[Effective Java] - 상속보다는 컴포지션을 사용하라

Item 18. 상속보다는 컴포지션을 사용하라
들어가며
상속(inheritance)은 코드 재사용의 강력한 수단이지만, 항상 최선은 아니다. 잘못 사용하면 오류를 내기 쉬운 소프트웨어를 만들게 된다. 이번 아이템에서는 상속의 문제점과 이를 해결하는 컴포지션(composition) 방식에 대해 알아본다.
주의: 여기서 말하는 상속은 클래스가 다른 클래스를 확장하는 구현 상속을 말한다. 인터페이스 상속(클래스가 인터페이스를 구현하거나 인터페이스가 다른 인터페이스를 확장)과는 무관하다.
상속의 문제점
1. 메서드 호출과 달리 상속은 캡슐화를 깨뜨린다
상위 클래스가 어떻게 구현되느냐에 따라 하위 클래스의 동작에 이상이 생길 수 있다. 상위 클래스는 릴리스마다 내부 구현이 달라질 수 있으며, 그 여파로 하위 클래스가 오동작할 수 있다.
문제가 되는 예시:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class InstrumentedHashSet<E> extends HashSet<E> {
private int addCount = 0; // 추가된 원소의 수
public InstrumentedHashSet() {
}
public InstrumentedHashSet(int initCap, float loadFactor) {
super(initCap, loadFactor);
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}
이 클래스를 사용해보면
1
2
3
InstrumentedHashSet<String> s = new InstrumentedHashSet<>();
s.addAll(List.of("틱", "탁탁", "펑"));
System.out.println(s.getAddCount()); // 예상: 3, 실제: 6
Q. 왜 6이 나올까?
A. HashSet의 addAll 메서드가 내부적으로 add 메서드를 호출하기 때문이다.
-
addAll이 호출되면addCount에 3이 더해진다 -
super.addAll(c)를 호출하면 내부적으로 각 원소마다add를 호출한다 -
우리가 재정의한
add가 호출되면서 각각addCount가 1씩 증가한다 -
결과적으로 3 + 3 = 6이 된다
HashSet의 상속 구조와 메서드 구현:
HashSet에는addAll이 없다!- 부모 클래스인
AbstractCollection의 구현을 사용한다
상속구조
1
2
3
4
5
HashSet
↓ extends
AbstractSet
↓ extends
AbstractCollection ← 여기에 addAll이 구현되어 있다!
AbstractCollection의 addAll 구현:
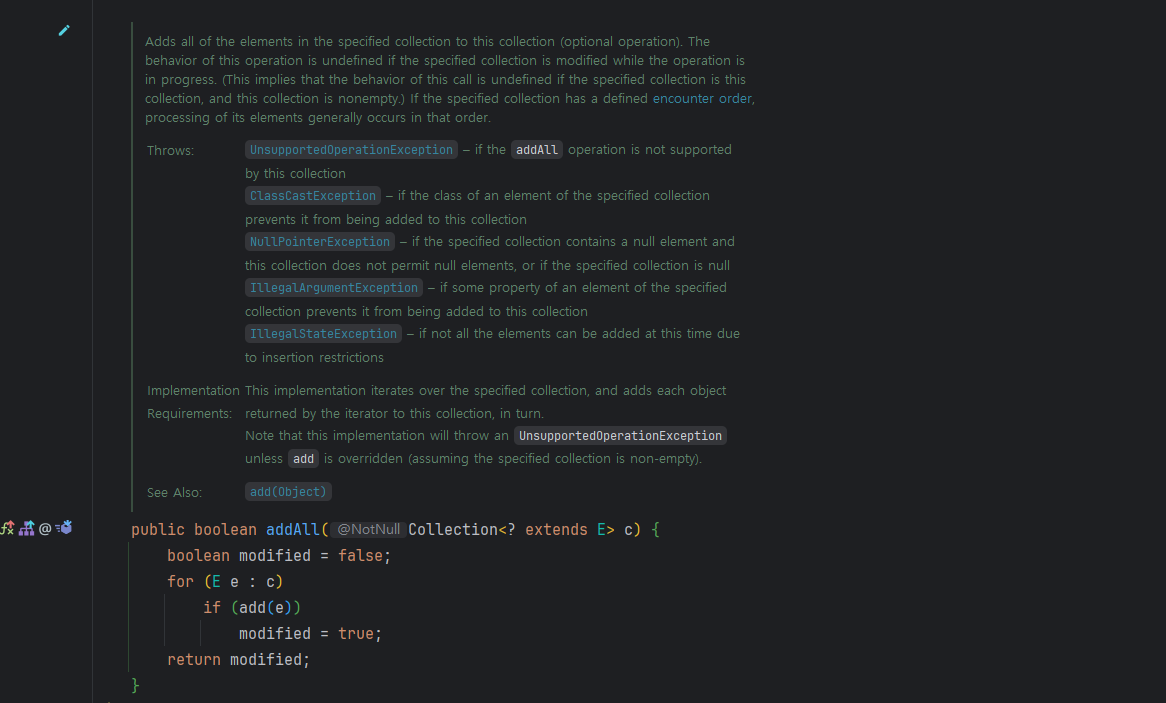
if(add(e))에서 각 원소마다add()메서드를 호출
이게 왜 문제가 되는걸까?
1. 자식 클래스는 부모의 내부 구현을 알 수 없다.
우리는 addAll이 내부적으로 add를 호출한다는 사실을 몰랐다. 부모 클래스의 구현 세부사항을 알아야만 올바르게 오버라이드할 수 있다는 것은 캡슐화 원칙을 위반한다.
2. 부모 클래스 변경에 취약하다.
만약 미래의 Java 버전에서 AbstractCollection.addAll 의 구현 방식이 바뀐다면?
addAll() 에서 더이상 add() 를 호출하지 않고 직접 구현으로 변경된다면 우리의 addCount 는 더 이상 제대로 증가하지 않는다. 즉, 상위 클래스의 구현 변경에 따라 하위 클래스가 오동작하게 된다.
3. 수정 시도의 한계
그렇다면 addAll 을 다르게 구현하면 되지 않을까?
1
2
3
4
5
6
7
8
9
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
boolean result = false;
for (E e : c) {
result |= super.add(e); // super.add()를 직접 호출
}
return result;
}
이렇게 하면 중복 카운트 문제는 해결되지만,
- HashSet의 add 메서드를 우회할 수 없다.
- 만약 HashSet이 addAll을 최적화된 방식으로 구현했다면 그 이점을 잃는다.
- 여전히 상위 클래스의 내부 구현에 의존한다.
2. 상위 클래스에 새로운 메서드가 추가되면 하위 클래스가 깨질 수 있다
예를 들어, 특정 조건을 만족하는 원소만 추가할 수 있도록 제한한 하위 클래스가 있다고 하자. 상위 클래스에 원소를 추가하는 새로운 메서드가 추가되면, 이 제약을 우회할 수 있게 된다.
컴포지션
이를 해결하는 개념이 컴포지션이다.
기존 클래스를 확장하는 대신, 새로운 클래스를 만들고 private 필드로 기존 클래스의 인스턴스를 참조하게 하자. 이를 컴포지션(composition, 구성)이라고 한다.
새 클래스의 인스턴스 메서드들은 기존 클래스의 대응하는 메서드를 호출해 그 결과를 반환한다. 이 방식을 전달(forwarding)이라 하며, 새 클래스의 메서드들을 전달 메서드(forwarding method)라 부른다.
컴포지션 활용:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// 재사용 가능한 전달 클래스
public class ForwardingSet<E> implements Set<E> {
private final Set<E> s; // 컴포지션
public ForwardingSet(Set<E> s) {
this.s = s;
}
public void clear() { s.clear(); }
public boolean contains(Object o) { return s.contains(o); }
public boolean isEmpty() { return s.isEmpty(); }
public int size() { return s.size(); }
public Iterator<E> iterator() { return s.iterator(); }
public boolean add(E e) { return s.add(e); }
public boolean remove(Object o) { return s.remove(o); }
public boolean containsAll(Collection<?> c) { return s.containsAll(c); }
public boolean addAll(Collection<? extends E> c) { return s.addAll(c); }
public boolean removeAll(Collection<?> c) { return s.removeAll(c); }
public boolean retainAll(Collection<?> c) { return s.retainAll(c); }
public Object[] toArray() { return s.toArray(); }
public <T> T[] toArray(T[] a) { return s.toArray(a); }
@Override
public boolean equals(Object o) { return s.equals(o); }
@Override
public int hashCode() { return s.hashCode(); }
@Override
public String toString() { return s.toString(); }
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// 래퍼 클래스 - 상속 대신 컴포지션 사용
public class InstrumentedSet<E> extends ForwardingSet<E> {
private int addCount = 0;
public InstrumentedSet(Set<E> s) {
super(s);
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}
래퍼 클래스와 컴포지션의 동작 원리
무엇을 ‘감싼다’는 말일까?
래퍼 클래스는 기존 객체를 내부에 품고(포함하고), 그 객체에게 실제 작업을 위임하면서 추가 기능을 더하는 방식이다.
아래 코드로 동작 구조를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 1. 기본 Set 생성
Set<String> originalSet = new HashSet<>();
// 2. InstrumentedSet으로 감싸기
InstrumentedSet<String> wrappedSet = new InstrumentedSet<>(originalSet);
// ^^^^^^^^^^^
// 이 기존 Set을 내부에 보관하고 감싼다
// 3. 메서드 호출 시 흐름
wrappedSet.add("Hello");
/*
↓
InstrumentedSet의 add() 호출
→ addCount++ (추가 기능)
→ super.add(e) 호출
↓
ForwardingSet의 add() 호출
→ s.add(e) 호출 (s는 내부에 감싸진 originalSet)
↓
실제 HashSet의 add() 실행
*/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// 1단계: ForwardingSet - 전달 클래스
public class ForwardingSet<E> implements Set<E> {
private final Set<E> s; // ← 여기에 실제 Set을 보관 (감싼다)
public ForwardingSet(Set<E> s) {
this.s = s; // 생성자로 받은 Set을 저장
}
// 모든 메서드는 내부 Set에게 작업을 위임
public boolean add(E e) {
return s.add(e); // s에게 실제 작업을 시킨다
}
}
// 2단계: InstrumentedSet - 기능 추가 클래스
public class InstrumentedSet<E> extends ForwardingSet<E> {
private int addCount = 0; // 추가 기능: 카운팅
public InstrumentedSet(Set<E> s) {
super(s); // ForwardingSet에게 전달 → s에 저장됨
}
@Override
public boolean add(E e) {
addCount++; // 추가 기능 실행
return super.add(e); // 실제 작업은 위임
}
}
Q. 왜 2단계로 나눴을까?
ForwardingSet 은 재사용 가능한 전달 뼈대이고, InstrumentedSet 은 구체적인 기능을 추가하는 클래스다. 이렇게 분리하면 다른 기능도 쉽게 추가할 수 있다.
컴포지션과 전달의 장점
-
캡슐화 유지: 기존 클래스의 내부 구현 방식의 영향에서 벗어난다.
-
유연함: 어떤 Set 구현체도 감쌀 수 있고, 기존 생성자와 함께 사용할 수 있다.
-
견고함: 기존 클래스에 새로운 메서드가 추가되어도 전혀 영향받지 않는다.
1
2
3
// 다양한 Set 구현체와 함께 사용 가능
Set<Instant> times = new InstrumentedSet<>(new TreeSet<>(cmp));
Set<E> s = new InstrumentedSet<>(new HashSet<>(INIT_CAPACITY));
이러한 InstrumentedSet 같은 클래스를 래퍼 클래스(wrapper class)라고 하며, 다른 인스턴스를 감싸고 있다는 뜻에서 데코레이터 패턴(Decorator pattern)이라고도 한다.
데코레이터 패턴(Decorator Pattern)
객체에 추가 기능을 동적으로 덧붙인다. 기능 확장이 필요할 때 상속 대신 사용할 수 있는 유연한 대안이다.
실제 Java I/O 클래스에서 데코레이터 패턴을 찾을 수 있었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
// 1. 최상위 추상 클래스 (Set 인터페이스 역할)
public abstract class InputStream {
public abstract int read() throws IOException;
}
// 2. FilterInputStream - 전달만 하는 클래스 (ForwardingSet 역할)
public class FilterInputStream extends InputStream {
protected InputStream in; // 실제 InputStream을 보관
protected FilterInputStream(InputStream in) {
this.in = in;
}
public int read() throws IOException {
return in.read(); // 위임
}
}
// 3-1. BufferedInputStream - 기능 추가 (버퍼링)
public class BufferedInputStream extends FilterInputStream {
protected byte[] buf; // 버퍼!
public BufferedInputStream(InputStream in) {
super(in);
}
public int read() throws IOException {
// 버퍼에서 먼저 읽고, 없으면 in.read() 호출
if (버퍼에_데이터_있음) {
return 버퍼에서_읽기;
}
return in.read(); // 위임
}
}
// 3-2. DataInputStream - 기능 추가 (타입별 읽기)
public class DataInputStream extends FilterInputStream {
public DataInputStream(InputStream in) {
super(in);
}
public int readInt() throws IOException {
// 4바이트를 읽어서 int로 변환하는 기능 추가!
byte[] bytes = new byte[4];
in.read(bytes); // 위임
return bytes를_int로_변환;
}
}
// 4. FileInputStream - 실제 구현체 (HashSet 역할)
public class FileInputStream extends InputStream {
private FileDescriptor fd; // 실제 파일!
public int read() throws IOException {
return 파일에서_실제로_읽기(); // 실제 일!
}
}
사용예시
1
2
3
4
5
6
7
8
// 기능을 자유롭게 조합
DataInputStream stream = new DataInputStream(
new BufferedInputStream(
new FileInputStream("file.txt")
)
);
// FileInputStream을 BufferedInputStream으로 감싸고,
// 그걸 다시 DataInputStream으로 감싼다
동작순서:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int value = dataStream.readInt();
// 호출 순서:
1. DataInputStream.readInt() 호출
→ readFully()로 4바이트 읽기 요청
2. DataInputStream은 FilterInputStream을 상속했으므로
→ 상속받은 read(byte[], int, int) 호출
→ this.in.read(b, off, len) 실행
→ this.in = BufferedInputStream
3. BufferedInputStream.read(byte[], int, int) 호출
→ 버퍼에서 데이터 제공
→ 버퍼가 비었으면 this.in.read() 호출
→ this.in = FileInputStream
4. FileInputStream.read() 호출
→ 실제 파일에서 읽기
정리
DataInputStream 은 FilterInputStream 을 상속한다. 따라서 DataInputStream 이 read() 를 호출하면 부모인 FilterInputStream 의 메서드가 실행된다.
FilterInputStream 의 read() 메서드는 단순히 내부에 보관 중인 스트림의 read() 를 호출할 뿐이다. 실제로는 FilterInputStream 이 중간에 끼어서 무언가를 처리하는 게 아니라, 위임 로직을 제공하는 부모 클래스일 뿐이다.
핵심: FilterInputStream 은 모든 호출을 내부 스트림에게 위임하고, 각 데코레이터(BufferedInputStream, DataInputStream 등)는 필요한 기능만 추가한다. 상속이 아닌 컴포지션으로 기능을 조합하기 때문에, 레고 블록처럼 자유롭게 기능을 추가하거나 제거할 수 있다. 이것이 바로 컴포지션의 힘이다.
래퍼클래스 단점
래퍼 클래스는 단점이 거의 없지만, 래퍼 클래스가 콜백(callback) 프레임워크와는 어울리지 않는다는 점만 주의하면 된다.
콜백 프레임워크에서는 자기 자신의 참조를 다른 객체에 넘겨서 다음 호출(콜백) 때 사용하도록 한다. 내부 객체는 자신을 감싸고 있는 래퍼의 존재를 모르니 대신 자신(this)의 참조를 넘기고, 콜백 때는 래퍼가 아닌 내부 객체를 호출하게 된다. 이를 SELF 문제 라고 한다.
상속을 사용해도 되는 경우
상속은 반드시 하위 클래스가 상위 클래스의 ‘진짜’ 하위 타입인 상황에서만 쓰여야 한다. 클래스 B가 클래스 A를 상속할 때, “B가 정말 A인가?”라는 질문에 확실히 “그렇다”고 답할 수 있을 때만 상속하자.
잘못된 상속의 예:
Stack이Vector를 상속 (Stack은 Vector가 아니다)Properties가Hashtable을 상속 (Properties는 Hashtable이 아니다)
이 두 경우 모두 컴포지션을 사용했어야 했다.
마치며
상속은 강력하지만 캡슐화를 해친다는 문제가 있다. 상속은 상위 클래스와 하위 클래스가 순수한 is-a 관계일 때만 사용해야 한다. is-a 관계일 때도 하위 클래스의 패키지가 상위 클래스와 다르고, 상위 클래스가 확장을 고려해 설계되지 않았다면 여전히 문제가 될 수 있다.
상속의 취약점을 피하려면 상속 대신 컴포지션과 전달을 사용하자. 특히 래퍼 클래스로 구현할 적당한 인터페이스가 있다면 더욱 그렇다. 래퍼 클래스는 하위 클래스보다 견고하고 강력하다.
References
- Effective Java 3/E