Hashing, 해싱 (feat. codetree)
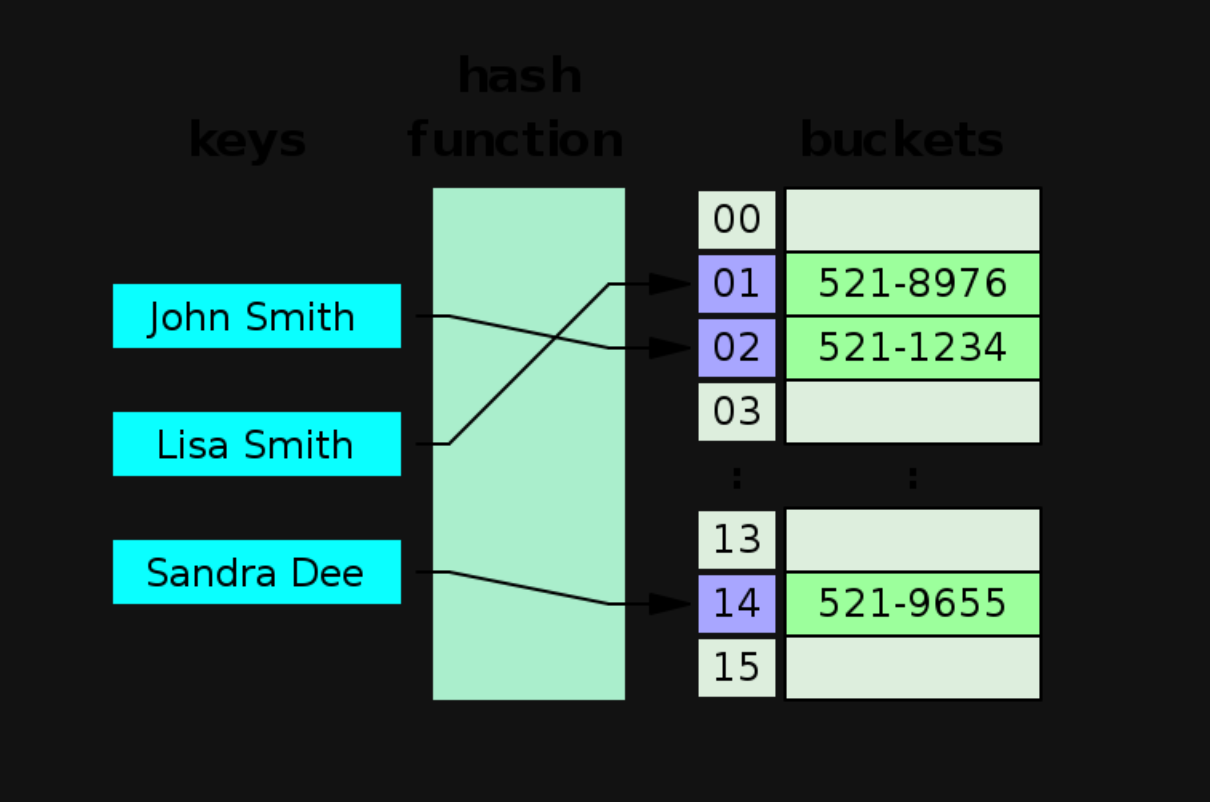
Hashing 에 대한 학습 내용을 정리하고자 한다. 학습은 코드트리의 과정으로 진행되었다.
Hashing, 해싱이란
Why do we need to know?
배열에서 값을 찾을 때 인덱스와 같이 값이 있는 위치를 명시하여 그 값을 찾는다. 실제 데이터 관리/접근/조회 및 웹 사이트에서 다루는 경우 이는 최적의 방법은 아니다.
예시로 홈페이지 로그인을 생각해보자. 홈페이지 로그인 request로는 보통 아이디와 비밀번호가 필요하고, 로그인 시 아이디-비밀번호를 입력하면 서버에 저장된 아이디 비밀번호와 비교하여 일치하는지 확인하는 작업을 거칠것이고, 그 결과값에 따라 로그인 성공 실패 여부를 쳐리할 수 있다. 이때, 어떻게 아이디와 비밀번호를 찾는 방법은 어떤것이 있을까?
-
첫번째 방법으로는 아이디 - 비밀번호를 쌍으로 묶어 저장하는 방식이 있다. 특정 아이디와 특정 비밀번호를 고유 값으로 갖는 쌍의 데이터를 찾아 일치 여부를 확인하는 것이다. 하지만 이 방법의 단점은 대소관계 명시가 어렵다는 점이다. 로그일을 할 때 모든 아이디-비밀번호 쌍을 검색하여 일치정보를 찾는것은 당연히 비효율적이며 값에 특수문자 등이 포함된다면 정렬하기 매우 어려울 것 입니다.
-
이를 극복하기 위해 만든 두번째 저장 방법이 바로 해싱입니다.
Hashing
해시 함수란 임의의 데이터를 받아, 해당 데이터를 고정된 길이의 특정 값으로 반환하는 함수다. 어떠한 값을 넣더라고 특정 범위에 해당하는 값을 반환한다. 이때 해시함수의 반환값을 0이상의 정수를 반환하도록 설정한다면 배열의 인덱스에 해당하는 값을 저장하는 방식을 택할 수 있다.
 이러한 저장 방식을 통해 값을 저장/관리하게되면 CRUD(삽입, 조회, 삭제)를 모두 해시함수 한번을 사용하면 가능하기 때문에 시간복잡도는 O(1)이 된다.
이러한 해시함수의 한계점은 대응할 수 없는 타입이 존재한다는 점이다. 해시함수를 사용할 때 문자열, 숫자, 등 각 타입에 맞는 해시함수가 존재하고 이를 적절하게 골라 사용하게 되는데 배열과 같이 내부에 값이 몇개 존재하는지 불분명한 경우 해시함수에서 사용할 수 없다. 해시함수에서는 배열과 같은 타입을 다루지 않기 때문이다.
그렇다면 해싱은 사용처가 매우 명확해진다. 해싱은 다룰 수 있는 타입의 특정 데이터가 들어온 순서에 상관 없이 CRUD 작업을 할 때 사용하기 좋다.
하지만 항상 문자열 관련으로 해싱을 사용한다는 뜻은 아니고, 배열의 매우 강력한 특성인 index 기반 데이터 정렬을 사용할 경우는 배열이 필요하고, 순서 상관없이 각 데이터가 자주 들어오고 나가는 경우는 해싱이 꼭 필요하다.
이러한 저장 방식을 통해 값을 저장/관리하게되면 CRUD(삽입, 조회, 삭제)를 모두 해시함수 한번을 사용하면 가능하기 때문에 시간복잡도는 O(1)이 된다.
이러한 해시함수의 한계점은 대응할 수 없는 타입이 존재한다는 점이다. 해시함수를 사용할 때 문자열, 숫자, 등 각 타입에 맞는 해시함수가 존재하고 이를 적절하게 골라 사용하게 되는데 배열과 같이 내부에 값이 몇개 존재하는지 불분명한 경우 해시함수에서 사용할 수 없다. 해시함수에서는 배열과 같은 타입을 다루지 않기 때문이다.
그렇다면 해싱은 사용처가 매우 명확해진다. 해싱은 다룰 수 있는 타입의 특정 데이터가 들어온 순서에 상관 없이 CRUD 작업을 할 때 사용하기 좋다.
하지만 항상 문자열 관련으로 해싱을 사용한다는 뜻은 아니고, 배열의 매우 강력한 특성인 index 기반 데이터 정렬을 사용할 경우는 배열이 필요하고, 순서 상관없이 각 데이터가 자주 들어오고 나가는 경우는 해싱이 꼭 필요하다.
정리
Hashing의 특징
- 배열에 비해, 삭제 연산의 시간복잡도가 더 빠르다.
- 이중 연결 리스트에 비해, 탐색 연산이 시간복잡도가 더 빠르다.
- 삽입 삭제, 탐색에 걸리는 시간이 전부 O(1)이다.
- 해싱은 순서가 정해져 있지 않은 데이터를 처리하기에 적합하다.
해시 함수와 충돌
해시함수충돌에 들어가기에 앞서 언급한 해시 함수의 반환값을 0이상 정수로 만들어 배열의 인덱스와 연결하는 작업에 대해 자세히 알아보자.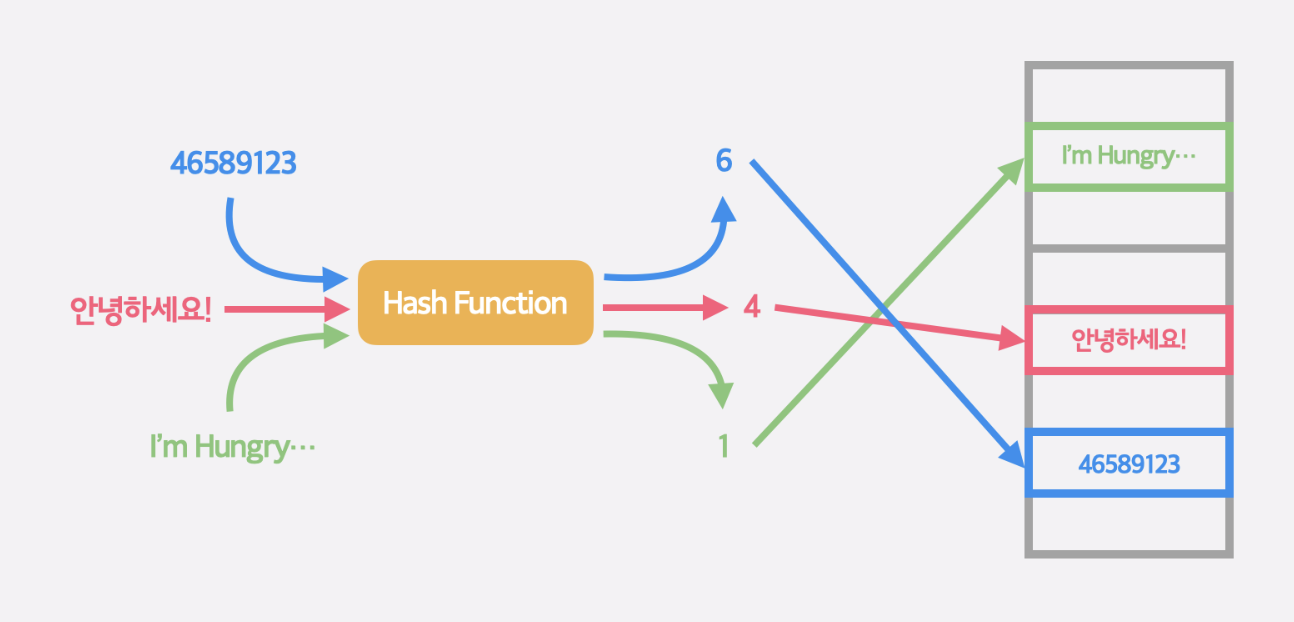 이 상황에서 길이가 10인 배열과 예시 해시 함수로
이 상황에서 길이가 10인 배열과 예시 해시 함수로 f(x) = x라는 해시함수를 생각해보자. 그 결과 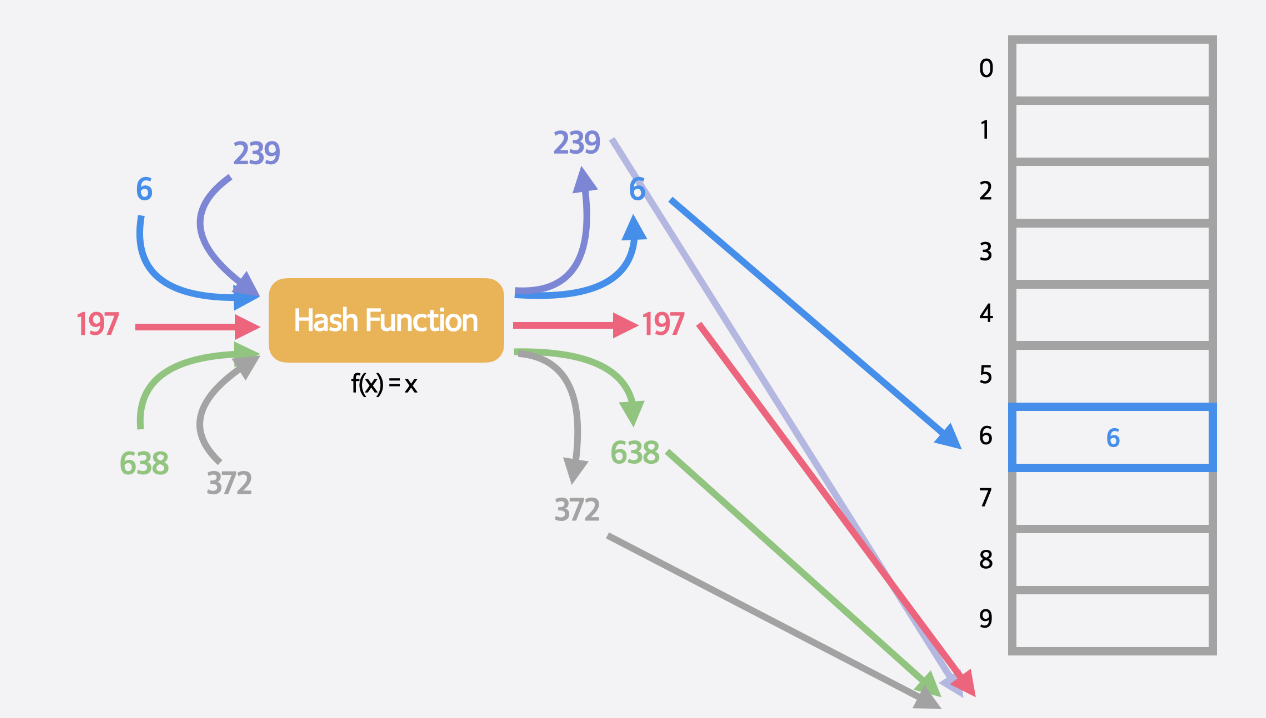 다음과 같이 누락되는 정보가 생긴다. 그럼 다음과 같이 해시함수를 바꿔보자
다음과 같이 누락되는 정보가 생긴다. 그럼 다음과 같이 해시함수를 바꿔보자
f(x) = x % 10; 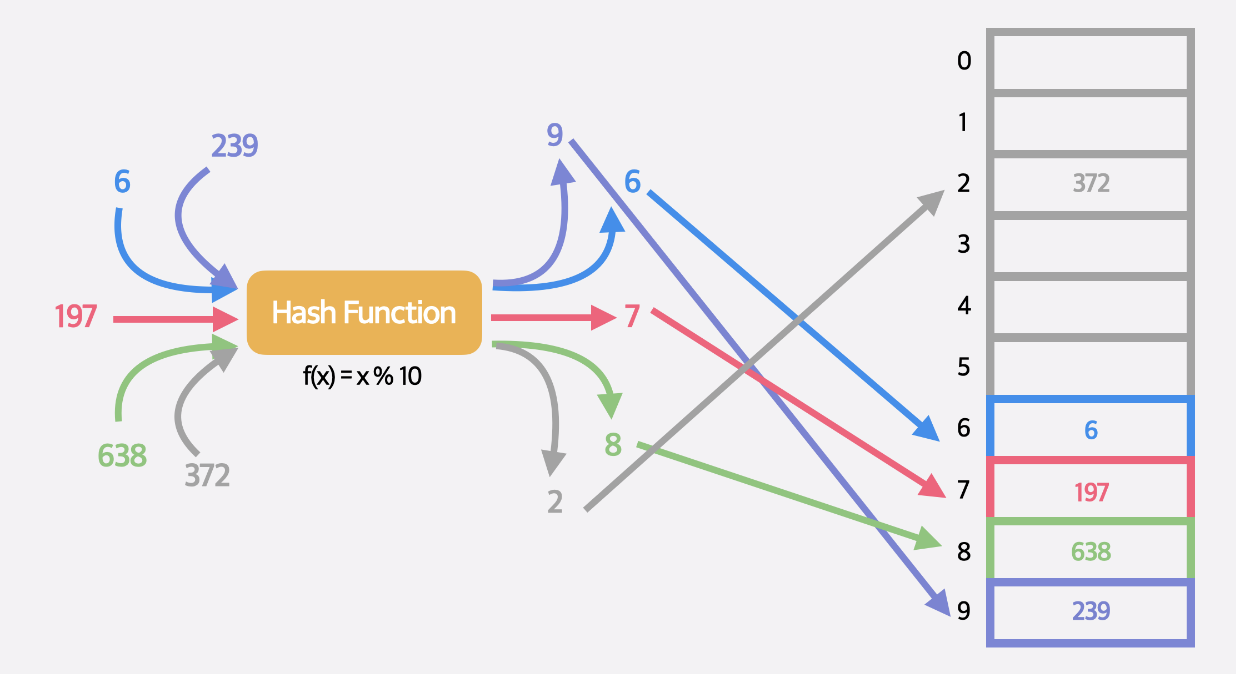 그러면 모든 값을 0~9 인덱스에 할당 시킬 수 있다. 하지만 새로운 문제점이 발생한다. 한 인덱스에 여러 값이 들어가는 상황이 발생할 수 있기때문이다. 우리는 이를 해시 충돌 이라고 한다.
그러면 모든 값을 0~9 인덱스에 할당 시킬 수 있다. 하지만 새로운 문제점이 발생한다. 한 인덱스에 여러 값이 들어가는 상황이 발생할 수 있기때문이다. 우리는 이를 해시 충돌 이라고 한다.
해시 충돌을 해결하기 위해 연결리스트를 사용한다.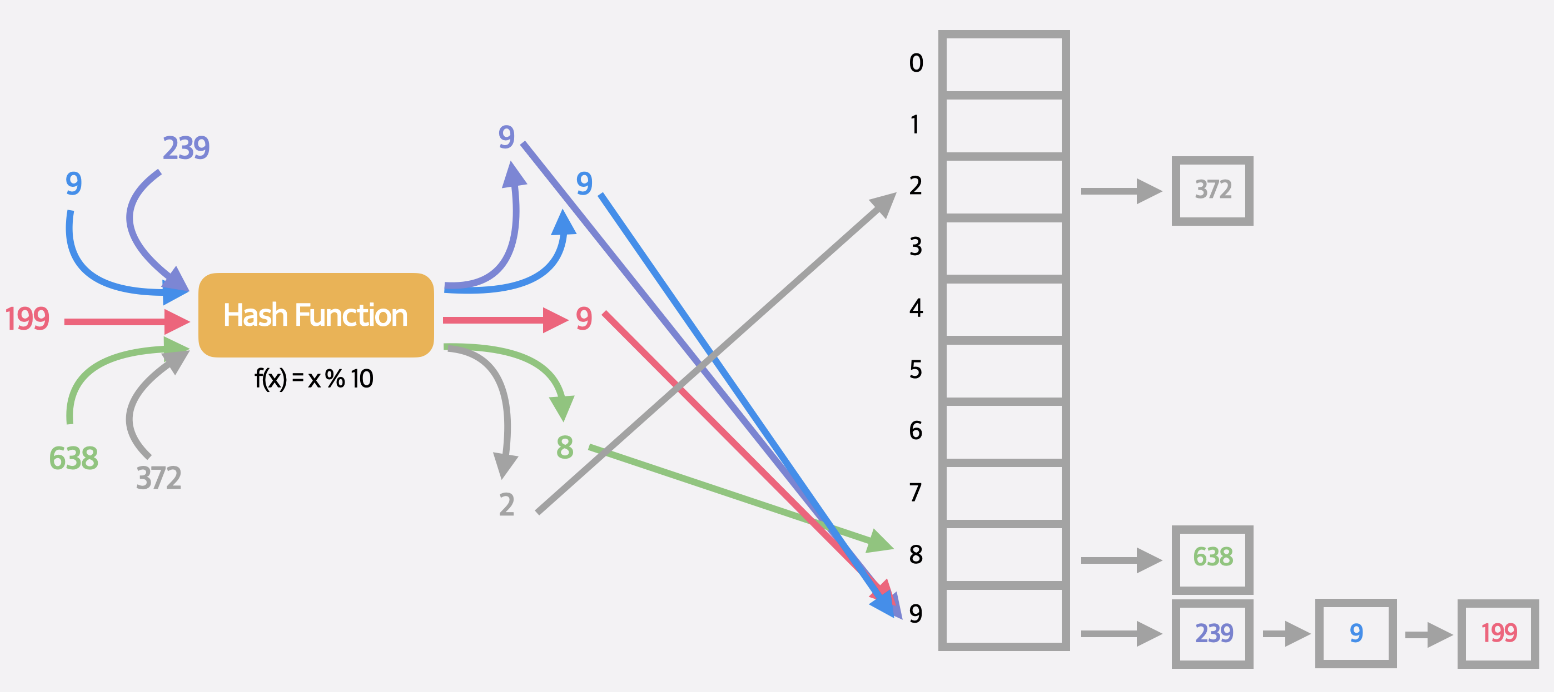 이렇게 연결리스트를 통해 값을 저장하는 부분은 해결했지만 데이터를 조회할 때는 연결리스트를 순회해야하기 때문에 O(N)의 시간복잡도를 갖게 된다.
이렇게 연결리스트를 통해 값을 저장하는 부분은 해결했지만 데이터를 조회할 때는 연결리스트를 순회해야하기 때문에 O(N)의 시간복잡도를 갖게 된다.
그렇기 때문에 해시 함수를 적절하게 만들어 해시 충돌이 최대한 덜 일어나도록 조정해야한다. 해시 충돌이 거의 일어나지 않으면 해시 함수의 반환값을 이용해 바로 조회, 삽입, 삭제가 가능하며 이 경우에서야 비로소 O(N)의 시간복잡도를 가진다고 할 수 있다. 각 프로그래밍 언어마다 이미 구현되어있는 해시함수는 이를 만족한다고 봐도 무방하다! 또한 해시 충돌을 최대한 줄이기 위해 값이 들어갈 배열 (해시 테이블)의 크기를 미리 크게 정의한다. 일반적으로 들어갈 최대 데이터의 3~4배 정도의 크기로 설정한다.
해시 충돌 정리
- 해시 함수에서 충돌이 발생하게 되면 그만큼 삽입/삭제/검색 시간이 증가한다.
- 해시 테이블의 크기를 키우면 충돌은 상대적으로 줄어드나, 메모리를 그만큼 많이 차지하게 된다.
해시 충돌과 효율성
해시 충돌은 성능에 얼마나 악영향을 끼칠까? 충돌되는 값들이 연결리스트로 저장되며, 탐색도 연결리스트의 탐색처럼 진행된다고 가정했을때 최악의 경우 삽입, 삭제, 검색의 시간복잡도는 O(N)이 된다.