[Effective Java] - 비트 필드 대신 EnumSet 을 사용하라

Item 36 : 비트 필드 대신 EnumSet을 사용하라
들어가며
열거 타입을 집합으로 사용해야 할 때가 있다. 예컨대 텍스트 스타일을 표현할 때 굵게, 기울임, 밑줄, 취소선 등 여러 스타일을 동시에 적용할 수 있어야 한다. 과거에는 이런 경우 각 상수에 서로 다른 2의 거듭제곱 값을 할당한 비트 필드(bit field) 방식을 사용했다.
그러나 자바에는 비트 필드보다 훨씬 나은 대안이 있다. 바로 EnumSet 이다. EnumSet은 열거 타입 상수의 값으로 구성된 집합을 효과적으로 표현하며, Set 인터페이스를 완벽히 구현하고, 타입 안전하며, 다른 Set 구현체와도 함께 사용할 수 있다.
이번 아이템에서는 비트 필드의 문제점을 살펴보고, EnumSet이 왜 더 나은 선택인지 깊이 있게 알아본다.
비트 필드의 전통적인 사용법
과거 C 언어 시절부터 사용되던 비트 필드 방식은 다음과 같이 구현된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 구식 기법 - 비트 필드 열거 상수
public class Text {
public static final int STYLE_BOLD = 1 << 0; // 1 (0001)
public static final int STYLE_ITALIC = 1 << 1; // 2 (0010)
public static final int STYLE_UNDERLINE = 1 << 2; // 4 (0100)
public static final int STYLE_STRIKETHROUGH = 1 << 3; // 8 (1000)
// 매개변수 styles는 0개 이상의 STYLE_ 상수를 비트별 OR한 값
public void applyStyles(int styles) {
// 각 비트를 검사하여 스타일 적용
if ((styles & STYLE_BOLD) != 0) {
// 굵게 처리
}
if ((styles & STYLE_ITALIC) != 0) {
// 기울임 처리
}
// ... 나머지 스타일 처리
}
}
이 방식은 다음과 같이 사용한다.
1
2
// 비트별 OR를 사용해 여러 상수를 하나의 집합으로 모은다
text.applyStyles(STYLE_BOLD | STYLE_ITALIC);
비트 필드를 사용하면 비트별 연산을 통해 합집합과 교집합 같은 집합 연산을 효율적으로 수행할 수 있다. 그러나 이 기법은 여러 문제점을 가지고 있다.
비트 필드의 문제점
1. 가독성 문제
비트 필드 값은 정수로 출력되면 단순히 숫자로만 표시되어 해석하기 어렵다.
1
2
3
int styles = STYLE_BOLD | STYLE_ITALIC;
System.out.println(styles); // 출력: 3
// 3이 무엇을 의미하는지 바로 알 수 없다
3 이라는 숫자만 보고는 어떤 스타일이 포함되어 있는지 즉시 파악할 수 없다. 디버깅할 때 비트 필드를 분석하려면 각 비트를 일일이 확인해야 하는 번거로움이 있다.
2. 순회의 어려움
비트 필드에 포함된 모든 원소를 순회하기가 까다롭다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 비트 필드의 모든 설정된 비트를 순회하려면?
public void printStyles(int styles) {
for (int i = 0; i < 32; i++) {
int bit = 1 << i;
if ((styles & bit) != 0) {
// 어떤 스타일인지 알아내기 위해 추가 로직 필요
switch (bit) {
case STYLE_BOLD: System.out.println("Bold"); break;
case STYLE_ITALIC: System.out.println("Italic"); break;
// ... 모든 케이스 나열
}
}
}
}
순회 코드가 복잡하고 오류가 발생하기 쉽다.
3. 타입 안전성 부재
비트 필드는 결국 정수이기 때문에 타입 안전성이 전혀 없다.
1
2
3
4
5
6
7
// 잘못된 값을 전달해도 컴파일 시점에 알 수 없다
text.applyStyles(42); // 컴파일은 되지만 의미 없는 값
text.applyStyles(STYLE_BOLD | 999); // 정의되지 않은 비트 사용
// 다른 용도의 비트 필드와 혼용 가능
public static final int COLOR_RED = 1 << 0;
text.applyStyles(COLOR_RED); // 컴파일러가 막지 못함!
컴파일러가 의미 없는 값이나 잘못된 타입의 혼용을 전혀 감지하지 못한다.
4. 확장성 문제
API를 변경하지 않고는 비트 필드의 크기를 늘릴 수 없다. 만약 스타일이 32개를 초과하면 int 대신 long을 사용해야 하는데, 이는 API 전체를 수정해야 함을 의미한다.
1
2
3
4
5
// int로는 32개까지만 표현 가능
// 33번째 스타일이 필요하다면
public void applyStyles(long styles) { // API 변경 필요
// ...
}
5. 최대 비트 수 미리 결정 필요
비트 필드를 사용할 때는 API 작성 시 최대 몇 비트가 필요할지 미리 예측해야 한다. 이는 유연성을 크게 제한한다.
EnumSet을 사용한 해결
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public abstract sealed class EnumSet<E extends Enum<E>> extends AbstractSet<E>
implements Cloneable, java.io.Serializable permits JumboEnumSet, RegularEnumSet
{
// declare EnumSet.class serialization compatibility with JDK 8
@java.io.Serial
private static final long serialVersionUID = 1009687484059888093L;
/**
* The class of all the elements of this set.
*/
final transient Class<E> elementType;
/**
* All of the values comprising E. (Cached for performance.)
*/
final transient Enum<?>[] universe;
EnumSet(Class<E>elementType, Enum<?>[] universe) {
this.elementType = elementType;
this.universe = universe;
}
...메서드들
}
자바는 java.util 패키지의 EnumSet 클래스를 제공한다. EnumSet은 열거 타입 상수로 구성된 집합을 효과적으로 표현하며, 비트 필드의 모든 문제점을 해결한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// EnumSet을 사용한 현대적인 접근법
public class Text {
public enum Style {
BOLD, ITALIC, UNDERLINE, STRIKETHROUGH
}
// Set 인터페이스를 사용하여 유연성 확보
public void applyStyles(Set<Style> styles) {
// 각 스타일 처리
for (Style style : styles) {
switch (style) {
case BOLD:
// 굵게 처리
break;
case ITALIC:
// 기울임 처리
break;
case UNDERLINE:
// 밑줄 처리
break;
case STRIKETHROUGH:
// 취소선 처리
break;
}
}
}
}
사용 예시는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
// 간결하고 읽기 쉬운 코드
text.applyStyles(EnumSet.of(Style.BOLD, Style.ITALIC));
// 빈 집합
text.applyStyles(EnumSet.noneOf(Style.class));
// 모든 원소 포함
text.applyStyles(EnumSet.allOf(Style.class));
// 범위 지정
text.applyStyles(EnumSet.range(Style.BOLD, Style.UNDERLINE));
EnumSet의 장점
1. 타입 안전성
EnumSet은 제네릭을 사용하므로 컴파일 시점에 타입 안전성을 보장한다.
1
2
3
4
// 컴파일 에러 - 타입 불일치
text.applyStyles(EnumSet.of(Color.RED)); // 컴파일 오류
enum Color { RED, BLUE, GREEN }
잘못된 타입의 값을 전달하면 컴파일러가 즉시 오류를 발생시킨다.
2. 가독성과 명확성
EnumSet은 toString() 메서드가 잘 구현되어 있어 출력이 명확하다.
EnumSet은 AbstractSet 클래스를 상속하고, AbstractSet은 AbstractCollection의 toString() 메서드를 사용합니다.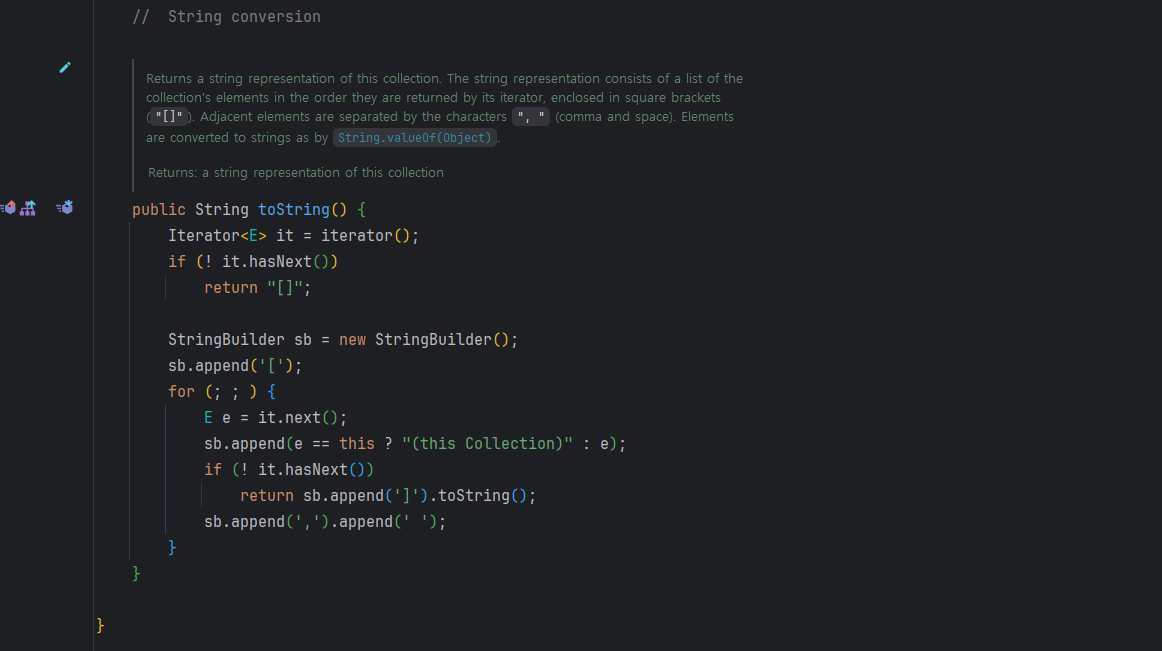
1
2
3
4
Set<Style> styles = EnumSet.of(Style.BOLD, Style.ITALIC);
System.out.println(styles);
// 출력: [BOLD, ITALIC]
// 어떤 스타일이 포함되어 있는지 한눈에 알 수 있다
3. 쉬운 순회
Set 인터페이스를 구현하므로 향상된 for문으로 간단히 순회할 수 있다.
1
2
3
4
Set<Style> styles = EnumSet.of(Style.BOLD, Style.ITALIC);
for (Style style : styles) {
System.out.println(style); // 각 스타일을 순회
}
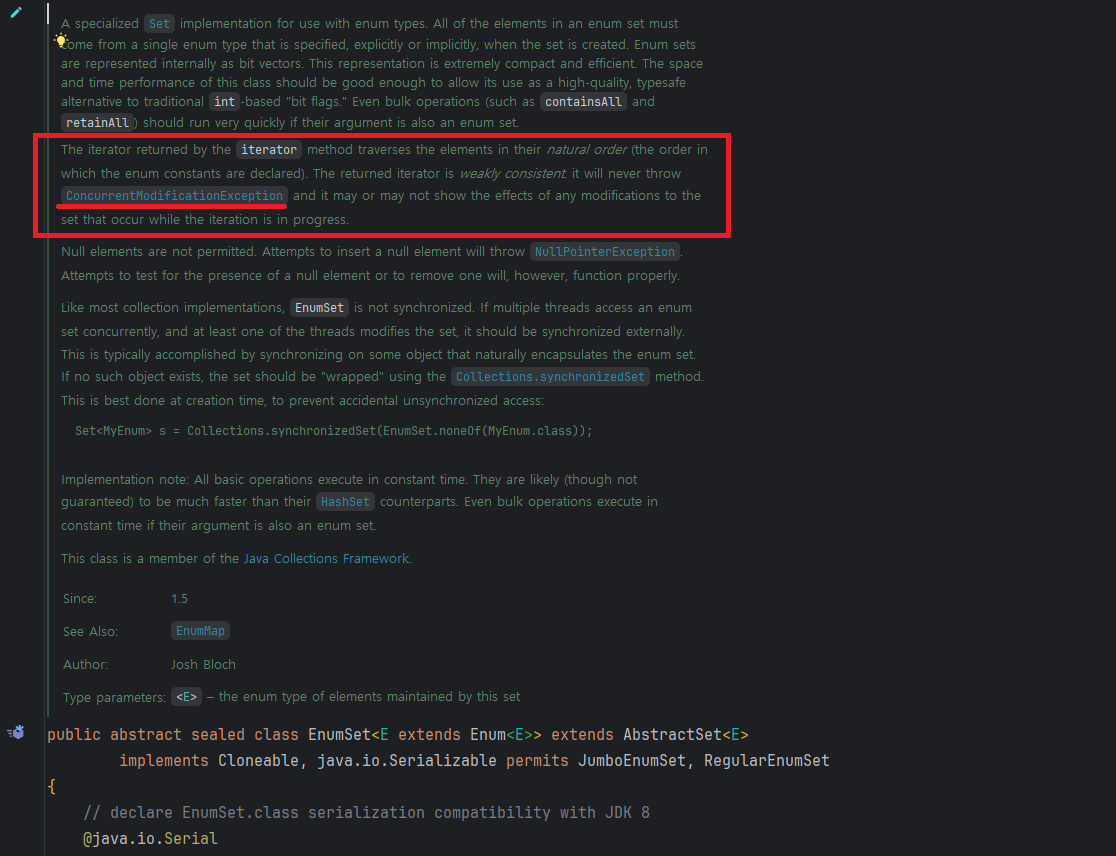
EnumSet의iterator는 선언 순서(natural order) 대로 순회하며, weakly consistent 특성을 가진다. 즉, 반복 중에 집합이 수정되어도ConcurrentModificationException을 던지지 않는다.약한 일관성(Weak Consistency) 은 여러 노드에 분산된 데이터가 반드시 항상 동일하지는 않을 수 있음을 허용하는 특성을 의미한다. 즉, 특정 노드에서 데이터가 업데이트되더라도, 다른 노드에 그 변경 사항이 즉시 반영되지 않아 일시적인 불일치가 발생할 수 있다.
ex)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Set<Style> styles = EnumSet.of(Style.BOLD, Style.ITALIC, Style.UNDERLINE);
// 반복 중 수정해도 안전
for (Style style : styles) {
System.out.println(style);
if (style == Style.BOLD) {
styles.add(Style.STRIKETHROUGH); // 반복 중 추가 - 예외 없음
}
}
// 반면 HashSet은 ConcurrentModificationException 발생
Set<Style> hashSet = new HashSet<>(Arrays.asList(Style.BOLD, Style.ITALIC));
for (Style style : hashSet) {
hashSet.add(Style.UNDERLINE); // ConcurrentModificationException
}
이는 멀티스레드 환경은 아니지만 반복 중 수정이 필요한 경우 유용하다.
4. 풍부한 API
Set 인터페이스의 모든 메서드를 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Set<Style> styles1 = EnumSet.of(Style.BOLD, Style.ITALIC);
Set<Style> styles2 = EnumSet.of(Style.ITALIC, Style.UNDERLINE);
// 합집합
Set<Style> union = EnumSet.copyOf(styles1);
union.addAll(styles2); // [BOLD, ITALIC, UNDERLINE]
// 교집합
Set<Style> intersection = EnumSet.copyOf(styles1);
intersection.retainAll(styles2); // [ITALIC]
// 차집합
Set<Style> difference = EnumSet.copyOf(styles1);
difference.removeAll(styles2); // [BOLD]
// 여집합
Set<Style> complement = EnumSet.complementOf(styles1);
// [UNDERLINE, STRIKETHROUGH]
5. 상수 시간 연산 보장
EnumSet의 모든 기본 연산은 상수 시간 O(1) 에 실행된다. 심지어 대량 연산(bulk operations) 도 인자가 EnumSet이면 상수 시간에 처리된다.
1
2
3
4
5
6
Set<Style> styles1 = EnumSet.of(Style.BOLD, Style.ITALIC);
Set<Style> styles2 = EnumSet.of(Style.ITALIC, Style.UNDERLINE);
// containsAll, retainAll, removeAll 등도 상수 시간
boolean containsAll = styles1.containsAll(styles2); // O(1)
styles1.retainAll(styles2); // O(1) - 교집합 연산
이는 내부적으로 비트 연산을 사용하기 때문이다. 예를 들어 retainAll은 단순히 두 비트 벡터의 AND 연산으로 처리된다.
1
2
3
4
5
6
7
8
public boolean retainAll(Collection<?> c) {
if (c instanceof EnumSet) {
// 비트 AND 연산 한 번으로 교집합 완성!
this.elements &= ((EnumSet)c).elements;
return true;
}
// ... 다른 경우 처리
}
반면 HashSet의 경우 retainAll은 O(n) 또는 O(n*m) 시간이 걸린다.
6. 비트 필드 수준의 성능
EnumSet은 내부적으로 비트 벡터를 사용하여 구현된다. 따라서 비트 필드와 비슷한 성능을 보이면서도 훨씬 안전하고 사용하기 쉽다.
EnumSet의 내부 구조
EnumSet은 추상 클래스 이며, 열거 타입의 크기에 따라 두 가지 구현체 중 하나를 자동으로 선택한다.
1
2
3
4
5
6
7
8
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
Enum<?>[] universe = getUniverse(elementType);
if (universe == null)
throw new ClassCastException(elementType + " not an enum");
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
return new JumboEnumSet<>(elementType, universe);
비트 벡터(Bit Vector)란? 비트 벡터는 각 비트를 boolean 플래그처럼 사용하는 자료구조다. 0과 1로만 표현되는 비트의 특성을 활용하여, 하나의 정수형 변수로 여러 개의 boolean 값을 표현할 수 있다.
1. RegularEnumSet (원소가 64개 이하)
원소가 64개 이하인 열거 타입의 경우, RegularEnumSet이 사용된다. 이 구현체는 단일 long 변수를 비트 벡터로 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class RegularEnumSet<E extends Enum<E>> extends EnumSet<E> {
private long elements = 0L; // 비트 벡터
// 원소 추가: 해당 비트를 1로 설정
public boolean add(E e) {
typeCheck(e);
long oldElements = elements;
elements |= (1L << ((Enum<?>)e).ordinal());
return elements != oldElements;
}
// 원소 포함 여부: 해당 비트가 1인지 확인
public boolean contains(Object e) {
if (e == null)
return false;
Class<?> eClass = e.getClass();
if (eClass != elementType && eClass.getSuperclass() != elementType)
return false;
return (elements & (1L << ((Enum<?>)e).ordinal())) != 0;
}
}
성능 최적화 - universe 캐싱: EnumSet은 열거 타입의 모든 상수를 담은 배열(universe)을 캐싱한다.
1
2
3
4
5
6
7
8
9
// EnumSet의 필드
final transient Class<E> elementType;
final transient Enum<?>[] universe; // 모든 열거 상수 캐싱!
// 캐싱된 universe 활용
private static <E extends Enum<E>> E[] getUniverse(Class<E> elementType) {
return SharedSecrets.getJavaLangAccess()
.getEnumConstantsShared(elementType);
}
이 캐싱으로 인해 allOf(), range() 등의 연산이 매우 빠르다. 매번 리플렉션으로 열거 상수를 가져올 필요가 없기 때문이다.
메모리 효율성 : long 타입 하나만 사용하므로 64비트(8바이트)만 필요하다.
성능 : 비트 연산은 CPU가 하드웨어 수준에서 직접 처리하므로 극도로 빠르다. 합집합은 OR 연산(|), 교집합은 AND 연산(&), 차집합은 AND NOT 연산으로 단일 CPU 명령으로 처리된다.
2. JumboEnumSet (원소가 64개 초과)
원소가 64개를 초과하는 열거 타입의 경우, JumboEnumSet이 사용된다. 이 구현체는 long 배열을 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class JumboEnumSet<E extends Enum<E>> extends EnumSet<E> {
private long elements[]; // long 배열로 비트 벡터 확장
// 원소 추가
public boolean add(E e) {
int eOrdinal = e.ordinal();
int eWordNum = eOrdinal >>> 6; // 64로 나눈 몫 (어느 long인지)
long oldElements = elements[eWordNum];
elements[eWordNum] |= (1L << eOrdinal); // 해당 비트 설정
boolean result = (elements[eWordNum] != oldElements);
if (result)
size++;
return result;
}
}
확장성 : 원소가 65개라면 long 2개를 사용하여 128개까지 표현할 수 있다. 원소 수가 늘어나면 배열 크기가 자동으로 조정된다.
계산 예시 :
- 원소가 70개인 열거 타입의 경우
- 필요한 long 개수: ⌈70 / 64⌉ = 2개
- 메모리 사용량: 2 × 8바이트 = 16바이트 + 배열 오버헤드(약 16바이트) ≈ 32바이트
HashSet으로 같은 집합을 표현하면:
- Entry 객체 오버헤드: 약 32바이트 × 70개 = 2,240바이트
- 해시 테이블 배열: 추가 메모리
- 총 메모리: 약 2.5KB 이상
EnumSet의 메모리 효율성이 약 78배 더 좋다!
EnumSet 생성 방법
EnumSet은 다양한 정적 팩터리 메서드를 제공한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
enum Day {
MONDAY, TUESDAY, WEDNESDAY, THURSDAY,
FRIDAY, SATURDAY, SUNDAY
}
// 1. 특정 원소들로 생성
Set<Day> weekend = EnumSet.of(Day.SATURDAY, Day.SUNDAY);
// 2. 빈 집합
Set<Day> empty = EnumSet.noneOf(Day.class);
// 3. 모든 원소 포함
Set<Day> allDays = EnumSet.allOf(Day.class);
// 4. 범위 지정 (MONDAY부터 FRIDAY까지)
Set<Day> weekdays = EnumSet.range(Day.MONDAY, Day.FRIDAY);
// 5. 여집합 (주말의 여집합 = 평일)
Set<Day> complementWeekend = EnumSet.complementOf(weekend);
// 6. 다른 컬렉션으로부터 생성
Set<Day> copied = EnumSet.copyOf(weekend);
// 7. 일반 컬렉션으로부터 생성
List<Day> dayList = Arrays.asList(Day.MONDAY, Day.TUESDAY);
Set<Day> fromList = EnumSet.copyOf(dayList);
불변 EnumSet 만들기
EnumSet은 가변(mutable) 집합이다. 불변 집합이 필요하다면 Collections.unmodifiableSet으로 감싸야 한다.
1
2
3
4
5
6
7
8
// 불변 EnumSet 생성
Set<Style> styles = Collections.unmodifiableSet(
EnumSet.of(Style.BOLD, Style.ITALIC)
);
// 수정 시도 시 예외 발생
styles.add(Style.UNDERLINE);
// UnsupportedOperationException 발생
자바 9 이상에서는 Set.of를 사용할 수도 있다.
1
2
// 자바 9+: 불변 집합 생성
Set<Style> styles = Set.of(Style.BOLD, Style.ITALIC);
단, Set.of는 EnumSet이 아닌 일반 불변 Set을 반환하므로 EnumSet의 성능 이점은 누릴 수 없다. 따라서 성능이 중요하고 불변성이 필요하다면 Collections.unmodifiableSet(EnumSet)을 사용하는 것이 좋다.
API 설계 시 고려사항
클라이언트가 EnumSet을 넘길 것을 알아도, 메서드 매개변수 타입으로는 EnumSet이 아닌 Set 인터페이스를 사용 하는 것이 좋다.
1
2
3
4
5
6
7
8
9
// 좋은 설계 - 인터페이스 타입 사용
public void applyStyles(Set<Style> styles) {
// ...
}
// 나쁜 설계 - 구현 타입 사용
public void applyStyles(EnumSet<Style> styles) {
// EnumSet만 받을 수 있어 유연성 감소
}
인터페이스 타입을 사용하면 다음과 같은 이점이 있다.
1. 유연성 증가 : 클라이언트가 다른 Set 구현체를 전달할 수 있다.
1
2
3
4
5
6
7
8
9
10
// EnumSet 전달
text.applyStyles(EnumSet.of(Style.BOLD));
// HashSet 전달 가능
Set<Style> hashSet = new HashSet<>();
hashSet.add(Style.BOLD);
text.applyStyles(hashSet);
// 불변 Set 전달 가능
text.applyStyles(Set.of(Style.BOLD, Style.ITALIC));
2. 테스트 용이성 : 테스트에서 모킹(mocking)이나 다른 구현체를 사용하기 쉽다.
1
2
3
// 테스트용 커스텀 Set 사용 가능
Set<Style> mockSet = new MockSet();
text.applyStyles(mockSet);
3. 변경 유연성 : 내부 구현을 변경하더라도 API는 그대로 유지된다.
다만, 메서드 구현 내부에서는 EnumSet으로 변환하여 성능 이점을 누릴 수 있다.
1
2
3
4
5
6
7
8
9
10
public void applyStyles(Set<Style> styles) {
// 내부에서 EnumSet으로 변환하여 성능 최적화
Set<Style> styleSet = styles instanceof EnumSet ?
styles : EnumSet.copyOf(styles);
// styleSet을 사용하여 처리
for (Style style : styleSet) {
// ...
}
}
실제 사용 예시: 파일 속성 처리
실무에서 EnumSet이 어떻게 활용되는지 구체적인 예를 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
import java.nio.file.*;
import java.util.*;
public class FileProcessor {
// 파일 처리 옵션
public enum ProcessOption {
COMPRESS, // 압축
ENCRYPT, // 암호화
BACKUP, // 백업 생성
VERIFY_CHECKSUM, // 체크섬 검증
LOG_OPERATIONS, // 작업 로깅
OVERWRITE_EXISTING // 기존 파일 덮어쓰기
}
/**
* 파일을 처리한다.
* @param source 원본 파일
* @param target 대상 파일
* @param options 처리 옵션들
*/
public void processFile(Path source, Path target,
Set<ProcessOption> options) {
// 백업이 필요한 경우
if (options.contains(ProcessOption.BACKUP)) {
createBackup(source);
}
// 파일 읽기
byte[] data = readFile(source);
// 체크섬 검증
if (options.contains(ProcessOption.VERIFY_CHECKSUM)) {
verifyChecksum(data);
}
// 압축
if (options.contains(ProcessOption.COMPRESS)) {
data = compress(data);
}
// 암호화
if (options.contains(ProcessOption.ENCRYPT)) {
data = encrypt(data);
}
// 파일 쓰기
writeFile(target, data,
options.contains(ProcessOption.OVERWRITE_EXISTING));
// 로깅
if (options.contains(ProcessOption.LOG_OPERATIONS)) {
logOperation(source, target, options);
}
}
// 보조 메서드들 (구현 생략)
private void createBackup(Path source) { /* ... */ }
private byte[] readFile(Path source) { return new byte[0]; }
private void verifyChecksum(byte[] data) { /* ... */ }
private byte[] compress(byte[] data) { return data; }
private byte[] encrypt(byte[] data) { return data; }
private void writeFile(Path target, byte[] data, boolean overwrite) { /* ... */ }
private void logOperation(Path source, Path target, Set<ProcessOption> options) { /* ... */ }
// 사용 예시
public static void main(String[] args) {
FileProcessor processor = new FileProcessor();
Path source = Paths.get("source.txt");
Path target = Paths.get("target.txt");
// 기본 처리: 압축만
processor.processFile(source, target,
EnumSet.of(ProcessOption.COMPRESS));
// 보안 처리: 백업, 압축, 암호화, 로깅
processor.processFile(source, target,
EnumSet.of(
ProcessOption.BACKUP,
ProcessOption.COMPRESS,
ProcessOption.ENCRYPT,
ProcessOption.LOG_OPERATIONS
));
// 완전한 처리: 모든 옵션
processor.processFile(source, target,
EnumSet.allOf(ProcessOption.class));
// 옵션 없음
processor.processFile(source, target,
EnumSet.noneOf(ProcessOption.class));
}
}
이 예시는 EnumSet의 실용성을 잘 보여준다. 여러 옵션을 조합하여 전달할 수 있고, 코드의 가독성이 높으며, 타입 안전하다.
비트 필드와 EnumSet 성능 비교
많은 개발자들이 “비트 필드가 더 빠르지 않을까?”라고 생각한다. 실제로 성능을 비교해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
public class Effective_Java_Item_36 {
enum Style { BOLD, ITALIC, UNDERLINE, STRIKETHROUGH }
// 비트 필드 방식
static final int BOLD = 1 << 0;
static final int ITALIC = 1 << 1;
static final int UNDERLINE = 1 << 2;
static final int STRIKETHROUGH = 1 << 3;
public static void main(String[] args) {
int warmup = 5_000_000; // JIT 컴파일러 워밍업
int iterations = 10_000_000;
// 워밍업 (JIT 컴파일러 최적화를 위해)
for (int i = 0; i < warmup; i++) {
Set<Style> set = EnumSet.of(Style.BOLD, Style.ITALIC);
set.contains(Style.BOLD);
int flags = BOLD | ITALIC;
boolean has = (flags & BOLD) != 0;
}
// EnumSet 테스트
long start = System.nanoTime();
for (int i = 0; i < iterations; i++) {
Set<Style> set = EnumSet.of(Style.BOLD, Style.ITALIC);
boolean hasBold = set.contains(Style.BOLD);
boolean hasUnderline = set.contains(Style.UNDERLINE);
}
long enumSetTime = System.nanoTime() - start;
// 비트 필드 테스트
start = System.nanoTime();
for (int i = 0; i < iterations; i++) {
int flags = BOLD | ITALIC;
boolean hasBold = (flags & BOLD) != 0;
boolean hasUnderline = (flags & UNDERLINE) != 0;
}
long bitFieldTime = System.nanoTime() - start;
System.out.println("EnumSet: " + enumSetTime / 1_000_000 + "ms");
System.out.println("Bit Field: " + bitFieldTime / 1_000_000 + "ms");
System.out.printf("Ratio: %.2fx%n", (double)enumSetTime / bitFieldTime);
}
}
실행 결과 :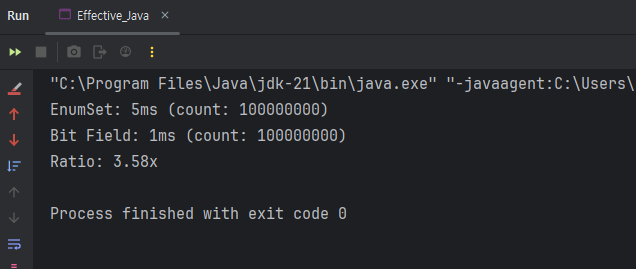
EnumSet이 비트 필드보다 약간 느린 것은 사실이다. 그러나 이 차이는 매우 미미 하며, 대부분의 애플리케이션에서는 전혀 문제가 되지 않는다.
성능 차이가 나는 이유
- EnumSet은 객체 생성 오버헤드가 있다
- 메서드 호출을 통해 비트 연산을 수행한다
- JIT 컴파일러가 최적화하지만 순수 비트 연산보다는 느리다
그럼에도 EnumSet을 사용해야 하는 이유
- 미세한 성능 차이 : 실제 애플리케이션에서 이 차이는 측정하기 어려울 정도로 작다
- 유지보수성 : 코드의 가독성과 안전성이 훨씬 중요하다
- 버그 방지 : 타입 안전성으로 인한 버그 방지 효과가 성능 차이를 상쇄하고도 남는다
- 최적화 : JVM은 계속 발전하며, EnumSet의 성능도 함께 개선된다
성능이 정말 중요한 경우 : 극도로 성능이 중요한 저수준 시스템(게임 엔진, 실시간 시스템 등)에서는 비트 필드를 고려할 수 있다. 그러나 이런 경우는 매우 드물며, 대부분의 애플리케이션에서는 EnumSet이 더 나은 선택이다.
주의사항과 제약사항
1. null 원소 불가
EnumSet은 null 원소를 허용하지 않는다.
1
2
Set<Style> styles = EnumSet.noneOf(Style.class);
styles.add(null); // NullPointerException 발생
2. 열거 타입만 사용 가능
EnumSet은 열거 타입 원소만 담을 수 있다. 일반 클래스에는 사용할 수 없다.
1
2
// 컴파일 오류
EnumSet<String> stringSet = EnumSet.noneOf(String.class);
3. 동기화되지 않음
EnumSet은 스레드 안전하지 않다. 여러 스레드에서 접근한다면 외부 동기화가 필요하다.
1
2
3
4
// 스레드 안전한 EnumSet
Set<Style> syncSet = Collections.synchronizedSet(
EnumSet.noneOf(Style.class)
);
4. 직렬화 주의
EnumSet 자체는 직렬화 가능하지만, 역직렬화 시 구체적인 구현 클래스(RegularEnumSet 또는 JumboEnumSet)가 달라질 수 있다. 따라서 직렬화된 형태에 의존하는 코드는 작성하지 말아야 한다.
다른 Set 구현체와의 비교
| 특징 | EnumSet | HashSet | TreeSet |
|---|---|---|---|
| 원소 타입 | 열거 타입만 | 모든 객체 | Comparable 객체 |
| 내부 구조 | 비트 벡터 | 해시 테이블 | 레드-블랙 트리 |
| 메모리 | 매우 효율적 | 보통 | 많음 |
| contains 성능 | O(1) | O(1) | O(log n) |
| 순서 보장 | 선언 순서 | 없음 | 정렬 순서 |
| null 허용 | 불가 | 가능 (1개) | 불가 |
| 동기화 | 불가 | 불가 | 불가 |
EnumSet은 열거 타입 전용이라는 제약이 있지만, 그 범위 내에서는 최고의 성능과 효율성을 보인다.
실제 Java API의 활용 사례
Java 표준 라이브러리에서 EnumSet을 활용하는 몇 가지 예를 살펴보자.
java.util.concurrent.CopyOnWriteArraySet
1
2
3
4
5
6
// 동시성 컬렉션에서 옵션 전달
Set<CopyOption> options = EnumSet.of(
StandardCopyOption.REPLACE_EXISTING,
StandardCopyOption.COPY_ATTRIBUTES
);
Files.copy(source, target, options.toArray(new CopyOption[0]));
java.nio.file 패키지
1
2
3
4
5
6
7
8
9
10
11
// 파일 열기 옵션
Set<OpenOption> options = EnumSet.of(
StandardOpenOption.CREATE,
StandardOpenOption.APPEND
);
Files.write(path, bytes, options.toArray(new OpenOption[0]));
// 파일 속성
Set<PosixFilePermission> permissions =
PosixFilePermissions.fromString("rwxr-x---");
Files.setPosixFilePermissions(path, permissions);
이처럼 Java API 설계자들도 집합으로 사용될 열거 타입 에는 EnumSet을 적극 활용하고 있다.
마치며
비트 필드는 과거의 유물이다. 현대 Java에서는 EnumSet이 비트 필드의 완벽한 대안 이 되며, 다음과 같은 이점을 제공한다.
핵심 원칙 :
- 타입 안전성 : 컴파일 시점에 오류를 잡는다
- 가독성 : 코드가 명확하고 이해하기 쉽다
- 유연성 : Set 인터페이스의 풍부한 API를 활용할 수 있다
- 성능 : 비트 벡터를 내부적으로 사용하여 효율적이다
- 간결성 : 간결한 API로 복잡한 집합 연산을 쉽게 수행한다
열거할 수 있는 타입을 한데 모아 집합 형태로 사용한다고 해서 비트 필드를 사용할 이유는 없다. EnumSet 클래스가 비트 필드 수준의 성능과 열거 타입의 장점을 모두 제공하기 때문이다.
메서드 매개변수로 EnumSet 대신 Set 인터페이스를 받도록 설계 하면 API의 유연성을 유지하면서도 클라이언트가 EnumSet을 사용하도록 유도할 수 있다. 명확성, 안전성, 편의성 모두를 얻을 수 있는 EnumSet을 적극 활용하자.
References
- 이펙티브 자바 3/E