InnoDB에 대한 탐구 - (1)

InnoDB
Introduction to InnoDB in MySQL 8.0
MySQL에서 사용하는 InnoDB는 높은 가용성과 성능을 보장하기 위해 사용되는 다목적 * 스토리지 엔진이다.
스토리지 엔진 : 데이터베이스 시스템에서 데이터를 저장, 관리, 검색하는 방법을 담당하는 소프트웨어 컴포넌트다. 데이터베이스의 핵심 부분으로, 데이터가 실제로 디스크에 어떻게 저장되고 메모리에서 어떻게 처리되는지 결정한다.
MySQL 8.0에서 기본 스토리지 엔진으로 InnoDB를 사용하며, CREATE TABLE 구문에 ENGINE= 옵션을 추가하여 다른 엔진을 사용하도록 설정할 수 있다.
InnoDB의 주요 장점
-
사용자의 데이터를 보호하기 위해
commit,rollback및crash recovery가 가능한 트랜잭션을 통해 ACID 모델을 지원하는 DML 오퍼레이션 ( 데이터베이스에서 데이터를 조작하기 위한 명령어 )을 제공한다. -
Row-level locking과 오라클 스타일의 consistent read를 사용하여 다중 사용자 환경에서의 동시성(concurrency)과 성능을 높인다.
-
InnoDB테이블은 디스크에 저장되며, 프라이머리 키에 최적화된 인덱스를 제공한다. 모든InnoDB테이블은 프라이머리 키 인덱스를 가지고 있으며, 이들은 모두clustered index이다.clustered index : 찾고자 하는 위치를 알기 때문에 바로 그 위치를 찾는것 Non clustered index : 뒤에 목차에서 찾고자 하는 내용의 위치를 찾고 그 위치로 이동하는 것 ##### clustered index
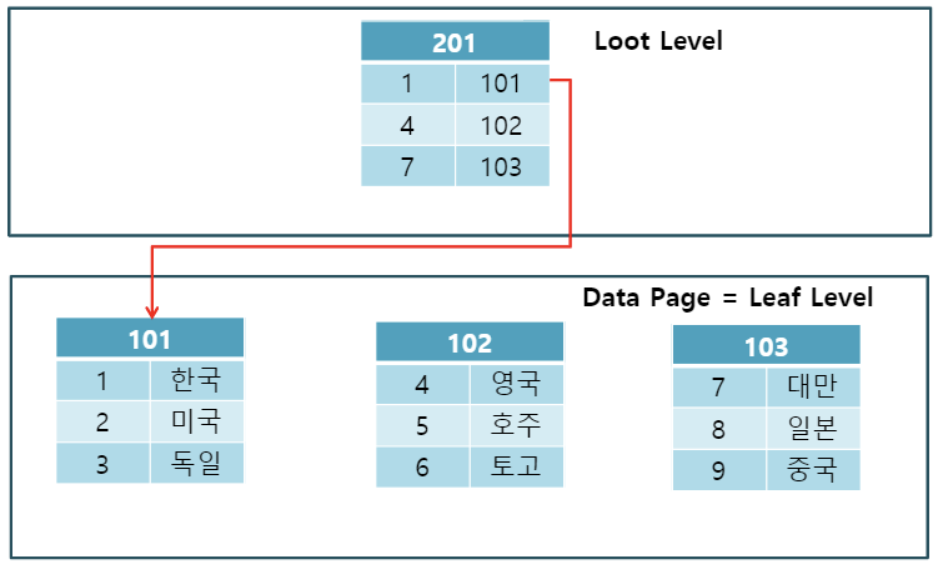
-
데이터의 진실성(integrity)을 보장하기 위해
Foreign key를 지원한다. Foreign key를 사용한 insert/update/delete와 같은 작업들은 연관된 모든 테이블들에 대해서 제약사항을 위반하지 않는 지 자동 검사된다.
| 기능 | 지원 여부 |
| ——————————– | ——————————– |
| B-tree 인덱스 | o 지원 |
| Backup/point-in-time recovery | o 지원 (서버에서 지원함) |
| Cluster 데이터베이스 | x 미지원 |
| Clustered 인덱스 | o 지원 |
| 데이터 압축 | o 지원 |
| 데이터 캐시 | o 지원 |
| 데이터 암호화 | o 지원 (서버에서 지원함) |
| Foreign key | o 지원 |
| Full-text search 인덱스 | o 지원 (MySQL 5.7 이상부터) |
| Geospatial 데이터 타입 | o 지원 |
| Geospatial 인덱싱 | o 지원 (MySQL 5.7 이상부터) |
| Hash 인덱스 | x 미지원 (내부적인 용도로 Adaptive Hash index를 사용하긴 함) |
| Index 캐시 | o 지원 |
| Locking 단위 | Row (행 단위) |
| MVCC | o 지원 |
| Replication (서버 단에서 구현) | o 지원 |
| Storage 제한 | 64TB |
| T-tree 인덱스 | x 미지원 |
| Transaction | o 지원 |
| Data dictionary 에 대한 통계 업데이트 | o 지원 |
InnoDB 사용자를 위한 추가 자료 및 커뮤니티
- InnoDB와 관련된 용어나 정의들을 알고 싶은 경우 [MySQL Glossary]를 참조
InnoDB스토리지 엔진과 관련된 포럼/커뮤니티 사이트는 [MySQL Forums::InnoDB] 참조- InnoDB는 MySQL의 하위 프로젝트로 GNU GPL Licence Version 2를 따름. 이와 관련된 자세한 사항은 [MySQL Licensing] 참조
1.1 InnoDB 테이블의 장점
아래의 여러가지 이유로 인해서 InnoDB 테이블을 사용하길 권장한다.
-
데이터베이스를 사용하는 도중에 소프트웨어/하드웨어적인 어떠한 이유로 인해 서버가 강제 종료 될 경우, 데이터베이스를 다시 사용하기위해 특별한 조치를 취할 필요가 없다. InnoDB의 자체적인 crash recovery (장애 복구) 기술은, 종료 이전의 어떠한 커밋 트랜잭션에 대해서든지 모두 정상 완료됨을 보장한다. 종료 전에 커밋되지 않은 데이터들은 자연스럽게 원래 상태로 되돌린다.
-
InnoDB는 자체적인 buffer pool을 관리하며, 테이블이나 인덱스에 접근할 때 해당 데이터들을 메모리 내에 상주할 수 있도록 한다. 자주 사용되는 데이터의 경우 메모리에서 곧바로 획득할 수 있으며, 단순 데이터가 아닌 다양한 종류의 데이터및 정보들에 대해서도 캐싱을 적용하여 전체 서버의 성능을 높인다. MySQL을 가용하는 데이터베이스 서버의 경우, 실제 물리 메모리의 최대 80% 까지를 InnoDB의 buffer pool 설정하고 사용하는 것이 일반적이다.
-
관련있는 데이터의 집합을 서로다른 여러개의 테이블로 분리할 경우, foreign key를 사용하여 referential integrity (참조 무결성)을 강제할 수 있다. 데이터를 업데이트하거나 삭제할 경우 연관되어 있는 다른 테이블의 데이터도 적절히 업데이트/삭제한다. Secondary 테이블에 데이터를 삽입 하는 경우, primary table에 해당 데이터가 참조하는 키가 존재하지 않을 경우 자동적으로 삽입이 취소된다.
-
데이터가 어떠한 이유로 인해 메모리나 디스크 내에서 내용적인 변화 (오류)가 발생할 경우, checksum을 통해 데이터에 변조 위험이 있음을 사용자에게 알린다.
-
사용자가 적절한 primary key를 사용하여 테이블을 구성한 경우, 해당 컬럼을 참조하는 작업들의 성능이 크게 향상된다. WHERE 절, ORDER BY, GROUP BY 절 및 JOIN 구문에서 Primary key로 지정된 컬럼을 참조하는 경우 처리속도가 매우 빠르다.
-
INSERT, UPDATE, DELETE 는 change buffering 기술로 자동 최적화가 된다. InnoDB는 같은 테이블에 대해 동시 읽기/쓰기를 지원할 뿐만 아니라, 변경된 데이터를 캐싱하여 디스크 I/O를 최소화시킨다.
-
캐싱으로 인한 성능상의 이점은 long running 쿼리가 수행되는 대형 테이블에 대해서만 국한되지 않는다. 한 테이블의 같은 행(row)들이 반복적으로 접근 될 경우, Adaptive Hash Index 기법을 적용하여 반복된 lookup 작업을 해시테이블에서 곧바로 데이터를 가져와, 데이터 탐색작업을 더욱 빠르게 수행한다.
-
테이블과 인덱스들을 압축할 수 있다.
-
인덱스의 생성과 삭제 작업이 성능과 가용성에 미치는 영향을 최소화한다.
-
InnoDB가 직접 스페이스를 관리하는 system tablespace와 달리, file-per-table을 삭제하는 작업은 매우 빠르며, 운영체제의 다른 용도로 사용할 수 있도록 디스크 스페이스의 공간을 비워줄 수 있다.
-
System Tablespace
정의: 하나의 큰 공유 데이터 파일(또는 파일 집합)로, 여러 테이블의 데이터를 저장한다. 파일명: 일반적으로 ibdata1, ibdata2 등
특징: 여러 테이블의 데이터가 하나의 파일에 저장됨 데이터 사전, 언두 로그, 변경 버퍼 등의 시스템 데이터도 저장 테이블을 삭제해도 파일 크기가 줄어들지 않음 (공간 반환 안 됨) 관리가 복잡할 수 있음
-
File-Per-Table Tablespace
정의: 각 InnoDB 테이블이 자신만의 개별 테이블스페이스 파일을 가진다. 파일명: 테이블명.ibd 형식
특징: 테이블별로 별도 파일로 저장됨 테이블을 삭제하면 해당 파일도 완전히 삭제되어 디스크 공간이 운영체제에 즉시 반환됨 테이블별 백업과 복원이 더 쉬움 데이터 관리가 더 유연함 MySQL 8.0부터 기본값으로 설정됨
-
-
DYNAMIC ROW FORMAT 을 사용할 경우, BLOB 데이터와 긴 문자열 필드에 대한 테이블의 스토리지 레이아웃을 더욱 최적화 할 수 있다.
-
INFORMATION_SCHEMA 쿼리를 사용하여 스토리지 엔진의 내부 동작 상황을 모니터링 할 수 있다.
-
Performance Schema 쿼리를 사용하여 스토리지 엔진 성능에 관련된 상세 사항을 모니터링 할 수 있다.
-
MySQL의 다른 스토리지 엔진과 InnoDB 엔진을 섞어서 사용할 수 있으며, 하나의 쿼리 문에 서로다른 엔진을 사용하는 테이블을 섞어 쓸 수도 있다. 예를 들어 JOIN 작업을 사용할 때, InnoDB 엔진을 사용하는 테이블과 MEMORY 엔진을 사용하는 테이블을 동시에 사용할 수 있다.
-
InnoDB는 대용량의 데이터를 사용할 때 최고의 성능을 제공하고, CPU를 효율적으로 사용하도록 설계되었다.
-
InnoDB는 파일 사이즈의 최댓값이 2GB로 제한된 환경의 운영체제에서도 그보다 훨씬 큰 대용량의 데이터를 처리할 수 있다.
InnoDB와 관련된 튜닝 기술은 Optimizing for InnoDB Tables를 참조
1.2 Best Practices for InnoDB Tables
InnoDB 테이블을 사용하는 가장 효율적인 방법
- 테이블을 생성할 때 해당 테이블에서 가장 많이 이용되는 컬럼에 대하여 Primary Key 를 지정한다.
해당하는 컬럼이 없을 경우 Auto-Increment 기능을 사용하여 인덱스를 생성한다.
- 같은 ID 값을 가진 데이터를 여러 테이블에서 가져오고 싶을 때에는 JOIN 을 사용하도록 한다.
조인 쿼리의 성능을 높이기 위해서는 조인 대상이 되는 컬럼을 Foreign key 로 지정하고, 해당 컬럼을 모든 테이블에 대해서 같은 데이터 타입을 갖도록 한다. Foreign key를 추가할 경우 해당 컬럼에 대해 인덱스를 생성하므로 접근 속도가 월등히 빨라지게 된다.
또한, Foreign Key가 존재하는 경우 DELETE / UPDATE 도 자동적으로 연관되어 모든 테이블에 대해 적용하게 되고, INSERT 할 때에는 제약조건 위반 여부를 자동 검사하므로 유용하게 쓰일 수 있다.
-
Autocommit을 끄고 사용해야 한다. 사용하는 저장장치의 쓰기 성능에 따라서 초당 수백번의 커밋은 성능에 안좋은 영향을 미칠 수 있고, 성능상에 한계점을 드러내게 한다.
-
START TRANSACTION과COMMITSQL 구문을 활용하여 연관된 DML 쿼리들을 하나의 transaction으로 묶어서 사용해야 한다. 커밋을 너무 자주 발생시키지 않고 싶을 때 사용해도 좋으며, 정말 긴 시간동안 데이터의 변경을 수행하는 Long running INSERT, UPDATE, DELETE 구문에 대해서 사용해도 좋다. -
LOCK TABLES 쿼리는 최대한 사용하지 말아야 한다. InnoDB는 가용성이나 성능상에 이슈 없이, 자체적으로 여러 세션에서 한 테이블로 요청하는 읽기/쓰기를 모두 알아서 처리 할 수 있다. 나중에 업데이트에 사용될 row들에 대해서 미리 exclusive lock을 걸고 싶은 경우에는 SELECT … FOR UPDATE 쿼리를 사용해서, 테이블이 아닌 해당 row에만 lock을 걸 수 있도록 하자.
##### LOCK TABLES 쿼리 : MySQL에서 명시적으로 테이블 단위의 잠금을 설정하는 구문. 테이블 전체에 READ 또는 WRITE 잠금을 걸 수 있다. LOCK TABLES 테이블명 READ|WRITE;
-
innodb_file_per_table 옵션을 사용하거나, general tablespace를 사용하여 데이터를 저장하고 별도의 파일에 인덱스를 저장하는 방식을 사용해야한다. System tablespace에 데이터를 저장하지 않도록 설정하자.
innodb_file_per_table 옵션은 기본적으로 on 되어 있다.
-
InnoDB를 통해 관리하려는 데이터의 접근 방식이 데이터 페이지의 compression 여부에 따라 영향을 받는지 확인해 보자. Compression이 읽기/쓰기 성능에 큰 영향을 주지 않을것이라고 판단되면 압축기술을 사용하여 공간 낭비를 줄일 수 있다.
-
CREATE TABLE 쿼리에서 사용하는
ENGINE =옵션이 정상적으로 동작하지 않을 경우, 서버를 실행할 때--sql_mode=NO_ENGINE_SUBSTITUTION옵션을 사용해서 InnoDB가 아닌 다른 엔진이 선택되지 않도록 강제 한다.
1.3 InnoDB 다루기
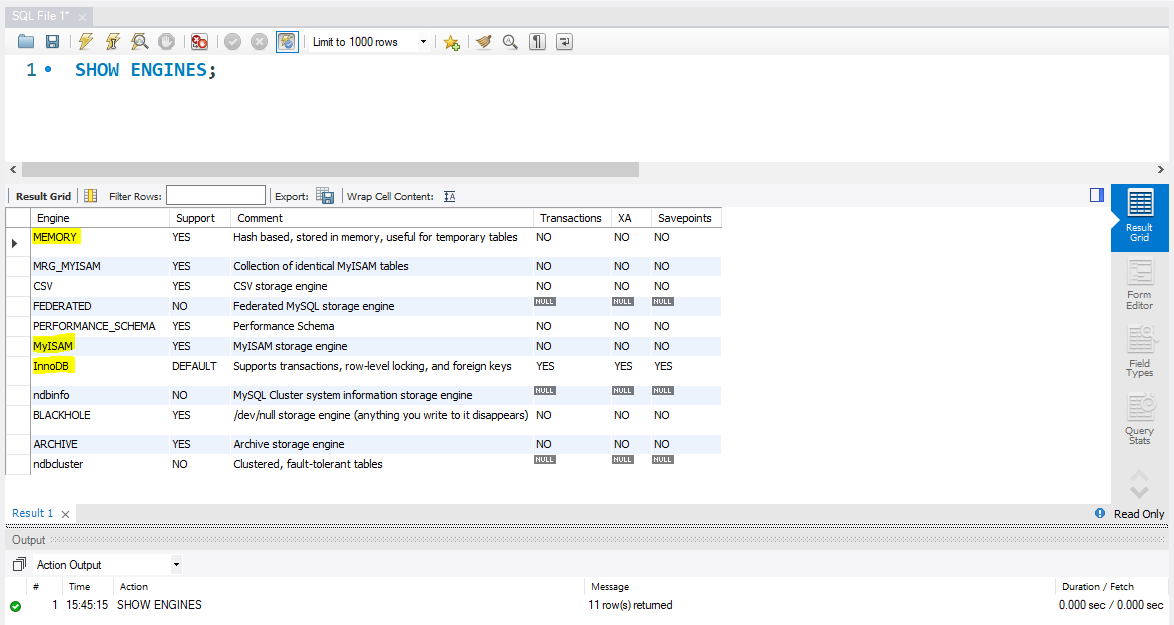
InnoDB가 기본 엔진으로 설정되어 있는지 확인
SHOW ENGINE 쿼리를 사용할 경우 MySQL이 어떤 엔진을 지원하는지 볼 수 있다. InnoDB에 DEFAULT 표시가 되어있는지 확인해보자.
1
SHOW ENGINES;
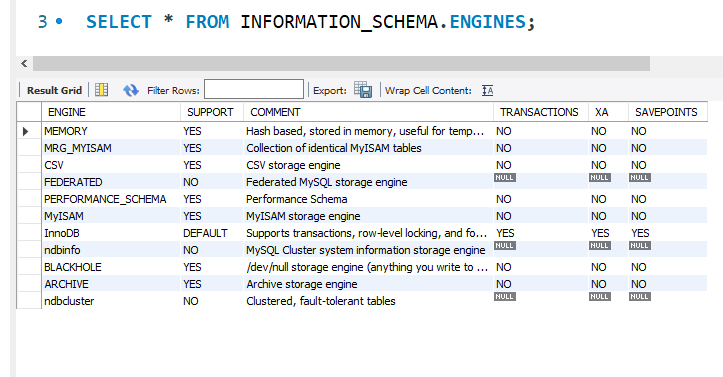
또다른 방법으로는, INFORMATION_SCHEMA.ENGINES를 사용할 수 있다.
1
SELECT * FROM INFORMATION_SCHEMA.ENGINES;
InnoDB를 테스트, 벤치마킹 하는 방법
다른 스토리지 엔진을 사용하던 중 InnoDB로 변경을 고민 할 때, 기존에 사용하던 데이터베이스 서버가 InnoDB 엔진으로도 정상 동작하고 원하는 성능을 나타내는지 궁금할 수 있다.
이때 --default-storage-engine=InnoDB 옵션을 사용해서 서버를 재시작 하거나,
MySQL 옵션 파일의 [mysqld] 섹션에 default-storage-engine=innodb 옵션을 추가 후 재시작 하면 InnoDB를 기본 엔진으로 사용할 수 있다.
사용하던 데이터베이스가 있는 상황에서 스토리지 엔진을 변경하면, 그 이후에 새롭게 생성되는 테이블에 대해서만 바뀐 스토리지 엔진이 적용된다. 모든 테이블을 InnoDB 엔진으로 변경하고 싶은 경우에는, MySQL과 연동되어 있던 모든 애플리케이션에 대한 셋업을 다시 진행해야 한다.
기존에 사용하던 테이블중 일부가 기존 스토리지 엔진의 특수 기능을 의존적으로 사용하는 중이었다면, 해당 테이블에 대한 생성 쿼리에 ENGINE=other_engine_name 옵션을 사용하여 원래 사용하던 스토리지 엔진으로 지정해야 한다.
성급하게 엔진 변경을 하고 싶지 않고, 미리 특정 테이블들이 InnoDB 상에서 어떻게 동작하는지 알아보고 싶은 경우에는 원하는 테이블에 대해서만 ALTER TABLE table_name ENGINE=InnoDB; 쿼리를 실행하여 엔진을 변경하고 테스트 해볼 수 있다.
또는, 기존의 테이블에 일체의 변화를 주지 않은 채로 테스트를 하고 싶은 경우에는 아래의 쿼리를 사용하여 테이블 복사본을 생성하고 InnoDB 엔진을 테스트해볼 수 있다.
1
CREATE TABLE InnoDB_Table (...) ENGINE=InnoDB AS SELECT * FROM other_engine_table;
전체 애플리케이션에 대해서 실제 사용되는 워크로드를 이용해 성능평가를 수행하고 싶은 경우에는 가장 최신 버전의 MySQL 서버를 설치하고 벤치마크를 수행해야 한다.
테스트에는 애플리케이션 전체 생애 주기에 따른 성능 (설치, 기본 셋업, 데이터 로딩 포함)과 과도한 워크로드가 주어졌을 때의 성능 및 서버 재시작이 포함된다. 특수상황에 대한 테스트를 위해서는 데이터베이스가 가동중에 강제로 서버를 종료시켜서 정전 상황에 대비한 테스트를 수행하여, 크래쉬 이후에 데이터베이스가 정상적으로 복구 되는지 확인할 수 있다.
MySQL의 master / slave 옵션을 사용하고 있는 경우에는 다양한 replication 옵션도 테스트해야 한다.
키워드 추가 설명
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
- Master/Slave (마스터/슬레이브):
마스터: 원본 데이터베이스로, 모든 쓰기 작업(INSERT, UPDATE, DELETE)이 이루어짐
슬레이브: 마스터의 복제본으로, 주로 읽기 작업에 사용됨
- Replication (복제):
마스터 데이터베이스의 변경사항을 슬레이브에 자동으로 복사하는 기능
데이터의 백업과 분산 처리를 위해 사용됨
- Binary Log (바이너리 로그):
마스터에서 발생한 모든 변경사항을 기록하는 로그 파일
슬레이브는 이 로그를 읽어 변경사항을 적용함
- Replication 옵션:
Row-based: 변경된 행 데이터 자체를 복제
Statement-based: SQL 문장을 복제
Mixed: 상황에 따라 두 방식을 혼합하여 사용
- Sync/Async (동기/비동기):
비동기 복제: 마스터는 슬레이브의 복제 완료를 기다리지 않음 (기본값)
반동기 복제: 최소 하나의 슬레이브가 복제할 때까지 기다림
2. InnoDB의 ACID
ACID 모델은 비즈니스 데이터나 사업의 핵심 응용 프로그램을 관리하는데 있어서 중요한 데이터베이스의 안정성을 강조하고 보장하는 일련의 데이터베이스 설계 원칙이다.
MySQL은 InnoDB 엔진과 같이 ACID 모델을 철저하게 준수하는 컴포넌트들을 사용해서, 소프트웨어 크래쉬나 하드웨어 오작동으로 인한 예외 상황에서 데이터가 손상되거나 작업 결과가 왜곡되지 않도록 방지한다. 이러한 ACID 모델은 철저히 준수하는 기능을 사용할 경우, 사용하고자 하는 응용프로그램을 위해 새로운 일관성 검사 기능 및 장애 복구 기술을 개발할 필요가 없다. 소프트웨어적인 안전장치, 극도로 신뢰할 수 있는 하드웨어 장치가 있거나 타겟 애플리케이션이 어느정도의 데이터 유실을 감수할수 있는 경우에는, MySQL의 옵션을 통해 ACID 모델 중 일부를 희생하고 응용프로그램의 성능이나 데이터 처리량을 늘릴 수도 있다.
- A : atomicity (원자성)
- C : Consistency (일관성)
- i : isolation (고립성, 독립성)
- D : durability (지속성)
Atomicity
ACID 모델의 atomicity 는 주로 InnoDB의 transaction의 구현을 포함한다. MySQL의 관련 기능들은 아래와 같다.
- Autocommit 옵션
- COMMIT 구문
- ROLLBACK 구문
INFORMATION_SCHEMA테이블의 데이터베이스 운영 관련 데이터
Consistency
ACID모델의 consistency는 주로 데이터가 손상되는것을 방지하기 위해 InnoDB의 내부의 동작방식을 포함한다. MySQL의 관련 기능들은 아래와 같다.
- InnoDB의 doublewrite buffer
- InnoDB의 crash recovery
Isolation
ACID모델의 isolation은 주로 InnoDB의 transaction의 구현을 포함하며, 특히 각 트랜잭션에 적용 되는 isolation level에 의해 정의된다. MySQL의 관련 기능들은 아래와 같다.
- Autocommit 옵션
SET ISOLATION LEVEL구문- InnoDB의 locking 상세 구현. 성능 테스트 중에
INFORMATION_SCHEMA테이블을 통해 확인 가능함.
Durability
ACID모델의 durability는 사용중인 하드웨어와 상호작용하는 MySQL의 소프트웨어 기능을 포함한다. 하드웨어는 사용하는 서버의 CPU, 네트워크, 저장장치의 기능과 구성에 따라서 많은 경우의 수가 존재하므로, 구체적인 가이드라인을 제시하기에 가장 복잡한 기능이다. MySQL의 관련 기능들은 아래와 같다.
- innodb_doublewrite 설정 옵션에 따라 조절되는 InnoDB의 doublewrite buffer
- innodb_flush_log_at_trx_commit 옵션
- sync_binlog 옵션
- innodb_file_per_table 옵션
- HDD, SSD 및 RAID의 저장장치 내부 쓰기 버퍼 (write buffer)
- 저장장치내의 배터리 지원 캐시 (정전으로 인한 데이터 유실 방지)
fsync()시스템 콜을 지원하는 운영체제- UPS (Uninterruptible power supply, 무정전 전원 공급 장치)에 의해 보호되는 MySQL 서버 컴퓨터 및 데이터베이스 저장장치
- 데이터에 대한 다양한 백업 전략 (빈도, 유형, 보존 기간 등)
- 분산형 혹은 호스팅형 응용프로그램의 경우, MySQL서버를 구동하는 하드웨어가 잇는 데이터센터의 특정한 특성과 데이터 센터 간의 네트워크 연결 상태
3. InnoDB Multi-Versioning
InnoDB는 데이터의 멀티 버전을 지원하는 스토리지 엔진 (multi-versioned storage engine)이다. 변경된 row들에 대한 이전 버전의 정보들을 가지고 있으며, 이를 통해서 동시성 제어와 rollback과 같은 트랜잭션 기능들을 제공한다. 이러한 정보들은 테이블 스페이스 내의 rollback segment라고 불리는 자료구조에 저장된다. 트랜잭션 진행 도중 롤백이 필요할 경우 롤백 세그먼트의 데이터 정보를 이용하여 undo 작업을 수행한다. 또한, * consistent read 기능을 제공하기 위해 이전 버전의 데이터를 만드는 데에도 사용한다.
consistent read
1
2
3
4
5
6
7
8
9
10
11
12
일관성 있는 읽기(consistent read)는 쉽게 말해서 "타임머신 읽기"다.
데이터베이스에서 여러 사람이 동시에 작업할 때도, 내가 조회를 시작한 시점의 데이터 상태를 그대로 볼 수 있게 해주는 기능이다.
다른 사람이 그 데이터를 변경하고 있어도, 내가 조회를 시작한 시점의 데이터를 InnoDB가 기억했다가 보여준다.
Ex)
1. 내가 오전 10시에 테이블 조회 시작
2. 다른 사용자가 10시 1분에 데이터 변경
3. 내가 10시 2분에 같은 데이터 다시 조회
4. InnoDB는 나에게 여전히 10시 시점의 원래 데이터를 보여줌
내 작업 도중에 데이터가 갑자기 바뀌는 혼란을 방지하고, 다른 사람의 작업을 기다릴 필요도 없어서 전체적인 성능이 향상된다.
InnoDB 는 내부적으로 데이터베이스에 저장되는 모든 row 각각에 대해 추가적인 3개의 필드를 같이 저장한다.
-
6 바이트 크기의
DB_TRX_ID필드는 해당 row를 추가하거나 업데이트한 가장 마지막 트랜잭션의 ID를 저장한다. row의 삭제 작업 또한 해당 row의 특수 bit를 마크 하는 방식의 업데이트로 취급되므로 앞의 사례에 포함된다. -
7 바이트 길이의
DB_ROLL_PTR필드는 roll 포인터로 불리며, rollback segment내에서 해당 row에 할당된 undo 로그 레코드의 위치를 가리킨다. row가 업데이트된 상황이라면, undo 로그 레코드는 해당 row를 이전 버전으로 되돌리는데 필요한 정보를 포함하고 있다. -
6바이트 길이의
DB_ROW_ID필드는 각 row의 ID를 갖고 있으며, 이 값은 새로운 row가 추가될 때 마다 단순 증가 한다. 사용자가 특별한 인덱스 지정을 하지 않아 InnoDB가 직접 클러스터드 인덱스를 자동 생성 할 경우에 바로 이DB_ROW_ID를 키로 사용한다. 그렇지 않은 경우에는DB_ROW_ID가 지정되지 않는다.
Rollback segment내의 undo 로그들은 insert 로그와 update 로그로 분리된다.
-
Insert 로그는 트랜잭션의 롤백 시에만 필요한 로그이며, 트랜잭션이 커밋하는 순간 바로 삭제 해도 되는 로그이다.
-
Update 로그는 consistent read를 지원하기 위해서 계속 유지될 필요가 있다. Update 로그는 데이터베이스 전체에서 해당 로그가 포함된 스냅샷을 할당 받아서 이전 버전에 대한 consistent read를 요구하는 트랜잭션이 전혀 없는 경우에만 삭제가 가능하다.
다른 작업없이 consistent read를 수행하는 트랜잭션은 주기적으로 커밋을 수행해야 한다. 그렇지 않으면 위와 같은 이유로 update undo 로그를 삭제할수 없어, rollback segment가 매우 커지는 문제가 발생할 수 있다.
1
2
3
4
5
6
7
8
예시)
1. 데이터베이스에서 SELECT만 계속 실행하는 트랜잭션(읽기만 하는 트랜잭션)이 있다고 가정한다.
2. 이 트랜잭션이 시작된 후에 다른 트랜잭션들이 데이터를 많이 변경(UPDATE)했다.
3. 변경된 데이터의 이전 버전은 '언두 로그'라는 곳에 저장되어 있다.
4. 이 읽기 트랜잭션이 오랫동안 커밋하지 않고 계속 실행 중이면, 데이터베이스는 이 트랜잭션이 여전히 '옛날 데이터'를 볼 수 있어야 한다고 생각한다.
5. 따라서 관련된 모든 언두 로그(변경 전 데이터)를 계속 보관해야 한다.
6. 그 결과 롤백 세그먼트(언두 로그가 저장되는 공간)가 계속 커지게 된다.
Rollback segment 내의 undo 로그 레코드의 크기는 일반적으로 실제 insert/update된 row의 크기보다 작다. 이러한 정보를 활용하여 가동중인 데이터베이스에서 실제로 필요한 rollback segment 크기를 계산할 수 있다.
InnoDB의 멀티 버전 관리 체계에서, SQL 쿼리에 의해 삭제된 row는 실제 물리적으로 즉시 삭제되지 않는다. 물리적으로 해당 레코드를 삭제하는 시점은 해당 Delete 쿼리를 위한 undo 로그 레코드가 삭제되는 시점이다.
이러한 삭제 작업을 purge라고 부르며, 실제 Delete SQL 문을 수행했던 시간과 같은 속도로 매우 빠르게 처리된다.
거의 동일한 비율로 insert와 delete를 수행하는 작은 배치 쿼리를 계속해서 수행할 경우, purge를 담당하는 쓰레드가 insert 쓰레드에 뒤쳐지게 되고, 이는 계속해서 남겨지는 “dead” row들 (delete 마크만 되고 삭제되지 않은 row들) 로 인해서 테이블의 크기가 증가하고 모든 작업이 disk-bound가 되어 전체 성능 매우 떨어지는 문제를 일으킨다.
이러한 경우에는 insert에 의한 새로운 row를 생성하는 작업을 제한하고 purge 쓰레드에 더 많은 리소스를 할당하여, disk-bound를 제거해야 한다. 적절한 purge 쓰레드 조절을 위해서는 innodb_max_purge_lag 옵션을 사용하면 되고, “InnoDB Startup Options and System Variables” 문서를 참조하면 더 자세한 내용이 있다.
멀티버전 관리와 Secondary 인덱스
InnoDB의 MVCC (MultiVersion Concurrency Control, 다중 버전 동시성 제어 기법) 는 secondary 인덱스를 메인 클러스터드 인덱스와 다르게 처리한다.
메인 클러스터드 인덱스(기본키 인덱스) 의 경우 update 쿼리에 대한 작업을 in-place(같은 자리에서 바로 수정) 로 처리하고 해당 row에 대해 위에서 언급한 undo 로그 레코드를 가리키는 숨겨진 컬럼을 추가하여 이전 버전의 레코드를 재생성할 수 있도록 한다. Secondary 인덱스의 경우에는 각 row 레코드들에 대해 숨겨진 컬럼을 사용하지도 않고, in-place 업데이트를 수행하지도 않는다.
1
2
3
4
5
6
7
쉽게 설명하자면,
클러스터드 인덱스: 책의 내용을 수정할 때 원래 페이지에 수정하고, 이전 내용은 별도 노트에 기록해두는 방식
수정시 책의 내용과 변경 기록을 함께 보관
세컨더리 인덱스: 색인에서 예전 항목을 지우고 새 항목을 완전히 새로 추가하는 방식
색인만 있고, 원본 기록은 책 본문에서 찾아야 함
Secondary 인덱스의 컬럼이 업데이트 된 경우, 이전 버전의 레코드에는 delete 마크를 표시해두고, 새로운 레코드는 인덱스에 새롭게 insert된다. delete 마크가 표기된 이전 버전의 레코드는 향후에 purge 된다.
한 트랜잭션이 secondary index가 구성되어 있는 특정 컬럼에 대한 값을 얻어 오고자 할 때, 해당 트랜잭션 보다 이후에 시작된 트랜잭션에 의해 secondary 인덱스의 레코드가 delete 되거나 update 된 경우, 원래 자기 트랜잭션의 snapshot에 맞는 이전 버전의 레코드를 가져오기 위해서는 메인 클러스터드 인덱스를 거쳐야 한다.
클러스터드 인덱스에서는 row 레코드들이 DB_TRX_ID를 가지고 있으므로 해당 아이디를 통해, 자신이 원하는 버전의 데이터를 undo 로그 레코드에서 획득하여 이전 버전의 레코드를 재생성 할 수 있다. * Covering index에 대해서도 동일하게 동작한다.
Covering Index
커버링 인덱스(Covering Index)란 쿼리가 요청한 모든 데이터가 인덱스 자체에 포함되어 있어서 테이블 본문을 찾아볼 필요 없이 인덱스만으로 쿼리를 처리할 수 있는 인덱스
ICP (Index condition pushdown) 최적화 (“가능하면 테이블 본문에 안 가고 인덱스만으로 필터링하자”는 최적화) 기술을 사용하는 경우, 원래 기술은 base 테이블을 참조하지 않는 것이지만, MVCC에 의해 secondary 인덱스의 레코드가 수정 (delete/update) 되었음이 확인된 경우에는 메인 클러스터드 인덱스를 추가적으로 접근하여 원하는 버전의 데이터를 재생성하는 작업이 추가된다.
4. InnoDB 구조
각 구조에 대한 정보를 알기 위해서는 InnoDB In-Memory Structures 와 InnoDB On-Disk Structures 섹션을 확인하길 바란다.
InnoDB가 메모리 및 디스크 상에서 관리하는 데이터들의 구성
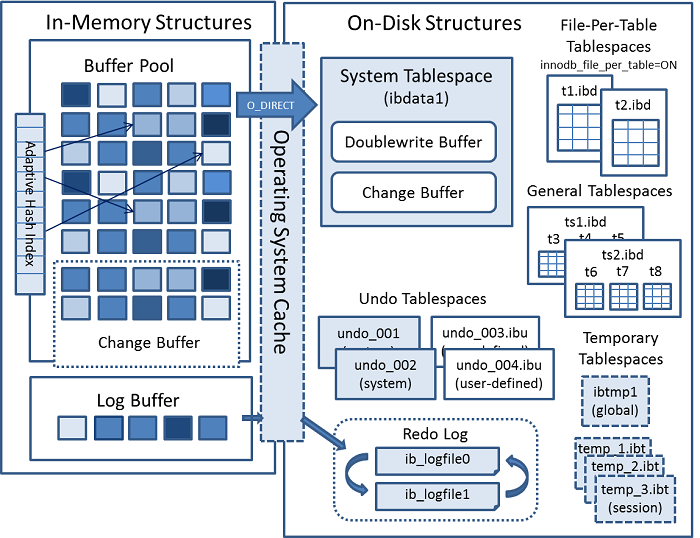
자세한 각 구조에 대해서는 다음 글에서 이어서 작성하겠다.
References
- MySQL 8.0 Reference Manual / The InnoDB Storage Engine
- Clustered vs NonClustered (index 개념)
- 지식덤프 [MySQL Glossary]: https://dev.mysql.com/doc/refman/8.0/en/glossary.html [MySQL Forums::InnoDB]: http://forums.mysql.com/list.php?22 [MySQL Licensing]: http://www.mysql.com/company/legal/licensing/ [other engines]: https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html
- 3 - MySQL 8 InnoDB Storage Engine Architecture Part-1 | MySQL DBA Tutorial | #MySQL 8 DBA #InnoDB