에 의해 수정되었지만 아직 “커밋되지 않은” 행의 데이터를 읽을 수 있을 때 발생
- ex) A의 자금이 100만원이라고 조회했는데 이후 B가 그 값을 0으로 변경했고 이를 커밋하기 전에도 조회하면 0을 조회하게 된다.
격리 수준
- SERIALIZABLE
- 트랜잭션을 순차적으로 진행시키는 것
- 여러 트랜잭션이 동시에 같은 행에 접근 불가, 기다려야함
- 교착상태 일어날 확률도 많고, 가장 성능이 떨어지는 격리 수준
- REPEATABLE_READ
- 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막아주지만 새로운 행을 추가하는 것은 막지 않는다.
- READ_COMMITTED
- 가장 많이 사용되는 격리 수준
- 트랜잭션이 커밋하지 않은 정보는 읽을 수 없다. 즉 커밋 완료된 데이터에 대해서만 조회를 허용
- 하지만 어떤 트랜잭션이 접근한
- READ_UNCOMMITTED
- 가장 낮은 격리 수준
- 하나의 트랜잭션이 커밋되기 전에 다른 트랜잭션에 노출되는 문제가 있지만 가장 빠름
- 거대한 양의 데이터를 “어림잡아” 집계할 때 사용하면 좋음
(4) 지속성
- 성공적으로 수행된 트랜잭션은 영원히 반영되어야함
- 데이터베이스에 시스템 장애 생겨도 원래 상태로 복구 가능.
- checksum, 저널링, 롤백 등의 기능 제공
저널링 : 파일 시스템 또는 데이터베이스 시스템에 변경 사항을 커밋하기 전에 로깅하는것, 트랜잭션 등 변경 사항에 대한 로그 남기는것
3-2. 무결성
- 데이터의 정확성, 일관성, 유효성을 유지하는 것, 무결성이 유지되어야 데이터베이스 저장된 데이터 값과 그 값에 해당하는 현실 세계의 실제 값이 일치하는 신뢰가 생김
무결성의 종류
- 개체 무결성 : 기본키로 선택된 필드는 빈 값을 허용하지 않음
- 참조 무결성 : 서로 참조 관계에 있는 두 테이블의 데이터는 항상 일관된 값을 유지
- 고유 무결성 : 특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우 그 속성값은 모두 고유값을 가짐
- NULL 무결성 : 특정 속성값에 NULL이 올 수 없다는 조건이 주어진 경우 그 속성 값은 NULL이 될 수 없다는 제약 조건
4. 데이터베이스 종류
4-1. 관계형 데이터베이스
- 행과열을 가지는 표 형식 데이터를 저장하는 형태의 데이터베이스
- SQL이라는 언어로 조작
- MySQL, PostgreSQL, 오라클, SQL Server, MSSQL 등
MySQL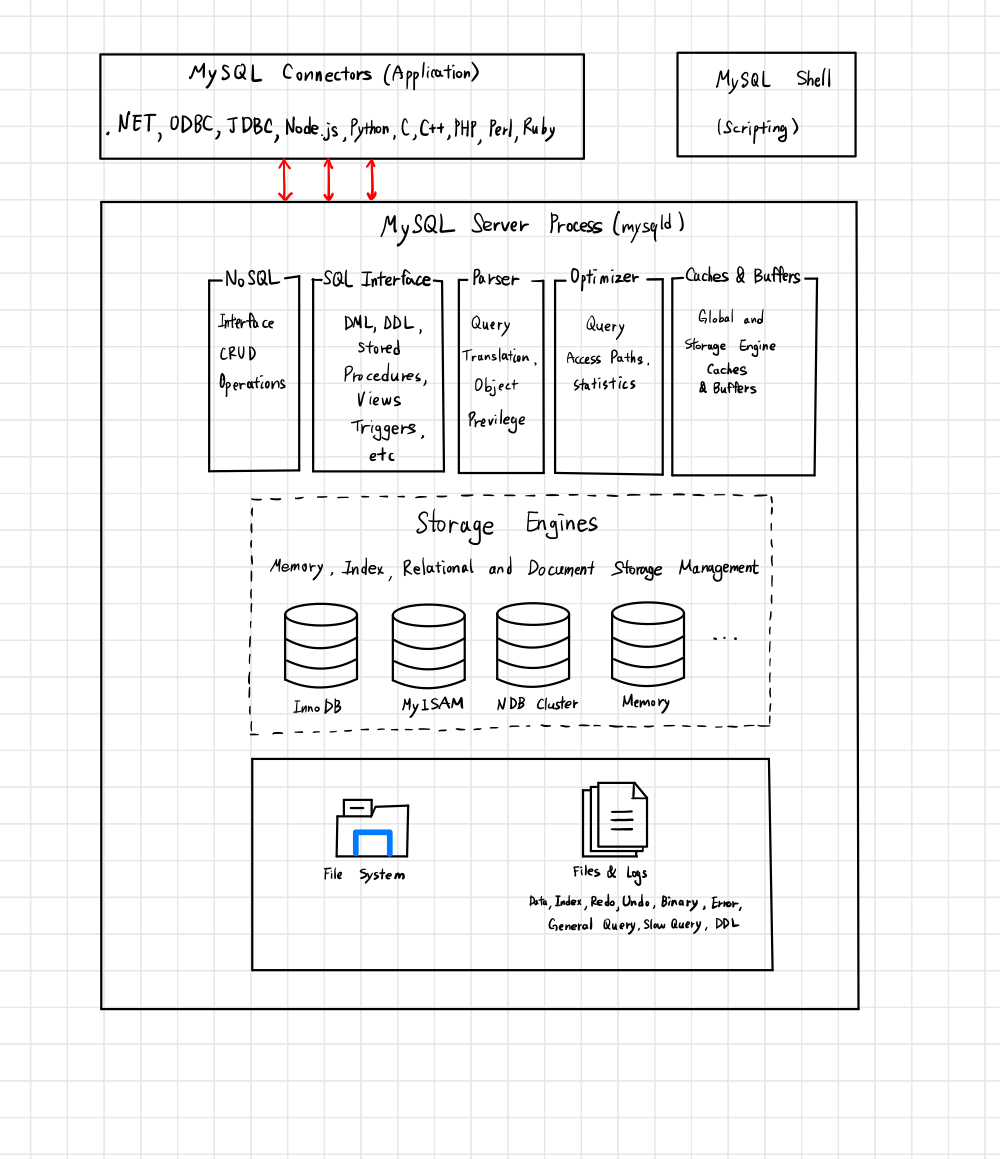
- 스토리지 엔진은 데이터베이스의 심장이다, 모듈식 아키텍쳐로 쉽게 스토리지 엔진을 바꿀 수 있으며 데이터 워어하우징, 트랜잭션 처리, 고가용성 처리가 장점이다.
- 스토리지 엔진 위에는 커넥터API 및 서비스계층을 통해 MySQL DB랑 쉽게 상호작용
PostgreSQL
- VACUUM : 디스크 조각이 차지하는 영역을 회수할 수 있는 장치
- 최대 테이블 크기 : 32TB
- SQL 뿐만 아니라 JSON을 이용해서 데이터 접근 가능
- 지정 시간에 복구하는 기능, 로깅, 접근제어, 중첩된 트랜잭션, 백업 등 가능
4-2. NoSQL 데이터베이스
- Not Only SQL; SQL을 사용하지 않는 데이터베이스. ex) MongoDB, redis
MongoDB
- JSON을 통해 데이터 접근 가능.
- Binary JSON(BSON) 형태로 데이터가 저장됨.
- 와이어드타이거 엔진이 기본 스토리지 엔진으로 장착된 키-값 데이터 모델에서 확장된 도큐먼트 기반의 DB다.
- 장점 : 확장성 뛰어남, 빅데이터를 저장할 때 성능 좋음, 고가용성, 샤딩, 레플리카셋 지원, 스키마 정해놓지 않고 데이터 삽입할 수 있기 때문에 다양한 도메인의 데이터베이스를 기반으로 분석 or 로깅 구현할 때 좋음
- 도큐먼트 생성할 때마다 다른 컬렉션에서 중복된 값을 지니기 힘든 유티크한 값인 ObjectID가 생성된다
Redis
- 인메모리 데이터베이스. 키-값 데이터 모델 기반
- 기본적인 데이터 타입 : 문자열(String), 최대 512MB 저장가능
- 그 외 set, hash 지원
- pub/sub 기능을 통해 채팅 시스템, 다른 DB앞단에 두어 사용하는 캐싱 계층, 단순한 키-값이 필요한 세션 정보 관리, 정렬된 set (sorted-set) 자료구로 이용한 실시간 순위표 서비스 등에 사용됨
5. 인덱스
5-1. 인덱스의 필요성
- 데이터 빠르게 찾을 수 있는 하나의 장치. ex) 책 마지막 장에 있는 찾아보기와 같다.
5-2. B-트리
- 루트 노드, 리프 노드, 브랜치 노드로 나뉨
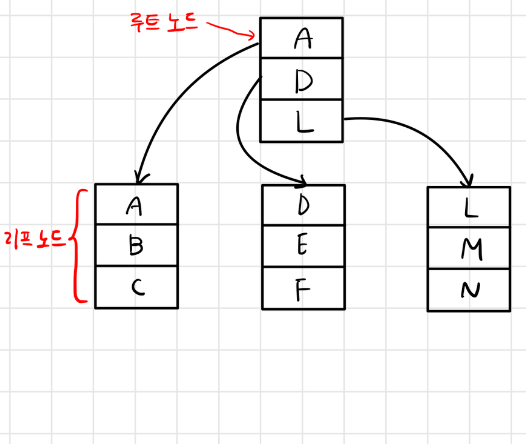
- E를 찾는다고 하면 전체 테이블을 탐색하는 것이 아니라 E가 있을법한 리프노드로 가서 E를 탐색하기 때문에 더 빠르게 탐색 가능하다.
자세한 예시로 57을 찾는 과정을 보자.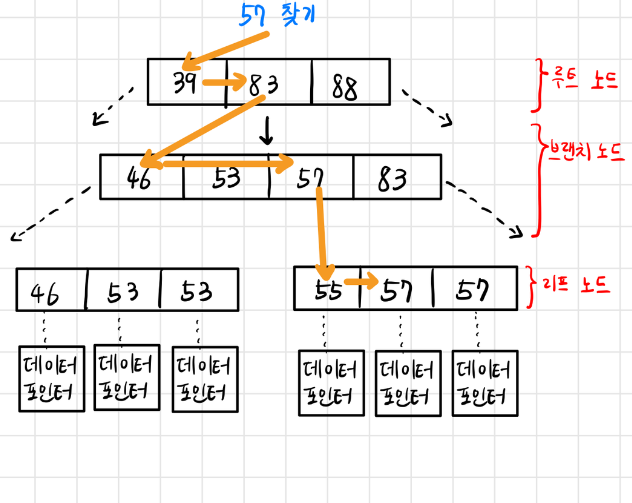
맨 위 루트노드부터 탐색한다. 그 후 브랜치 노드를 거쳐 리프노드까지 내려온다. “57보다 같거나 클 때 까지 <=” 를 기반으로 정렬된 값을 기반으로 탐색한다. 마지막 리프노드 도달시 57이 가리키는 데이터 포인터를 통해 결괏값을 반환한다.
인덱스가 효율적인 이유와 대수확장성
- 효율적인 이유 : 효율적인 단계를 거쳐 모든 요소에 접근할 수 있는 균형잡힌 트리 구조와 깊이의 대수확장성 때문
대수확장성 : 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장. 기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목수는 4배씩 증가.
5-3. 인덱스 만드는 방법
MySQL
- 클러스터형 인덱스
- 테이블당 하나 설정
- primary key 옵션으로 기본키로 만듬
- 기본키로 반들지 않고 unique not null 옵션 붙여도 가능
- 세컨더리 인덱스
- 보조 인덱스로 여러개의 필드 값을 기반으로 쿼리를 많이 보낼 때 생성해야함
- create index … 명령어로 만들 수 있음
-> 하나의 인덱스만 생성할 것이라면 클러스터형 인덱스를 만드는 것이 세컨더리 인덱스보다 성능 좋다. ex) name이라는 필드만으로 쿼리 보낸다면 클러스터형 인덱스, name, age, email 등 다양한 필드 기반으로 쿼리 보낸다면 세컨더리 인덱스
MongoDB
- 도큐먼트 생성시 자동으로 ObjectID 형성되고 해당 키가 기본키로 설정됨
- 세컨더리 키도 부가적으로 설정해서 기본키와 세컨더리 키 같이 쓰는 복합 인덱스 사용 가능
5-4. 인덱스 최적화 기법 (MongoDB 기준)
1. 인덱스는 비용이다
- 인덱스는 두 번 탐색하도록 강요한다. 인덱스 리스트, 그다음 컬렉션 순으로 탐색하기 때문에 읽기 비용 발생.
- 또한 컬렉션 수정되었을 때 인덱스도 수정되어야한다. 이때 B-트리의 높이를 균형있게 조절하는 비용도 들고, 데이터를 효율적으로 조회할 수 있게 분산시키는 비용도 든다.
따라서 모든 필드에 인덱스 설정하는 것은 좋지 않고, 컬렉션에서 가져올 양 많을수록 인덱스 사용이 비효율적이다.
2. 항상 테스팅하라
- 서비스 특징에 따라 인덱스 최적화 기법이 다른데 서비스에서 사용하는 객체의 깊이, 테이블의 양이 다르기 때문이다.
explain()함수를 통해 인덱스를 만들고, 쿼리 보낸 후 테스팅하며 걸리는 시간을 최소화해야한다.
MySQL 테스팅코드
1
2
3
EXPLAIN
SELECT * FROM t1
JOIN t2 ON t1.c1 = t2.c1
3. 복합 인덱스는 같음, 정렬, 다중 값, 카디널리티 순이다
- 여러 필드 기반 조회시 복합 인덱스 생성하는데, 이 인덱스 생성할때 순서가 있고 생성 순서에 따라 인덱스 성능도 달라진다.
-
같음 > 정렬 > 다중 값 > 카디널리티 순으로 생성해야한다.
6. 조인의 종류
- 조인 : 두 개 이상의 테이블을 묶어서 하나의 결과물을 만드는 것
- MySQL : JOIN
- MongoDB : lookup
- lookup은 되도록 사용하지 말자. MongoDB는 조인연산에 대해 관계형 데이터베이스보다 성능이 덜어진다고 여러 벤치마크 테스트를 통해 알려진 바 있다.
따라서 조인이 많은 경우 RDBS를 사용하자.
**조인의 종류
- 내부조인 (Inner Join) : 왼쪽 테이블과 오른쪽 테이블 두 행이 모두 일치하는 행 표기
- 왼쪽 조인 (Left Outer Join) : 왼쪽 테이블의 모든 행이 표기
- 오른쪽 조인 (Right Outer Join) : 오른쪽 테이블의 모든 행이 표기
- 합집합 조인 (Full Outer Join) : 두 개의 테이블을 기반으로 조인 조건에 만족하지 않는 행까지 모두 표기
6-1. 내부조인 (Inner Join)
1
2
3
SELECT * FROM TableA A
INNER JOIN TableB B
ON A.key = B.key
6-2. 왼쪽 조인 (Left Outer Join)
1
2
3
SELECT * FROM Table A A
LEFT JOIN TableB B
ON A.key = B.key
6-3. 오른쪽 조인 (Right Outer Join)
1
2
3
SELECT * FROM TableA A
RIGHT JOIN TableB B
ON A.key = B.key
6-4. 합집합 조인 (Full Outer Join)
1
2
3
SELECT * FROM TableA A
FULL OUTER JOIN TableB B
ON A.key = B.key
7. 조인의 원리
7-1. 중첩 루프 조인 (NLJ, Nested Loop Join)
- 중첩 for문과 같은 원리로 조건에 맞는 조인을 하는 방법
- 랜덤 접근에 대한 비용이 많이 증가하므로 대용량 테이블에서 사용 X
- ex) t1, t2테이블 조인한다고 했을때 첫번째 테이블에서 행을 한번에 하나씩 읽고 그 다음 테이블에서도 행을 하나씩 읽어 조건에 맞는 레코드 찾아 결괏값 반환
블록 중첩 루프 조인 (BNL, Block Nested Loop) : 중첩 루프 조인에서 발전한 조인할 테이블을 작은 블록으로 나눠 블록 하나씩 조인하는 방식
7-2. 정렬 병합 조인
- 각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬 끝난 후 조인 작업 수행
- 조인에 쓸 적절한 인덱스가 없고 대용량 테이블들을 조인하고 조인 조건으로 < , > 등 범위 비교 연산자 있을 때 사용
7-3. 해시 조인
- 해시 테이블 기반 조인
- 테이블 2개 조인시 하나의 테이블이 메모리에 온전히 들어간다면 중첩 루프 조인보다 효율적.(메모리에 올릴 수 없을 정도로 크다면 디스크를 사용하는 비용 발생)
- 동등(=) 조인에서만 사용 가능
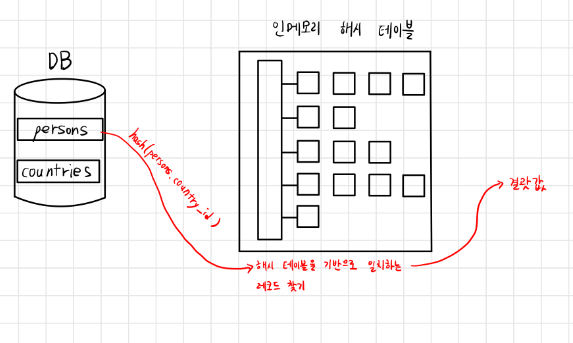
MySQL의 해시 조인 - 빌드단계, 프로브 단계로 나뉨
빌드 단계
- 입력 테이블 중 하나 기반으로 메모리 내 해시 테이블을 빌드하는 단계
- ex) persons와 countries라는 테이블 조인시 둘 중 바이트가 더 작은 테이블 기반으로 테이블을 빌드
- 또한 조인에 사용되는 필드가 해시 테이블의 키로 사용된다. ex) “countries.country_id”가 키로 사용됨
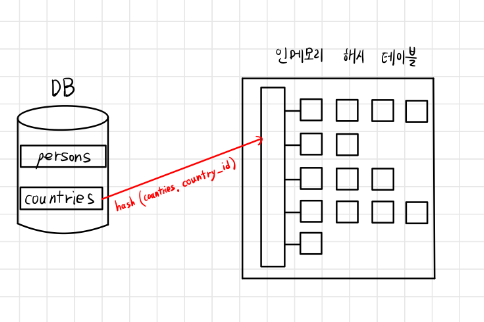
프로브 단계
- 레코드 읽기 시작하며, 각 레코드에서 “persons.country_id”에 일치하는 레코드 찾아서 결괏값으로 반환