[Effective Java] - null이 아닌, 빈 컬렉션이나 배열을 반환하라

Item 54 : null이 아닌, 빈 컬렉션이나 배열을 반환하라
들어가며
메서드가 컬렉션이나 배열을 반환할 때, 결과가 없는 경우 어떻게 처리해야 할까? 많은 개발자들이 null을 반환하는 것이 자연스럽다고 생각한다. 하지만 이는 클라이언트 코드에 방어 로직을 강제하고, 방어 코드를 빼먹으면 NullPointerException이라는 지뢰를 심는 결과를 낳는다.
빈 컬렉션이나 빈 배열을 반환하는 것이 null을 반환하는 것보다 거의 항상 낫다. 이 아이템에서는 왜 그런지, 그리고 어떻게 효율적으로 구현하는지 살펴본다.
null 반환의 문제점
먼저 null을 반환하는 전형적인 코드를 보자.
1
2
3
4
5
6
7
8
9
10
11
// 나쁜 예: null 반환
public class Shop {
private final List<Cheese> cheesesInStock = new ArrayList<>();
/**
* @return 재고가 있는 치즈 목록. 없으면 null 반환
*/
public List<Cheese> getCheeses() {
return cheesesInStock.isEmpty() ? null : new ArrayList<>(cheesesInStock);
}
}
이 메서드를 사용하는 클라이언트는 항상 null 체크를 해야 한다.
1
2
3
4
5
6
7
Shop shop = new Shop();
List<Cheese> cheeses = shop.getCheeses();
// 방어 코드 필수
if (cheeses != null && cheeses.contains(Cheese.STILTON)) {
System.out.println("좋았어, 스틸턴이 있네!");
}
Q. 방어 코드를 빼먹으면 어떻게 될까?
1
2
3
4
5
6
7
Shop shop = new Shop();
List<Cheese> cheeses = shop.getCheeses();
// null 체크를 깜빡함
for (Cheese cheese : cheeses) { // NullPointerException!
System.out.println(cheese);
}
재고가 없을 때 getCheeses()가 null을 반환하면 위 코드는 NullPointerException을 던진다.
문제는 이런 오류가 런타임에만 발견된다는 점이다. 테스트 커버리지가 충분하지 않으면 프로덕션 환경에서 발견될 수 있다.
null 반환은 API 사용을 어렵게 만든다
null을 반환하는 API는 사용하기 어렵고 오류를 유발하기 쉽다. 클라이언트는 항상 다음을 기억해야 한다:
- 이 메서드가 null을 반환할 수 있는가?
- null 체크를 해야 하는가?
- null 체크를 어디서 해야 하는가?
반면 빈 컬렉션을 반환하면 이런 고민이 사라진다.
빈 컬렉션 반환의 장점
빈 컬렉션을 반환하도록 수정해보자.
1
2
3
4
5
6
7
8
9
10
11
// 좋은 예: 빈 컬렉션 반환
public class Shop {
private final List<Cheese> cheesesInStock = new ArrayList<>();
/**
* @return 재고가 있는 치즈 목록. 항상 null이 아닌 리스트 반환
*/
public List<Cheese> getCheeses() {
return new ArrayList<>(cheesesInStock);
}
}
클라이언트 코드가 훨씬 간결해진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
Shop shop = new Shop();
List<Cheese> cheeses = shop.getCheeses();
// null 체크 불필요
for (Cheese cheese : cheeses) { // 재고가 없으면 루프를 실행하지 않음
System.out.println(cheese);
}
// Stream API와도 자연스럽게 동작
long count = shop.getCheeses()
.stream()
.filter(cheese -> cheese.getAge() > 10)
.count();
빈 컬렉션은 정상적인 반복문의 시작 조건을 만족하지 않으므로 자연스럽게 아무것도 실행하지 않는다. 즉, null 체크가 필요 없다.
코드가 더 간결하고 안전하다
1
2
3
4
5
6
7
8
9
10
11
12
// null 반환 버전: 방어 코드 필요
List<Cheese> cheeses = shop.getCheeses();
if (cheeses != null) {
for (Cheese cheese : cheeses) {
process(cheese);
}
}
// 빈 컬렉션 반환 버전: 방어 코드 불필요
for (Cheese cheese : shop.getCheeses()) {
process(cheese);
}
두 번째 버전이 훨씬 간결하고 의도도 명확하다. 그리고 실수할 여지가 없다.
“빈 컬렉션 할당은 비용이 든다”는 오해
가끔 다음과 같은 주장을 듣는다: “빈 컬렉션을 할당하는 것도 비용인데, null을 반환하는 게 낫지 않나?”
이는 틀린 주장이다. 세 가지 이유가 있다.
1. 성능 차이는 무시할 수 있는 수준이다
빈 컬렉션을 할당하는 비용은 대부분의 경우 측정조차 어려울 정도로 작다. 성능 최적화는 측정 가능한 성능 문제가 있을 때만 해야 한다.
1
2
3
4
// 빈 ArrayList 할당 비용은 매우 작다
public List<Cheese> getCheeses() {
return new ArrayList<>(); // 객체 하나 할당, 보통 나노초 단위
}
2. 불변 빈 컬렉션을 재사용하면 할당도 없다
빈 컬렉션을 매번 할당하는 것이 정말 문제라면, 불변 빈 컬렉션을 재사용하면 된다. Collections.emptyList(), Collections.emptySet(), Collections.emptyMap() 등이 이를 위해 제공된다.
1
2
3
4
5
6
// 최적화된 버전: 불변 빈 컬렉션 재사용
public List<Cheese> getCheeses() {
return cheesesInStock.isEmpty()
? Collections.emptyList() // 할당 없음, 항상 같은 인스턴스
: new ArrayList<>(cheesesInStock);
}
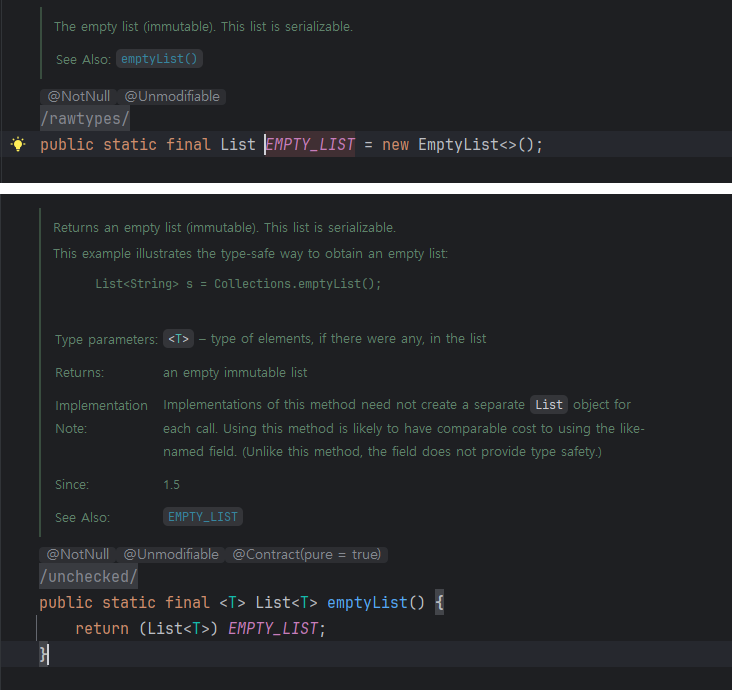
Collections.emptyList()는 싱글턴 인스턴스를 반환한다. 즉, 어디서 호출하든 같은 객체를 반환하므로 메모리 할당이 일어나지 않는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
// emptyList()의 내부 구현
public class Collections {
@SuppressWarnings("rawtypes")
public static final List EMPTY_LIST = new EmptyList<>();
@SuppressWarnings("unchecked")
public static final <T> List<T> emptyList() {
return (List<T>) EMPTY_LIST; // 항상 같은 인스턴스
}
private static class EmptyList<E>
extends AbstractList<E>
implements RandomAccess, Serializable {
@java.io.Serial
private static final long serialVersionUID = 8842843931221139166L;
public Iterator<E> iterator() {
return emptyIterator();
}
public ListIterator<E> listIterator() {
return emptyListIterator();
}
public int size() {return 0;}
public boolean isEmpty() {return true;}
public void clear() {}
public boolean contains(Object obj) {return false;}
public boolean containsAll(Collection<?> c) { return c.isEmpty(); }
public Object[] toArray() { return new Object[0]; }
public <T> T[] toArray(T[] a) {
if (a.length > 0)
a[0] = null;
return a;
}
public E get(int index) {
throw new IndexOutOfBoundsException("Index: "+index);
}
public boolean equals(Object o) {
return (o instanceof List) && ((List<?>)o).isEmpty();
}
public int hashCode() { return 1; }
@Override
public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
return false;
}
@Override
public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
}
@Override
public void sort(Comparator<? super E> c) {
}
// Override default methods in Collection
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
}
@Override
public Spliterator<E> spliterator() { return Spliterators.emptySpliterator(); }
// Preserves singleton property
@java.io.Serial
private Object readResolve() {
return EMPTY_LIST;
}
}
}
3. 잘못된 최적화는 코드 품질을 해친다
null 반환으로 얻는 미세한 성능 이득(있다면)보다 클라이언트 코드의 복잡도 증가와 오류 가능성이 훨씬 큰 손실이다. Donald Knuth의 유명한 말을 기억하라: “성급한 최적화는 모든 악의 근원이다.”
배열도 마찬가지다
배열을 반환하는 메서드도 null 대신 길이가 0인 배열을 반환해야 한다.
1
2
3
4
5
6
7
8
9
10
// 나쁜 예: null 반환
public Cheese[] getCheeses() {
return cheesesInStock.isEmpty() ? null :
cheesesInStock.toArray(new Cheese[0]);
}
// 좋은 예: 빈 배열 반환
public Cheese[] getCheeses() {
return cheesesInStock.toArray(new Cheese[0]);
}
빈 배열도 매번 새로 할당하지 않고 재사용할 수 있다.
1
2
3
4
5
6
// 최적화 버전: 빈 배열 재사용
private static final Cheese[] EMPTY_CHEESE_ARRAY = new Cheese[0];
public Cheese[] getCheeses() {
return cheesesInStock.toArray(EMPTY_CHEESE_ARRAY);
}
toArray 메서드는 입력 배열이 충분히 크면 그 배열에 채워 반환하고, 충분히 크지 않으면 새 배열을 할당해 반환한다.
따라서 EMPTY_CHEESE_ARRAY를 전달하면
- 재고가 없을 때:
EMPTY_CHEESE_ARRAY를 그대로 반환 (할당 없음) - 재고가 있을 때: 새 배열을 할당해 반환
잘못된 최적화 패턴 주의
다음과 같은 코드를 작성하지 말라.
1
2
3
4
// 나쁜 예: 잘못된 최적화
public Cheese[] getCheeses() {
return cheesesInStock.toArray(new Cheese[cheesesInStock.size()]);
}
이 코드는 toArray에 미리 크기를 맞춘 배열을 넘긴다. 얼핏 보면 효율적일 것 같지만, 실제로는 성능을 해칠 수 있다. 최신 JVM은 길이 0인 배열을 전달받으면 내부적으로 최적화된 경로를 사용한다.
1
2
// 권장: 길이 0인 배열 전달
return cheesesInStock.toArray(new Cheese[0]);
실제 Java API의 사례
Java 표준 라이브러리는 이 원칙을 철저히 따른다.
Collections Framework
1
2
3
4
5
6
7
8
9
10
11
public interface Collection<E> {
// 빈 컬렉션을 반환할 수 있지만 null은 반환하지 않음
Object[] toArray();
<T> T[] toArray(T[] a);
}
public class ArrayList<E> {
public Object[] toArray() {
return Arrays.copyOf(elementData, size); // 빈 배열 가능
}
}
ArrayList.toArray()는 원소가 없어도 길이 0인 배열을 반환하지, null을 반환하지 않는다.
Stream API
1
2
3
4
5
List<String> list = Stream.of("a", "b", "c")
.filter(s -> s.length() > 5) // 모든 원소가 필터링됨
.collect(Collectors.toList()); // 빈 리스트 반환, null 아님
System.out.println(list.isEmpty()); // true, NPE 없음
Stream의 수집 연산은 결과가 없어도 항상 빈 컬렉션을 반환한다.
String.split()
1
2
3
4
String str = "hello";
String[] parts = str.split(","); // 구분자가 없음
System.out.println(parts.length); // 1 (원본 문자열 하나), null 아님
Files.lines()
1
2
3
try (Stream<String> lines = Files.lines(Paths.get("empty.txt"))) {
long count = lines.count(); // 0, null이나 예외가 아님
}
빈 파일을 읽어도 빈 스트림을 반환하지 null을 반환하지 않는다.
실전 패턴과 권장사항
패턴 1: 컬렉션은 Collections.emptyXXX() 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public List<Order> getRecentOrders(Customer customer) {
List<Order> orders = findOrders(customer);
return orders != null && !orders.isEmpty()
? orders
: Collections.emptyList();
}
public Set<String> getTags(Article article) {
Set<String> tags = article.getTags();
return tags != null && !tags.isEmpty()
? tags
: Collections.emptySet();
}
public Map<String, String> getMetadata(File file) {
Map<String, String> metadata = extractMetadata(file);
return metadata != null && !metadata.isEmpty()
? metadata
: Collections.emptyMap();
}
패턴 2: 배열은 상수로 선언한 빈 배열 재사용
1
2
3
4
5
6
7
8
public class UserRepository {
private static final User[] EMPTY_USER_ARRAY = new User[0];
public User[] findByName(String name) {
List<User> users = queryByName(name);
return users.toArray(EMPTY_USER_ARRAY);
}
}
패턴 3: Optional과의 조합
컬렉션이나 배열을 Optional로 감싸지 말라. 이중 포장이 되어 불필요하게 복잡해진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 나쁜 예: Optional로 감싼 컬렉션
public Optional<List<Cheese>> getCheeses() {
return Optional.ofNullable(
cheesesInStock.isEmpty() ? null : new ArrayList<>(cheesesInStock)
);
}
// 클라이언트 코드도 복잡해짐
Optional<List<Cheese>> optionalCheeses = shop.getCheeses();
List<Cheese> cheeses = optionalCheeses.orElse(Collections.emptyList());
// 좋은 예: 그냥 빈 컬렉션 반환
public List<Cheese> getCheeses() {
return new ArrayList<>(cheesesInStock);
}
// 클라이언트 코드가 간결
List<Cheese> cheeses = shop.getCheeses();
Optional은 결과가 없을 수 있음을 명시적으로 표현하기 위한 것이다. 컬렉션과 배열은 이미 빈 상태로 “결과 없음”을 표현할 수 있으므로 Optional이 불필요하다.
패턴 4: 불변 컬렉션 활용 (Java 9+)
Java 9 이상에서는 List.of(), Set.of(), Map.of()를 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
// Java 9+
public List<Cheese> getCheeses() {
return cheesesInStock.isEmpty()
? List.of() // 불변 빈 리스트, 할당 없음
: List.copyOf(cheesesInStock); // 불변 복사본
}
public Set<String> getTags() {
return tags.isEmpty()
? Set.of() // 불변 빈 셋
: Set.copyOf(tags);
}
List.of()와 Set.of()는 Collections.emptyList(), Collections.emptySet()과 유사하게 싱글턴 빈 컬렉션을 반환한다.
성능 측정: null vs 빈 컬렉션
실제로 성능 차이가 얼마나 될까? 간단한 벤치마크를 작성해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
import java.util.*;
public class PerformanceTest {
private static final int ITERATIONS = 10_000_000;
private static final List<String> EMPTY = Collections.emptyList();
public static void main(String[] args) {
// 테스트 1: null 반환
long start1 = System.nanoTime();
for (int i = 0; i < ITERATIONS; i++) {
List<String> result = returnsNull();
if (result != null) {
result.size();
}
}
long time1 = System.nanoTime() - start1;
// 테스트 2: 빈 컬렉션 반환 (매번 생성)
long start2 = System.nanoTime();
for (int i = 0; i < ITERATIONS; i++) {
List<String> result = returnsNewEmpty();
result.size();
}
long time2 = System.nanoTime() - start2;
// 테스트 3: 빈 컬렉션 반환 (재사용)
long start3 = System.nanoTime();
for (int i = 0; i < ITERATIONS; i++) {
List<String> result = returnsSharedEmpty();
result.size();
}
long time3 = System.nanoTime() - start3;
System.out.println("null 반환: " + time1 / 1_000_000 + "ms");
System.out.println("빈 리스트 매번 생성: " + time2 / 1_000_000 + "ms");
System.out.println("빈 리스트 재사용: " + time3 / 1_000_000 + "ms");
}
private static List<String> returnsNull() {
return null;
}
private static List<String> returnsNewEmpty() {
return new ArrayList<>();
}
private static List<String> returnsSharedEmpty() {
return EMPTY;
}
}
실행 결과 (환경에 따라 다를 수 있음):
1
2
3
null 반환: 3ms
빈 리스트 매번 생성: 62ms
빈 리스트 재사용: 4ms
빈 컬렉션을 재사용하면 null 반환과 성능이 거의 동일하다. null 반환과 빈 컬렉션 재사용의 차이는 1ms에 불과하다. 반면 빈 리스트를 매번 생성하더라도 1천만 번 반복에 62ms로, 한 번 호출당 6.2 나노초에 불과하다. 이 정도 차이는 실제 애플리케이션에서는 무시할 수 있는 수준이다.
예외 상황은?
거의 모든 경우 빈 컬렉션/배열을 반환하는 것이 맞지만, 극히 드문 예외가 있을 수 있다:
1. 대용량 데이터 처리에서 메모리가 정말 중요한 경우
수억 개의 객체를 다루고 메모리가 정말 부족한 상황이라면, null 반환을 고려할 수 있다. 하지만 이런 경우에도 먼저 측정하라. 빈 컬렉션 할당이 정말 병목인지 확인하라.
2. 명시적으로 “초기화되지 않음”을 표현해야 하는 경우
컬렉션이 “비어있음”과 “아직 로드되지 않음”을 구분해야 한다면 다른 설계를 고려하라.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 이런 경우는 Optional 사용 고려
public class LazyLoadedData {
private List<Item> items; // null = 아직 로드 안 됨, 빈 리스트 = 로드했지만 비어있음
public Optional<List<Item>> getItemsIfLoaded() {
return Optional.ofNullable(items);
}
public List<Item> getItems() {
if (items == null) {
items = loadItems(); // 지연 로딩
}
return items; // 절대 null이 아님
}
}
하지만 이런 경우에도 getItems()는 빈 리스트를 반환해야 한다.
마치며
null이 아닌 빈 컬렉션이나 배열을 반환하라. 이는 단순한 코딩 스타일의 문제가 아니라, API 설계의 핵심 원칙이다.
null을 반환하면 클라이언트는 항상 방어 코드를 작성해야 하고, 방어 코드를 빼먹으면 NullPointerException이 발생한다. 반면 빈 컬렉션을 반환하면 클라이언트 코드가 간결해지고 오류 가능성이 줄어든다.
성능 걱정은 기우다. 빈 컬렉션 할당 비용은 무시할 수 있는 수준이고, 정말 걱정된다면 Collections.emptyList() 같은 불변 빈 컬렉션을 재사용하면 된다. 배열도 마찬가지로 상수로 선언한 빈 배열을 재사용할 수 있다.
Java의 모든 주요 API는 이 원칙을 따른다. Collections Framework, Stream API, 파일 I/O 등 모두 결과가 없을 때 null이 아닌 빈 컬렉션/배열을 반환한다. 우리도 이 원칙을 따라 사용하기 쉽고 오류가 적은 API 를 만들자.
References
- 이펙티브 자바 3/E