Java Basic Questions (1부)
들어가며
Java의 기본 개념에 대한 공부를 하며 중국어 자료를 한국어로 다시 정리하고자 한다.
기본 개념과 상식
자바 언어의 특징은 무엇인가?
- 배우기 쉽다. (구문이 간단하고 배우기 쉬움)
- 객체 지향 (캡슐화, 상속, 다형성 등)
- 플랫폼 독립성 (Java 가상 머신; JVM은 플랫폼 독립성을 구현한다)
- 멀티스레드 지원 (C++ 언어는 내장된 멀티스레드 메커니즘이 없어서 운영체제의 멀티스레드 기능을 호출해야 하지만, Java 언어는 멀티스레드를 지원한다.)
2011년 C++ 11 부터 C++ 는 Windows, Linux, MacOS에서 스레드를 생성하는데 사용할 수 있는 멀티스레딩 라이브러리를 도입했다. -
std::thread.std::async참고자료 : std::thread - 신뢰성 (예외 처리 및 자동 메모리 관리 메커니즘 포함)
- 보안 (Java 언어 자체 설계에 접근 권한 수정자, 운영체제 자원 직접 접근 제한 등 다중 보안 보호 메커니즘을 제공함)
- 효율성 (Just In Time 컴파일러와 같은 최적화 기술을 통해 Java 언어는 실행 효율이 매우 뛰어남)
- 네트워크 프로그래밍을 지원하며 매우 편리하다.
- 컴파일과 인터프리팅이 공존한다. 10.etc…
나아가서:
“Write Once, Run Anywhere (한 번 작성하면 어디서나 실행 가능)” 이라는 이 슬로건은 고전적이며 수년간 전해져 왔다. 그래서 오늘날에도 많은 사람들은 크로스 플랫폼이 Java 언어의 가장 큰 장점이라고 생각한다. 하지만, 실제로 크로스 플랫폼은 더이상 자바의 가장 큰 장점이 아니며, JDK의 다양한 새로운 기능들도 마찬가지다. 가상화 기술은 이제 매우 발전했다. 예를들어 Docker는 크로스 플랫폼 배포를 더욱 쉽게 만들어준다. Java의 강력한 생태계야 말로 진정한 강점이다!
Java SE vs Java EE
-
Java SE(Java Platform, Standard Edition): Java Platform, Standard Edition은 Java 프로그래밍 언어의 기반이다. Java 애플리케이션의 개발 및 실행을 지원하는 핵심 클래스 라이브러리 및 가상 머신과 같은 핵심 구성 요소를 포함한다. Java SE는 데스크톱 애플리케이션이나 간단한 서버 애플리케이션 개발에 사용될 수 있다.
-
Java EE(Java Platform, Enterprise Edition): Java 플랫폼 엔터프라이즈 에디션으로, Java SE를 기반으로 구축되었으며 엔터프라이즈급 애플리케이션 (ex. Servlet, JSP, EJB, JDBC, JPA, JTA, JavaMail, JMS) 개발 및 배포를 지원하는 표준과 사양을 포함한다. Java EE는 분산, 이식성, 견고성, 확장성 및 보안성을 갖춘 서버 측 Java 애플리케이션 (ex. 웹 애플리케이션) 구축에 사용될 수 있다.
간단히 말해서, Java SE는 Java의 기본 버전이고 Java EE는 Java의 고급 버전이다. Java SE는 데스크톱 애플리케이션이나 간단한 서버 애플리케이션 개발에 더 적합한 반면, Java EE는 복잡한 엔터프라이즈 애플리케이션이나 웹 애플리케이션 개발에 더 적합하다.
Java SE와 Java EE외에도 Java ME(Java Platform, Micro Edition)가 있다. Java ME는 Java의 마이크로 버전으로, 주로 휴대폰, PDA, 셋톱박스, 냉장고, 에어컨과 같은 내장형 가전제품용 애플리케이션 개발에 사용된다. Java ME는 특별히 신경 쓸 필요 없이 존재만 알고있으면 되며, 현재는 사용되지 않는다.
JVM vs JDK vs JRE
JVM
자바 가상 머신 (JVM) 은 자바 바이트코드를 실행하는 가상 머신이다. JVM은 다양한 운영체제 (Windows, Linux, macOS) 에 맞게 구현되어 있다. JVM의 목표는 동일한 바이트코드를 사용하여 동일한 결과를 생성하는 것이다. 바이트코드와 다양한 JVM 구현은 Java 언어의 “한 번 컴파일하면 어디서나 실행 가능” 이라는 핵심 원칙을 가능하게 한다.
아래 그림과 같이, 다양한 프로그래밍 언어 (Java, Groovy, Kotlin, JRuby, Clojure 등) 는 각각의 컴파일러를 통해 .class 파일로 컴파일되고, 최종적으로 JVM을 통해 다양한 플랫폼 (Windows, Linux, Mac)에서 실행된다.
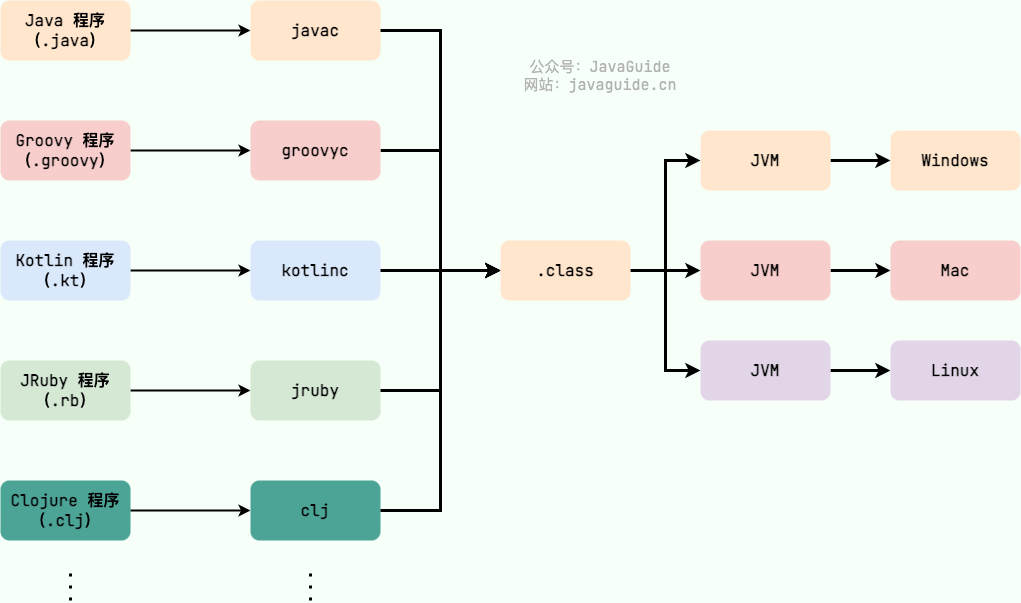
JMV은 단 하나만이 아니다! JVM 사양을 충족하기만 하면 회사, 조직, 개인 등 누구나 자신만의 전용 JVM을 개발할 수 있다. 즉, 우리가 흔히 접하는 HotSpot VM은 JVM 사양의 한 가지 구현체 중 하나이다.
일반적으로 사용되는 HotSpot VM 외에도 J9 VM, Zing VM, JRockit VM 등 다양한 JVM이 존재한다. 위키피디아에서는 주요 JVM 비교표(Comparison of Java virtual machines)가 있으니 참고해보자. 또한 Java SE Specifications에서 각 JDK 버전에 대응하는 JVM 사양을 확인할 수 있다.

JDK 와 JRE
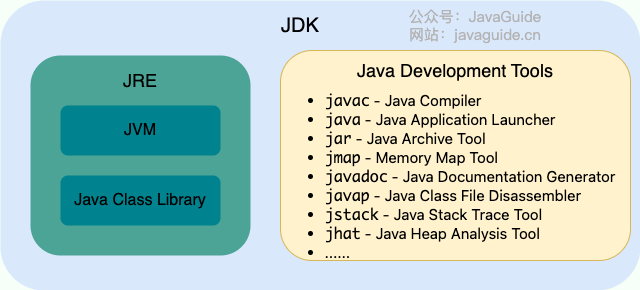
JDK(Java Development Kit)는 개발자가 Java 프로그램을 작성하고 컴파일할 수 있도록 모든 기능을 갖춘 Java 개발 키트다. 여기에는 JRE(Java Runtime Environment)와 컴파일러 javac, javadoc(문서생성기), jdb(디버거), jconsole(모니터링 도구), javap(디컴파일 도구) 등의 기타 도구가 포함되어 있다.
JRE는 컴파일 된 Java 프로그램을 실행하는 데 필요한 환경으로, 주로 다음 두 부분으로 구성된다.
- JVM : 위에서 언급한 Java 가상 머신이다.
- Java 기본 클래스 라이브러리(Class Library) : 일반적으로 사용되는 함수와 API (ex. I/O 작업, 네트워크 통신, 데이터 구조 등) 를 제공하는 표준 클래스 라이브러리 세트다.
간단히 말해서, JRE는 Java 프로그램을 실행하는데 필요한 환경과 클래스 라이브러리만 포함되어 있는 반면, JDK에는 JRE 뿐만아니라 Java 프로그램을 개발하고 디버깅하는 도구도 포함되어 있다.
Java 프로그램을 작성하거나 컴파일하거나 Java API 문서를 사용하려면 JDK를 설치해야한다. Java 기능이 필요한 특정 애플리케이션 (ex. JSP를 서블릿으로 변환하거나 리플렉션을 사용하는 경우) 의 경우 Java 코드를 컴파일하고 실행하기 위해 JDK가 필요할 수 있다. 따라서 Java 개발을 하지 않더라도 JDK를 설치가 필요할 수 있다.
아래 그림은 JDK, JRE, JVM간의 관계를 명확하게 보여준다.
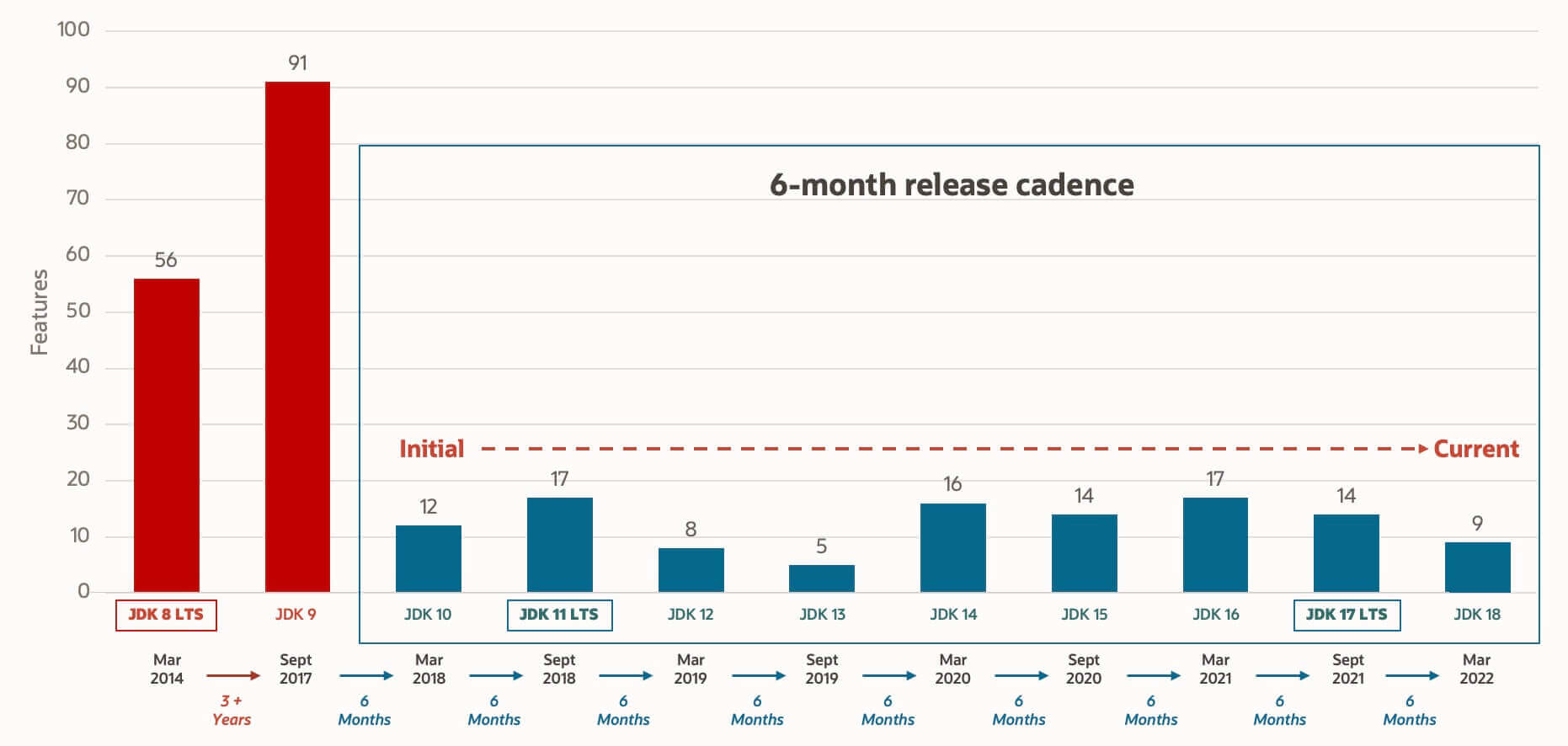
하지만 JDK 9 부터는 JDK와 JRE를 구분할 필요가 없어졌다. 대신 모듈 시스템(JDK는 94개의 모듈로 재구성됨) 과 jlink 도구(Java 9와 함께 출시된 새로운 명령줄 도구로, 특정 애플리케이션에 필요한 모듈만 포함된 사용자 정의 Java 런타임 이미지를 생성함)가 그 자리를 대체했다.
1
2
3
4
5
Java 9 새로운 기능: 모듈 시스템
모듈 시스템이 도입되면서 JDK는 94개의 모듈로 재구성되었다.
Java 애플리케이션은 새로 추가된 jlink 도구를 사용하여 의존하는 JDK 모듈만 포함하는 사용자 정의 런타임 이미지를 생성할 수 있다.
이를 통해 Java 런타임 환경의 크기가 크게 줄어든다.
즉, 모든 애플리케이션에 동일한 JRE를 사용하는 대신, jlink를 사용하면 필요에 따라 더 작은 런타임을 만들 수 있다.
맞춤형 모듈형 Java 런타임 이미지는 Java 애플리케이션 배포를 간소화하고 메모리를 절약하며 보안 및 유지보수성을 강화하는데 도움이 된다. 이는 가상화, 컨테이너, 마이크로 서비스, 클라우드 네이티브 개발과 같은 최신 애플리케이션 아키텍처의 요구사항을 충족하는데 필수적이다.
바이트코드란 무엇인가요? 바이트 코드를 사용하면 어떤 장점이 있나요?
Java에서 JVM이 이해하는 코드를 바이트코드(.class 확장자를 가진 파일) 라고 한다. 이 코드는 특정 프로세서에 국한되지 않고 가상 머신에 종속 된다. Java는 바이트코드를 사용하여 기존 인터프리터 언어의 비효율성을 해결하면서 인터프리터 언어(소스 코드를 한 줄씩 읽고 즉시 실행하는 프로그래밍 언어)의 이식성 특징을 유지한다. 결과적으로 Java 프로그램은 (C, C++, Rust, Go와 같은 언어 비해 여전히 약간의 지연이 있지만) 런타임에 비교적 효율적이다. 또한, 바이트코드는 특정 머신에 종속되지 않기 때문에 Java 프로그램은 재컴파일 없이도 다양한 운영체제의 컴퓨터에서 실행될 수 있다.
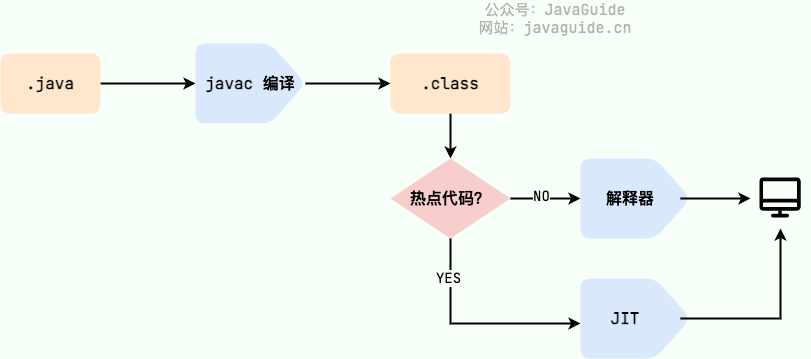
아래 그림은 Java 프로그램이 소스코드에서 실행으로 전환되는 과정이다.
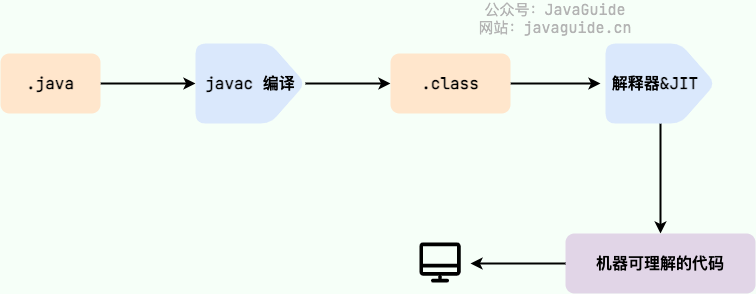
여기서 주의해야할 부분은 .class -> 기계어 단계다. 이 단계에서 JVM 클래스 로더는 먼저 바이트코드 파일을 로드한 후, 인터프리터를 사용해 한 줄씩 해석하고 실행한다. 이 방식은 실행 속도가 비교적 느리다. 또한, 일부 메서드와 코드 블록은 자주 호출되는 (소위 핫스팟 코드) 경우가 많기 때문에, 이후 JIT(Just-In-Time) 컴파일러가 도입되었다. JIT는 런타임 컴파일의 한 유형이다. JIT 컴파일러가 첫 번째 컴파일을 완료하면 해당 바이트코드에 대응하는 기계 코드를 저장하여 다음 번에 바로 사용할 수 있게 한다. 알다시피 기계어는 Java 인터프리터보다 훨씬 효율적이다. 이것이 Java가 컴파일과 해석을 결합한 언어로 자주 언급되는 이유 다.
추가 자료는 다음과 같다: 기본 기술 | Java Just-in-Time 컴파일러 원리 분석 및 실습 - Meituan Technology Team 정적 컴파일 기반 마이크로서비스 애플리케이션 구축 - Alibaba Middleware
HotSpot은 지연 연산 (Lazy Evaluation) 을 사용한다. 파레토 법칙에 따르면, 대부분의 시스템 자원을 소모하는 것은 극히 일부의 코드 (핫스팟 코드) 뿐이며, 바로 이 부분이 JIT가 컴파일해야 할 부분이다. JVM은 코드가 실행될 때마다 정보를 수집하여 최적화를 수행하므로, 실행 횟수가 많을수록 속도가 빨라진다.
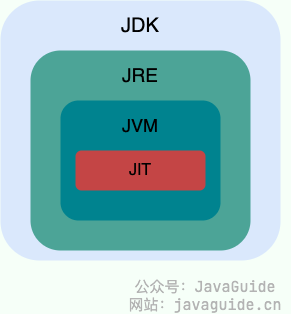
JDK, JRE, JVM, JIT의 관계는 아래 그림과 같다.
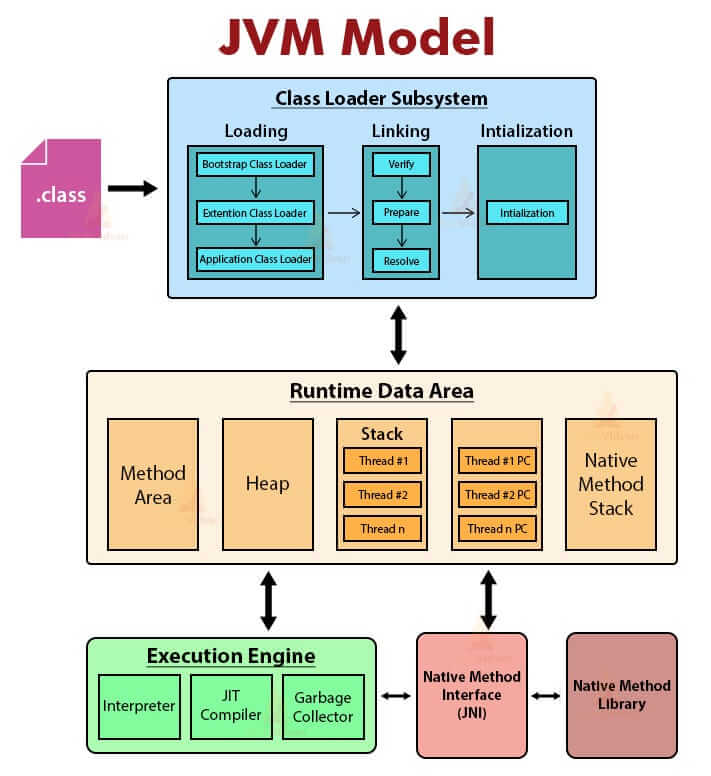
다음 그림은 JVM의 일반적인 구조 모델이다.
왜 Java 언어는 “컴파일과 해석이 공존한다”고 말하는가?
이 문제는 바이트코드에 대해 이야기할 때 언급했지만 매우 중요하기 때문에 다시 짚고 넘어가자.
우리는 고급 프로그래밍 언어를 프로그램 실행 방식에 따라 2가지고 분류할 수 있다.
-
컴파일 언어 : 컴파일 언어는 컴파일러를 사용해 소스코드를 플랫폼에서 실행 가능한 기계어로 변환한다. 일반적으로는 컴파일 언어는 실행 속도는 빠르지만 개발 효율성은 떨어진다. 일반적인 컴파일 언어로는 C, C++, Go, Rust 등이 있다.
-
인터프리터 언어 : 인터프리터 언어는 코드를 실행하기 전에 인터프리터를 사용해 코드를 한 줄씩 기계어로 해석(interpret)한다. 인터프리터 언어는 개발 효율성은 높지만 실행 속도는 느리다. 일반적인 인터프리터 언어로는 Python, JavaScript, PHP가 있다.
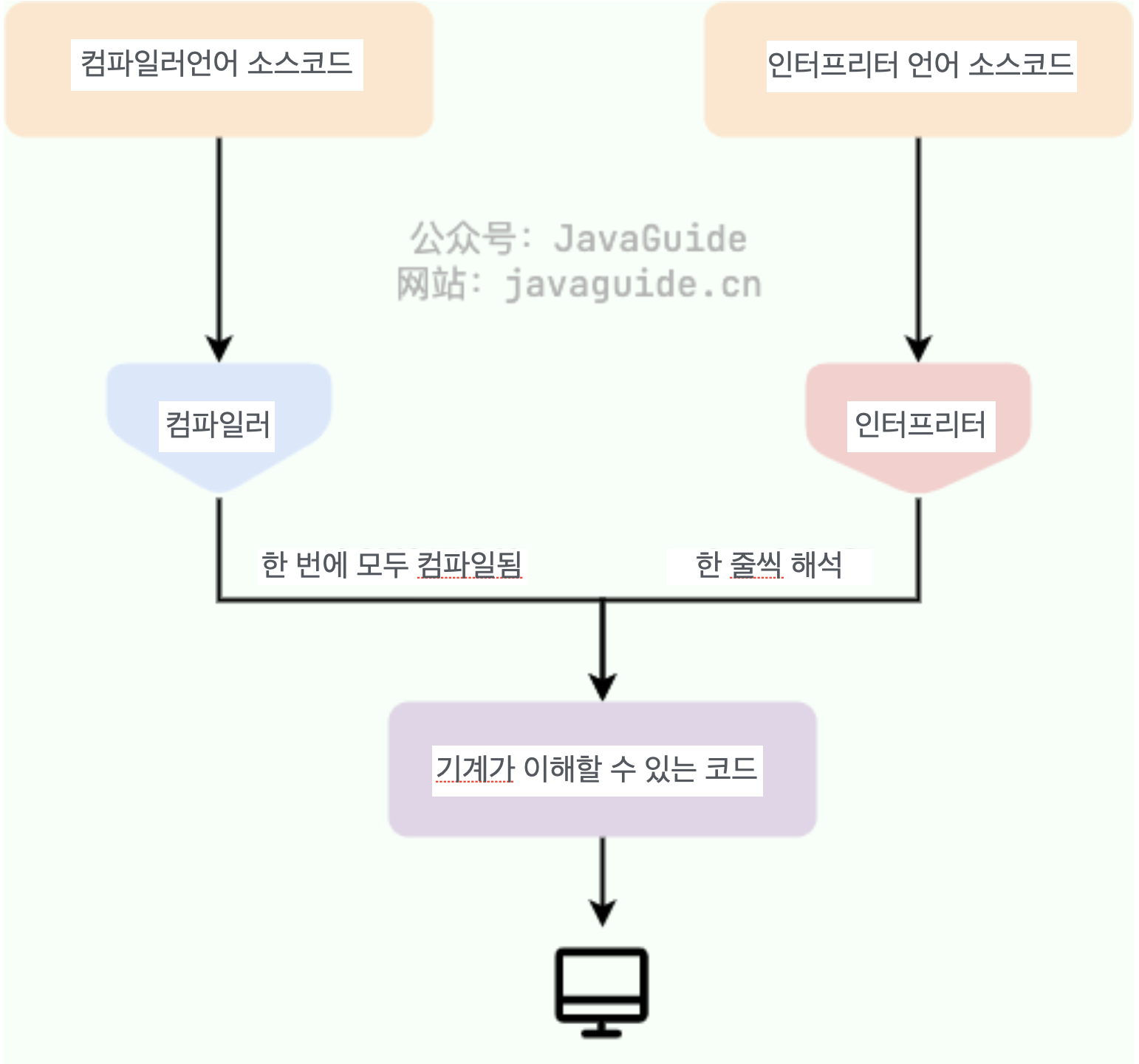
위키피디아에 따르면:
인터프리터 언어의 효율성을 향상시키기 위해 개발된 JITC( Just-in-Time Compilation) 는 두 언어 간의 격차를 줄였다. 이 기술은 컴파일 언어와 인터프리터 언어의 장점을 결합한다. 컴파일 언어와 마찬가지로, JITC는 먼저 프로그램 소스 코드를 바이트코드 로 컴파일한다 . 런타임에 바이트코드는 직접 변환되어 실행된다. Java 와 LLVM이 이 기술의 대표적이다. 관련 자료: 기본 기술 | Java Just-In-Time 컴파일러 원리 분석 및 연습
그래서 왜 Java에서는 “컴파일과 해석이 공존한다”고 할까?
Java는 컴파일 언어와 인터프리터 언어의 특성을 모두 가지고 있기 때문이다. Java 프로그램은 컴파일과 인터프리터의 두 단계를 거친다. Java로 작성된 프로그램은 먼저 바이트코드(.class 파일)를 생성하기 위해 컴파일되어야 한다. 이 바이트코드는 Java 인터프리터에 의해 해석되고 실행되어야 한다.
AOT의 장점은 무엇일까? 왜 모든것에 AOT를 사용하지 않을까?
JDK 9는 새로운 컴파일 모드인 AOT(Ahead of Time Compilation) 를 도입했다. JIT와 달리 이 컴파일 모드는 프로그램 실행 전에 기계어로 컴파일한다. 이는 C, C++, Rust, Go와 같은 언어에서 볼 수 있는 정적 컴파일의 한 형태다. AOT는 JIT 워밍업 오버헤드 등 다양한 측면의 오버헤드를 피할 수 있어 Java 프로그램 시작 속도를 향상시키고 긴 워밍업 시간을 방지한다. 또한 AOT는 메모리 사용량을 줄이고 Java 프로그램 보안을 강화한다(AOT로 컴파일된 코드는 디컴파일 및 수정에 덜 취약하기 때문). 따라서 클라우드 네이티브 환경에 특히 적합하다.
JIT와 AOT의 주요 지표:
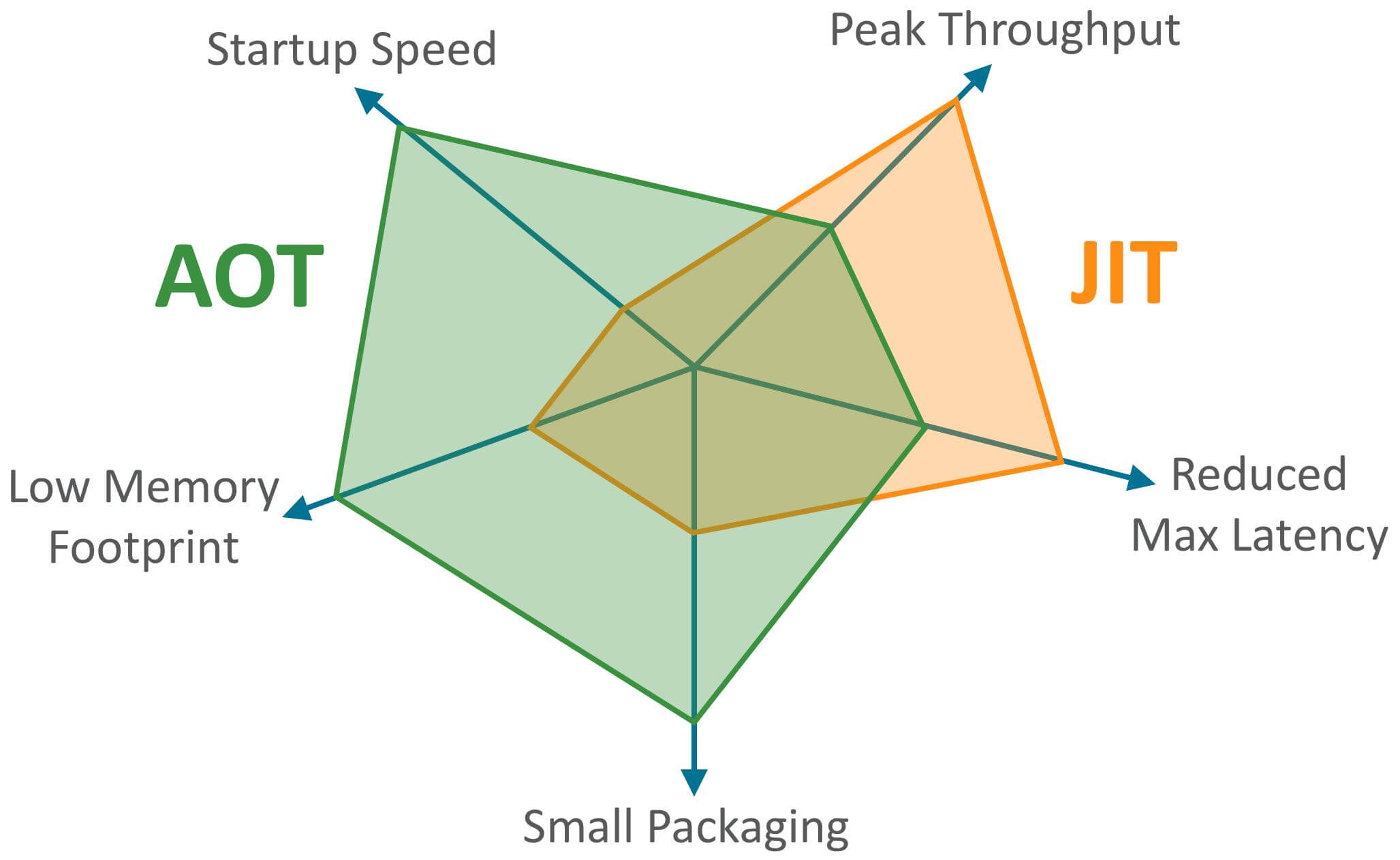
위 그램에서 보다시피 AOT의 주요 장점은 시작 시간, 메모리 사용량, 그리고 패키지 크기다. JIT의 주요 장점은 요청의 최대 지연시간을 줄일 수 있는 뛰어난 처리 능력이다.
AOT에 대해 얘기할 때 GraalVM을 빼놓을 수 없다! GraalVM은 Java 및 기타 JVM 언어는 물론 JavaScript, Python과 같은 비 JVM언어도 실행할 수 있는 고성능 JDK(완전한 JDK 배포 버전)이다. GraalVM은 AOT 컴파일뿐만 아니라 JIT 컴파일도 지원한다.
AOT가 이렇게 많은 장점을 가지고 있는데 왜 이 컴파일 방식을 모든 것에 사용하지 않을까?
이전에 JIT와 AOT를 비교해 본 바, 양측 모두 각자의 장점이 있었다. 다만 AOT가 현재의 클라우드 네이티브 환경에 더 적합하며, 마이크로서비스 아키텍처 지원에도 비교적 유리하다고 할 수 있다. 또한 AOT 컴파일은 리플렉션, 동적 프록시, 동적 로딩, JNI(Java Native Interface) 등 Java의 일부 동적 특성을 지원하지 못한다. 그러나 Spring, CGLIB 같은 많은 프레임워크와 라이브러리가 이러한 특성을 활용한다. AOT 컴파일만 사용하면 해당 프레임워크와 라이브러리를 사용할 수 없거나, 맞춤형 수정 및 최적화가 필요하다. 예를 들어, CGLIB 동적 프록시는 ASM 기술을 활용하는데, 이 기술은 런타임에 수정된 바이트코드 파일(.class)을 생성하여 메모리에 직접 로드한다. 만약 AOT 컴파일만 사용하면 ASM을 사용할 수 없게 된다. 이와 같은 동적 기능을 지원하기 위해 JIT 컴파일러가 사용된다.
Oracle JDK vs OpenJDK
이 질문을 보기 전까지 많은 사람들은 OpenJDK를 접하거나 사용해 본 적이 없을 것이다. 그렇다면 Oracle JDK와 OpenJDK 사이에 어떤 큰 차이가 있을까? 아래 몇가지 자료로 이를 답해보겠다.
첫 번째로, 2006년 Sun Microsystems가 Java를 오픈소스화하여 OpenJDK를 출시했다. 2009년 Oracle은 Sun Microsystems를 인수하여 OpenJDK를 기반으로 자체 버전인 Oracle JDK를 개발했다. Oracle JDK는 오픈소스가 아니며, 초기버전(Java 8부터 11까지)에는 OpenJDK와 차별화된 기능과 도구가 추가되었다.
두 번째로, Java 7 에 있어서 OpenJDK와 Oracle JDK는 매우 가깝다. Oracle JDK는 OpenJDK 7을 기반으로 몇 가지 사소한 기능이 추가되었으며, Oracle 엔지니어가 유지 관리한다.
다음 내용은 2012년 오라클 공식 블로그에서 발췌한 것이다.
Q. OpenJDK 저장소의 소스 코드와 Oracle JDK 빌드에 사용되는 코드 간 차이점은 무엇인가요? A. 매우 유사합니다. 우리의 Oracle JDK 버전 빌드 프로세스는 OpenJDK 7 빌드를 기반으로 하며, 몇 가지 구성 요소만 추가되었습니다. 예를 들어 배포 코드(Oracle의 Java 플러그인과 Java WebStart 구현 포함), 그래픽 렌더러와 같은 일부 비공개 소스 제3자 구성 요소, Rhino와 같은 일부 오픈 소스 제3자 구성 요소, 추가 문서나 제3자 글꼴과 같은 사소한 것들이 포함됩니다. 향후 계획으로는 상업적 기능을 고려한 부분을 제외한 Oracle JDK의 모든 부분을 오픈소스화하는 것이 목표입니다.
마지막으로 Oracle JDK와 OpenJDK의 차이점을 간략하게 요약해보겠다.
- 오픈소스 여부 : OpenJDK는 참조 구현체이며 완전히 오픈소스다. 반면 Oracle JDK는 OpenJDK를 기반으로 구현되었지만 완전히 오픈소스는 아니다.
- 무료 여부 : Oracle JDK는 무료 버전을 제공하지만 일반적으로 시간 제한이 있다. JDK 17 이후 버전은 무료로 배포 및 상업적 사용이 가능하지만, 3년만 허용되며 3년 후에는 무료 상업적 사용이 불가능하다. 다만, JDK 8u221 이전 버전은 업그레이드하지 않는 한 무기한 무료로 사용 가능하다. OpenJDK는 완전히 무료다.
- 기능성 : Oracle JDK는 OpenJDK 기반에 Java Flight Recorder(JFR, 모니터링 도구), Java Mission Control(JMC, 모니터링 도구) 등 고유 기능과 도구를 추가했다. 다만 Java 11 이후 OracleJDK와 OpenJDK의 기능은 거의 동일하며, 이전 OracleJDK의 비공개 구성 요소 대부분도 오픈소스 단체에 기증되었다.
- 안정성 : OpenJDK는 LTS(장기 지원) 서비스를 제공하지 않지만, OracleJDK는 대략 3년마다 LTS 버전을 출시하여 장기 지원을 제공하고 있다. 다만 많은 기업들이 OpenJDK를 기반으로 OracleJDK와 동일한 주기의 LTS 버전을 제공하고 있다. 따라서 두 플랫폼의 안정성은 사실상 비슷하다.
- 라이선스 : Oracle JDK는 BCL/OTN 라이선스로 허가되며, OpenJDK는 GPL v2 라이선스에 따라 허가된다.
Q) Oracle JDK가 그렇게 좋은데, 왜 OpenJDK가 필요할까? A)
- OpenJDK는 오픈 소스이므로 필요에 따라 수정하고 최적화할 수 있다. 예를 들어 알리바바는 OpenJDK를 기반으로 Dragonwell8을 개발했다. https://github.com/alibaba/dragonwell8
- OpenJDK는 상용이며 무료다(yum 패키지 관리자에 Oracle JDK 대신 OpenJDK가 기본으로 설치되는 이유). Oracle JDK도 상용이며 무료이지만(예: JDK 8), 모든 버전이 무료인 것은 아니다.
- OpenJDK는 더 자주 업데이트된다. Oracle JDK는 일반적으로 6개월마다 새 버전을 출시하는 반면, OpenJDK는 일반적으로 3개월마다 새 버전을 출시한다.
위의 이유에 따르면 OpenJDK는 여전히 존재해야 한다!

Java와 C++의 차이점은 무엇인가?
Java와 C++는 모두 캡슐화, 상속, 다형성을 지원하는 객체 지향 언어이지만 여전히 많은 차이점이 있다.
- Java는 메모리에 직접 접근하기 위한 포인터를 제공하지 않으므로 프로그램 메모리가 더 안전하다.
- Java 클래스는 단일 상속을 갖고, C++는 다중 상속을 지원한다. Java 클래스는 다중 상속을 가질 수 없지만, 인터페이스는 다중 상속을 가질 수 있다.
- Java에는 프로그래머가 사용하지 않는 메모리를 수동으로 해제할 필요가 없는 자동 메모리 관리 가비지 수집 메커니즘(GC)이 있다.
- C++는 메서드 오버로딩과 연산자 오버로딩을 모두 지원하지만, Java는 메서드 오버로딩만 지원한다(연산자 오버로딩은 복잡성을 더하는데, 이는 Java의 원래 설계 개념과 일치하지 않는다).
기본 문법
주석에는 어떤 형태가 있을까?
Java에는 세 가지 종류의 주석이 있다.
- 한 줄 주석 : 일반적으로 메서드 내에서 한 줄의 코드의 기능을 설명하는 데 사용된다.
- 여러 줄 주석 : 일반적으로 코드 섹션의 목적을 설명하는 데 사용된다.
- 문서 주석 : 일반적으로 Java 개발 문서(JavaDocs)를 생성하는 데 사용된다. 단일 줄 주석과 문서 주석이 더 일반적으로 사용되고, 다중 줄 주석은 실제 개발에서 비교적 드물게 사용된다.
코드를 작성할 때 코드 양이 적다면 본인이나 팀원들이 쉽게 이해할 수 있지만, 프로젝트 구조가 복잡해지면 주석이 필요해진다. 주석은 실행되지 않는다. 컴파일러는 코드를 컴파일하기 전에 모든 주석을 삭제하며, 바이트코드에는 주석이 유지되지 않는다. 주석은 프로그래머들이 스스로 작성하는 것으로, 코드의 설명서 역할을 하여 코드를 보는 사람이 코드 간의 논리적 관계를 빠르게 파악하는데 도움을 준다. 따라서 프로그램을 작성할 때 주석을 추가하는 것은 매우 좋은 습관이다.
“Clean Code” 라는 책에서는 다음과 같이 명확하게 언급하고 있다.
코드 주석은 자세할수록 좋습니다. 사실, 좋은 코드 자체가 주석입니다. 불필요한 주석을 줄이기 위해 코드를 표준화하고 아름답게 만들어야 합니다. 프로그래밍 언어가 충분히 표현력이 풍부하다면 주석은 필요없고, 코드를 통해 설명하도록 노력하세요. 예를들어 아래의 복잡한 주석을 제거하고 주석에 적힌 것과 동일한 작업을 수행하는 함수만 생성하세요.
위 코드는 아래로 대체되어야 합니다.
식별자와 키워드의 차이점은 무엇일까?
프로그램을 작성할 때 프로그램, 클래스, 변수, 메서드 등에 이름을 붙여야 하므로 식별자가 생겨난다 . 간단히 말해, 식별자는 이름이다 .
자바 언어는 일부 식별자에 특별한 의미를 부여하여 특정 상황에서만 사용할 수 있도록 한다. 이러한 특별한 식별자를 키워드 라고 한다 . 간단히 말해, 키워드는 특별한 의미를 가진 식별자다 . 예를 들어, 일상생활에서 가게를 열려면 이름을 붙여야 한다. 이 “이름”을 식별자라고 한다. 하지만 “경찰서”라는 이름을 붙일 수는 없다. “경찰서”는 특별한 의미를 가지고 있고, “경찰서”는 일상생활에서 키워드이기 때문이다.
Java언어에서 키워드는 무엇이 있나요?
| type | keyword | ||||||
|---|---|---|---|---|---|---|---|
| 접근 제어 | private | protected | public | ||||
| 클래스, 메서드 및 변수 수정자 | abstract | class | extends | final | implements | interface | native |
| new | static | strictfp | synchronized | transient | volatile | enum | |
| 프로그램 제어 | break | continue | return | do | while | if | else |
| for | instanceof | switch | case | default | assert | ||
| 오류 처리 | try | catch | throw | throws | finally | ||
| 패키지 관련 | import | package | |||||
| 기본 유형 | boolean | byte | char | double | float | int | long |
| short | |||||||
| 변수 참조 | super | this | void | ||||
| 예약어 | goto | const |
팁: 모든 키워드는 소문자이며 IDE에서 특별한 색상으로 표시된다.
default키워드는 매우 특별하여 프로그램 제어, 클래스/메서드/변수 수식어, 접근 제어에 모두 속한다. 프로그램 제어에서switch문에 해당하는 조건이 없을 때default를 사용하여 기본 매칭 조건을 작성할 수 있다. 클래스, 메서드 및 변수 수식어에서는 JDK 8부터 도입된 기본 메서드(default method)를 정의할 때default키워드를 사용할 수 있다. 접근 제어에서 메서드 앞에 수식어가 전혀 없을 경우 기본적으로default수식어가 적용되지만, 이 수식어를 명시적으로 추가하면 오류가 발생한다.
⚠️ 참고: true, false, 는 null 키워드처럼 보이지만 실제로는 리터럴이며 식별자로 사용할 수 없다.
공식 문서 : https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html
증가 및 감소 연산자
코드를 작성하는 과정에서 흔히 발생하는 상황은 정수형 변수의 값을 1 증가시키거나 1 감소시켜야 하는 경우다. Java는 이러한 작업을 간소화하기 위해 자동 증가 연산자(++)와 자동 감소 연산자(--)를 제공한다.
++ 및 -- 연산자는 변수 앞에 놓을 수도 있고 변수 뒤에 놓을 수도 있다.
- 접두사 형태(예:
++a또는--a): 먼저 변수의 값을 증가/감소한 후 해당 변수를 사용한다. 예를 들어,b = ++a는 먼저a를 1 증가시킨 후 증가된 값을b에 할당한다. - 접미사 형태(예:
a++또는a--): 변수의 현재 값을 먼저 사용한 후 변수의 값을 증가/감소시킨다. 예를 들어,b = a++는 먼저a의 현재 값을b에 할당한 후a를 1 증가시킨다.
기억하기 편하도록 다음과 같은 암기법을 사용할 수 있다: 기호가 앞에 있으면 먼저 증가/감소시키고, 기호가 뒤에 있으면 나중에 증가/감소시킨다.
다음은 자동증감 연산자를 평가하는 빈도 높은 필기 시험 문제다: 아래 코드를 실행한 후 a, b, c, d, e의 값은 무엇인가?
1
2
3
4
5
int a = 9;
int b = a++;
int c = ++a;
int d = c--;
int e = --d;
답: a = 11, b = 9, c = 10, d = 10, e = 10.
시프트 연산자
시프트 연산자는 가장 기본적인 연산자 중 하나로, 거의 모든 프로그래밍 언어에 포함되어 있다. 이동 연산에서는 대상 데이터가 이진수로 간주되며, 이동은 이를 좌우로 특정 비트 수만큼 이동시키는 연산이다.
이동 연산자는 다양한 프레임워크와 JDK 자체 소스 코드에서 상당히 널리 사용된다. 예를 들어 JDK 1.8의 HashMap에서 hash 메서드 소스 코드에는 이동 연산자가 사용된다.
1
2
3
4
5
6
7
8
static final int hash(Object key) {
int h;
// key.hashCode():객체의 기본 정수형 해시 코드를 반환
// ^:비트별 XOR(배타적 논리합) 연산
// >>>:부호 없는 오른쪽 시프트 연산 (unsigned right shift).
// 비트를 오른쪽으로 16자리 이동시키고, 왼쪽 빈자리는 0으로 채웁니다.
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
이동 연산자를 사용하는 주요 이유
- 효율성 : 시프트 연산자는 프로세서의 시프트 명령어와 직접 대응한다. 현대 프로세서는 이러한 시프트 작업을 수행하기 위한 전용 하드웨어 명령어를 갖추고 있으며, 이 명령어들은 일반적으로 하나의 클록 사이클(컴퓨터가 명령어를 실행하는 기본적인 1회 동작 주기) 내에 완료된다. 반면, 곱셈이나 나눗셈과 같은 산술 연산은 하드웨어 수준에서 더 많은 클록 사이클이 필요하다.
- 메모리 절약 : 시프트 연산을 통해 하나의 정수(예:
int또는long)로 여러 부울 값이나 플래그 비트를 저장할 수 있어 메모리를 절약할 수 있다.
시프트 연산자는 2의 거듭제곱을 빠르게 곱하거나 나누는 데 가장 흔히 사용된다. 그 외에도 다음과 같은 중요한 역할을 한다.
- 비트 필드 관리 : ex) 여러
bool값을 저장하고 조작하는 경우가 있다. - 해시 알고리즘 및 암호화/복호화 : 시프트 연산과
AND,OR등의 연산을 통해 데이터를 난독화한다. - 데이터 압축 : ex) 호프만 부호화는 시프트 연산자를 통해 이진 데이터를 신속하게 처리 및 조작하여 간결한 압축 형식을 생성한다.
- 데이터 검증 : ex) CRC(순환 중복 검사)는 시프트와 다항식 나눗셈을 통해 데이터 무결성을 생성하고 검증한다.
- 메모리 정렬 : 시프트 연산을 통해 데이터의 정렬 주소를 쉽게 계산하고 조정할 수 있다. 가장 기본적인 시프트 연산자 지식을 숙지하는 것은 매우 중요하다. 이는 코드에서 활용할 수 있을 뿐만 아니라, 소스 코드 내 시프트 연산자가 포함된 부분을 이해하는 데도 도움이 된다.
Java에는 세 가지 시프트 연산자가 있다.
<<:좌측 이동 연산자, 왼쪽으로 n 비트 이동. 상위 비트 버리고 하위 비트 0으로 채움.x << n은 x를 2의 n제곱으로 곱한 것과 동일(오버플로우 발생하지 않는 경우).>>:부호 있는 우측 이동, 오른쪽으로 n 비트 이동. 상위 비트에 부호 비트 채우고 하위 비트 버림. 양수는 상위 비트에 0을, 음수는 상위 비트에 1을 보충한다.x >> n은 x를 2의 n제곱으로 나눈 것과 같다.>>>: 부호 없는 오른쪽 이동, 부호 비트를 무시하고 빈 비트는 모두 0으로 채운다.
비트 시프트 연산은 본질적으로 왼쪽 시프트와 오른쪽 시프트로 구분되지만, 실제 적용 시 오른쪽 시프트는 부호비트 처리를 고려해야 한다.
double과 float은 이진수 표현이 특수하므로 시프트 연산을 수행할 수 없다.
시프트 연산자가 실제로 지원하는 유형은 int와 long뿐 이며, 컴파일러는 short, byte, char 유형에 대해 시프트를 수행하기 전에 이를 int 유형으로 변환한 후 연산을 수행한다.
Q. 시프트하는 비트 수가 숫자가 차지하는 비트 수를 초과하면 어떻게 될까?
int 유형의 좌/우 시프트 비트 수가 32비트 연산 이상일 경우, 먼저 나머지 연산(%)을 수행한 후 좌/우 시프트를 진행한다. 즉, 32비트 좌/우 시프트 연산은 이동을 수행하지 않는 것과 동일하다(32%32=0). 42비트 좌/우 시프트 연산은 10비트 이동과 동일하다(42%32=10). long 타입의 좌/우 시프트 연산은 long의 이진 표현이 64비트이므로 나머지 연산은 64진법을 사용한다.
즉: x<<42는 x<<10과 동일하며, x>>42는 x>>10과 동일하고, ` x»> 42는 x»>10`과 동일하다.
좌측 시프트 이동 연산자 코드 예시 :
1
2
3
4
5
6
int i = -1;
System.out.println("초기 데이터:" + i);
System.out.println("초기 데이터에 대응하는 이진 문자열:" + Integer.toBinaryString(i));
i <<= 10;
System.out.println("10비트 왼쪽으로 이동한 후의 데이터 " + i);
System.out.println("10비트 왼쪽으로 이동한 데이터에 대응하는 이진 문자열 " + Integer.toBinaryString(i));
결과 :
1
2
3
4
초기 데이터: -1
초기 데이터에 대응하는 이진 문자열: 11111111111111111111111111111111
10비트 왼쪽으로 이동한 후의 데이터 -1024
10비트 왼쪽으로 이동한 후의 데이터에 해당하는 이진 문자열 11111111111111111111110000000000
좌측 이동 비트 수가 32비트 이상일 경우, 좌측 이동 연산에 앞서 나머지(%)를 계산하므로, 다음 코드는 42비트를 좌측으로 이동한다. 이는 10비트를 좌측으로 이동하는 것과 같다(42%32=10). 출력 결과는 이전 코드와 동일하다.
1
2
3
4
5
6
int i = -1;
System.out.println("초기 데이터:" + i);
System.out.println("초기 데이터에 대응하는 이진 문자열:" + Integer.toBinaryString(i));
i <<= 42;
System.out.println("10비트 왼쪽으로 이동한 후의 데이터 " + i);
System.out.println("10비트 왼쪽으로 이동한 데이터에 대응하는 이진 문자열 " + Integer.toBinaryString(i));
continue, break, return의 차이점은 무엇일까?
루프 구조에서 루프 조건이 충족되지 않거나 루프 횟수가 필요한 횟수에 도달하면 루프는 정상적으로 종료된다. 하지만 루프 실행 중 특정 조건이 발생하면 루프를 조기에 종료해야 할 수도 있다. 이를 위해서는 다음 키워드를 사용해야 한다.
continue: 현재 반복을 건너뛰고 다음 반복으로 진행한다.break: 전체 루프 본문을 건너뛰고 루프 하단의 문장을 계속 실행한다.
return : 현재 메서드를 건너뛰어 해당 메서드의 실행을 종료한다. return은 일반적으로 두 가지 용법이 있다:
return;: 반환 값이 없는 함수에서 return을 직접 사용 하여 메서드 실행을 종료한다.return value;: 반환 값이 있는 함수에서 특정 값을 반환한다. 다음 문장의 실행 결과는 무엇일까요?
예시 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public static void main(String[] args) {
boolean flag = false;
for (int i = 0; i <= 3; i++) {
if (i == 0) {
System.out.println("0");
} else if (i == 1) {
System.out.println("1");
continue;
} else if (i == 2) {
System.out.println("2");
flag = true;
} else if (i == 3) {
System.out.println("3");
break;
} else if (i == 4) {
System.out.println("4");
}
System.out.println("xixi");
}
if (flag) {
System.out.println("haha");
return;
}
System.out.println("heihei");
}
실행 결과:
1
2
3
4
5
6
7
0
xixi
1
2
xixi
3
haha
기본 데이터 유형
Java의 기본 데이터 유형
Java에는 8가지 기본 데이터 유형이 있다.
- 6가지 숫자 유형
- 4가지 정수형:
byte,short,int,long - 2가지 부동 소수점형:
float,double
- 4가지 정수형:
- 1가지 문자형:
char - 1가지 bool형:
boolean
이 8가지 기본 데이터 유형의 기본값과 차지하는 공간 크기는 다음과 같다.
| 기본유형 | 숫자의 개수 | 바이트 | 기본값 | 값 범위 |
|---|---|---|---|---|
| byte | 8 | 1 | 0 | -128 ~ 127 |
| short | 16 | 2 | 0 | -32768 (-2^15) ~ 32767 (2^15 - 1) |
| int | 32 | 4 | 0 | -2147483648 ~ 2147483647 |
| long | 64 | 8 | 0L | -9223372036854775808 (-2^63) ~ 9223372036854775807 (2^63 -1) |
| char | 16 | 2 | ‘u0000’ | 0 ~ 65535 (2^16 - 1) |
| float | 32 | 4 | 0의 | 1.4E-45 ~ 3.4028235E38 |
| double | 64 | 8 | 0일 | 4.9E-324 ~ 1.7976931348623157E308 |
| boolean | 1 | 거짓 | 참, 거짓 |
byte, short, int, long 이 표현할 수 있는 최대 양수는 모두 1이 줄어든 값다. 왜 그럴까?
이는 2의 보수 표현법에서 최상위 비트가 부호(0은 양수, 1은 음수)를 나타내고 나머지 비트가 수치 부분을 나타내기 때문이다. 따라서 최대 양수를 표현하려면 최상위 비트를 제외한 모든 비트를 1로 설정해야 한다. 만약 여기에 1을 더하면 오버플로우가 발생하여 음수가 된다.
boolean의 경우 공식 문서에 명확히 정의되어 있지 않으며, JVM 벤더의 구체적인 구현에 따라 다르다. 논리적으로는 1비트를 차지한다고 이해되지만, 실제 구현에서는 컴퓨터의 효율적인 저장 공간 활용을 고려한다.
또한 Java의 각 기본 데이터 유형이 차지하는 저장 공간 크기는 다른 대부분의 언어처럼 기계 하드웨어 아키텍처 변화에 따라 달라지지 않는다. 이러한 저장 공간 크기의 불변성은 Java 프로그램이 다른 대부분의 언어로 작성된 프로그램보다 더 높은 이식성을 가지는 이유 중 하나다.
주의:
- Java에서
long유형의 데이터를 사용할 때는 반드시 숫자 뒤에L을 붙여야 한다. 그렇지 않으면 정수형으로 해석된다. - Java에서
float형식의 데이터를 사용할 때는 반드시 숫자 뒤에f또는F를 붙여야 하며, 그렇지 않으면 컴파일을 통과할 수 없다. char a = ‘h’char : 작은따옴표,String a = “hello”: 큰따옴표
이 8 가지 기본 형식에는 각각 대응하는 래퍼 클래스가 있다: Byte, Short, Integer, Long, Float, Double, Character, Boolean.
기본 타입과 래퍼 타입의 차이점
- 용도 : 일부 상수나 지역 변수를 정의하는 경우를 제외하면, 메서드 매개변수나 객체 속성 등에서 기본 타입으로 변수를 정의하는 경우는 거의 없다. 또한 래퍼 타입은 제네릭에 사용할 수 있지만 기본 타입은 사용할 수 없다.
- 저장 방식 : 기본 데이터 유형의 지역 변수는 Java 가상 머신 스택의 지역 변수 테이블 에 저장되며, 기본 데이터 유형의 멤버 변수(
static으로 선언되지 않은) 는 Java 가상 머신의 힙에 저장 된다. 래퍼 유형은 객체 유형에 속하며, 거의 모든 객체 인스턴스는 힙에 존재하다. - 점유 공간 : 래퍼 유형(객체 유형)에 비해 기본 데이터 유형이 차지하는 공간은 일반적으로 매우 작다.
- 기본값 : 멤버 변수의 래퍼 타입은 값을 할당하지 않으면
null이 되지만, 기본 타입은null이 아닌 기본값을 가진다. - 비교 방식 : 기본 데이터 타입의 경우
==연산자는 값을 비교한다. 래퍼 데이터 타입의 경우==연산자는 객체의 메모리 주소를 비교한다. 모든 정수형 래퍼 객체 간의 값 비교는equals()메서드를 사용한다.
왜 거의 모든 객체 인스턴스가 힙에 존재한다고 할까?
이는 HotSpot 가상 머신이 JIT 최적화를 도입한 후 객체에 대해 이스케이프 분석을 수행하기 때문이다. 특정 객체가 메서드 외부로 이스케이프되지 않았다고 판단되면 스칼라 치환을 통해 스택 할당을 구현하여 힙 할당을 피할 수 있다.
기본 데이터 유형이 스택에 저장된다는 것은 흔한 오해다. 기본 데이터 유형의 저장 위치는 그들(기본 데이터 유형)의 범위와 선언 방식에 따라 결정된다. 만약 그들이 지역 변수라면 스택에 저장된다. 만약 그들이 멤버 변수라면 힙/메서드 영역/메타스페이스에 저장된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class Test {
// 멤버 변수, 힙에 저장됨
int a = 10;
// static으로 수식된 멤버 변수, JDK 1.7 이전에는 메서드 영역에 위치하며, 1.8 이후에는 메타스페이스에 저장됨. 둘 다 힙에 저장되지 않음.
// 변수는 객체가 아닌 클래스에 속한다.
static int b = 20;
public void method() {
// 스택에 저장되는 지역 변수
int c = 30;
static int d = 40; // 컴파일 오류: 메서드 내에서 로컬 변수에 static 수식어 사용 불가
}
}
래퍼 타입의 캐싱 메커니즘
대부분의 Java 기본 데이터 유형의 래퍼 유형은 성능을 향상시키기 위해 캐싱 메커니즘을 사용한다.
Byte, Short, Integer, Long 이 4가지 포장 클래스는 기본적으로 [-128, 127] 범위의 해당 유형 캐시 데이터를 생성하며, Character는 [0, 127] 범위의 캐시 데이터를 생성한다. Boolean은 TRUE 또는 FALSE를 직접 반환한다.
Integer의 경우 JVM 옵션 -XX:AutoBoxCacheMax=<size>로 캐시 상한을 수정할 수 있지만, 하한 -128은 변경할 수 없다. 실제 사용 시에는 메모리 낭비나 OOM(OutOfMemoryError)을 방지하기 위해 지나치게 큰 값을 설정하지 않는 것이 좋다.
Byte, Short, Long, Character의 경우 -XX:AutoBoxCacheMax와 유사한 매개변수로 수정할 수 없으므로 캐시 범위는 고정되어 있으며 JVM 매개변수로 조정할 수 없다. Boolean은 미리 정의된 TRUE 및 FALSE 인스턴스를 직접 반환하므로 캐시 범위 개념이 없다.
Integer캐시:
1
2
3
4
5
6
7
8
9
10
11
12
13
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static {
// high value may be configured by property
int h = 127;
}
}
Character캐시:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
cache[i] = new Character((char)i);
}
}
Boolean캐시:
1
2
3
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
해당 범위를 초과하더라도 여전히 새 객체를 생성하며, 캐시의 범위 구간 크기는 성능과 자원 사이의 절충점일 뿐이다.
두 부동 소수점 유형의 래퍼 클래스인 Float과 Double은 캐싱 메커니즘을 구현하지 않았다.
1
2
3
4
5
6
7
8
9
10
11
Integer i1 = 33;
Integer i2 = 33;
System.out.println(i1 == i2);// true 출력
Float i11 = 333f;
Float i22 = 333f;
System.out.println(i11 == i22);// false 출력
Double i3 = 1.2;
Double i4 = 1.2;
System.out.println(i3 == i4);// false 출력
아래 코드 출력은 무엇일까?
1
2
3
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);
Integer i1=40 이 코드 줄은 박싱이 발생한다. 즉, 이 코드는 Integer i1=Integer.valueOf(40) 과 동일하다. 따라서 i1은 캐시된 객체를 직접 사용한다. 반면 Integer i2 = new Integer(40) 은 새로운 객체를 직접 생성한다.
따라서 정답은 false 다.
모든 정수형 래퍼 객체 간의 값 비교는 모두 equals 메서드를 사용해 비교한다.
오토 박싱과 언박싱
오토 박싱이란 무엇일까?
- 박싱 : 기본 타입을 해당 참조 유형으로 래핑하는 것
- 언박싱 : 래퍼 타입을 기본 데이터 유형으로 변환하는 것
ex)
1
2
Integer i = 10; //박싱
int n = i; //언박싱
위 두 줄의 코드에 해당하는 바이트 코드는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
L1
LINENUMBER 8 L1
ALOAD 0
BIPUSH 10
INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer;
PUTFIELD AutoBoxTest.i : Ljava/lang/Integer;
L2
LINENUMBER 9 L2
ALOAD 0
ALOAD 0
GETFIELD AutoBoxTest.i : Ljava/lang/Integer;
INVOKEVIRTUAL java/lang/Integer.intValue ()I
PUTFIELD AutoBoxTest.n : I
RETURN
바이트코드에서 우리는 박싱이 실제로 래퍼 클래스의 valueOf() 메서드를 호출하는 것이고, 언박싱이 실제로 xxxValue() 메서드를 호출하는 것임을 발견했다.
따라서,
Integer i = 10은Integer i = Integer.valueOf(10)과 동일하며,int n = i는int n = i.intValue()와 동일하다.
참고: 빈번한 박싱/언박싱은 시스템 성능에 심각한 영향을 미칠 수 있다. 불필요한 박싱/언박싱 작업은 최대한 피해야 한다.
1
2
3
4
5
6
7
private static long sum() {
// Long 대신 long을 사용해야 함
Long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++)
sum += i;
return sum;
}
부동 소수점 연산을 할 때 정밀도가 떨어질 위험이 있는 이유는?
부동 소수점 연산 정밀도 손실 예시 코드
1
2
3
4
5
float a = 2.0f - 1.9f;
float b = 1.8f - 1.7f;
System.out.printf("%.9f",a);// 0.100000024
System.out.println(b);// 0.099999905
System.out.println(a == b);// false
왜 이런 문제가 발생할까?
이는 컴퓨터가 부동 소수점을 저장하는 방식과 밀접한 관련이 있다. 컴퓨터는 이진수를 사용하며, 숫자를 표현할 때 비트 폭이 제한적이다. 무한히 반복되는 소수는 컴퓨터에 저장될 때 반드시 잘려 소수점 정밀독 떨어진다. 이것이 부동 소수점 숫자를 이진수로 정확하게 표현할 수 없는 이유다.
ex) 십진수 0.2는 이진수 십진수로 정확하게 변환할 수 없다.
1
2
3
4
5
6
7
8
// 0.2를 이진수로 변환하는 과정은 소수 부분이 없어질 때까지 계속해서 2를 곱하는 것이다.
// 이 계산 과정에서 얻어진 정수 부분을 위에서 아래로 나열하면 이진수 결과가 된다.
0.2 * 2 = 0.4 -> 0
0.4 * 2 = 0.8 -> 0
0.8 * 2 = 1.6 -> 1
0.6 * 2 = 1.2 -> 1
0.2 * 2 = 0.4 -> 0 (순환 발생)
...
부동 소수점 숫자에 대한 자세한 내용을 알아보려면 컴퓨터 시스템 기초(IV) 부동 소수점 숫자 문서를 읽어보자.
부동 소수점 연산에서 정밀도 손실 문제를 어떻게 해결할까?
BigDecimal 은 부동 소수점 연산을 구현할 수 있으며, 정밀도 손실을 일으키지 않는다. 일반적으로 부동 소수점의 정확한 연산 결과가 필요한 대부분의 비즈니스 시나리오(예: 금전 관련 시나리오)는 BigDecimal을 통해 처리된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
BigDecimal a = new BigDecimal(“1.0”);
BigDecimal b = new BigDecimal(“1.00”);
BigDecimal c = new BigDecimal(“0.8”);
BigDecimal x = a.subtract(c);
BigDecimal y = b.subtract(c);
System.out.println(x); /* 0.2 */
System.out.println(y); /* 0.20 */
// 비교 내용, 값 비교 아님
System.out.println(Objects.equals(x, y)); /* false */
// 값 비교는 compareTo 사용, 동일 시 0 반환
System.out.println(0 == x.compareTo(y)); /* true */
긴 정수형을 초과하는 데이터는 어떻게 표현할까?
기본 숫자형에는 표현 범위가 있다. 범위를 초과하면 숫자 오버플로가 발생할 위험이 있다.
Java에서는 64비트 정수가 가장 큰 정수 유형이다.
1
2
3
long l = Long.MAX_VALUE;
System.out.println(l + 1); // -9223372036854775808
System.out.println(l + 1 == Long.MIN_VALUE); // true
BigInteger는 내부적으로 int[] 배열을 사용하여 임의 크기의 정수 데이터를 저장한다.
일반 정수 유형의 연산에 비해 BigInteger 연산의 효율성은 상대적으로 낮다.
변수
멤버 변수와 지역 변수의 차이점은?
- 문법 형태 : 문법 형태로 보면 멤버 변수는 클래스에 속하고, 지역 변수는 코드 블럭이나 메서드에 정의된 변수이거나 메서드의 매개변수 다. 멤버 변수는
public,private,static등의 수식어로 수식될 수 있지만, 로컬 변수는 접근 제어 수식어나static으로 수식될 수 없다. 그러나 멤버 변수와 로컬 변수 모두final로 수식될 수 있다. - 저장 방식 : 변수가 메모리에 저장되는 방식을 보면, 멤버 변수가
static으로 수식된 경우 해당 멤버 변수는 클래스에 속하며,static수식자가 없는 경우 해당 멤버 변수는 인스턴스에 속한다. 객체는 힙 메모리에 존재하는 반면, 지역 변수는 스택 메모리에 존재한다. - 생존 시간 : 변수의 메모리 내 생존 기간을 보면, 멤버 변수는 객체의 일부로 객체 생성 시 함께 존재한다. 반면 지역 변수는 메서드 호출 시 자동 생성되며, 메서드 호출 종료와 함께 소멸된다.
- 기본값 : 변수에 기본값이 있는지 여부를 보면, 멤버 변수는 초기값이 할당되지 않으면 자동으로 해당 유형의 기본값으로 할당된다 (한 가지 예외:
final로 수식된 멤버 변수는 반드시 명시적으로 할당해야 함). 반면 지역 변수는 자동으로 할당되지 않는다.
Q. 왜 멤버 변수에는 기본값이 있을까?
- 변수 유형을 고려하지 않고, 기본값이 없다면 어떻게 될까? 변수는 메모리 주소에 대응하는 임의의 값을 저장하게 되며, 프로그램이 이 값을 읽어서 실행하면 예기치 못한 결과가 발생한다.
- 기본값 설정 방식은 수동과 자동 두 가지가 있다. 첫 번째 사항에 따르면, 수동으로 값을 할당하지 않으면 반드시 자동으로 할당되어야 한다. 멤버 변수는 런타임에 리플렉션 등의 방법을 통해 수동으로 값을 할당할 수 있지만, 로컬 변수는 그렇지 않다.
- 컴파일러(javac) 입장에서는 로컬 변수가 값을 할당받지 않은 경우 쉽게 판단할 수 있어 직접 오류를 발생시킬 수 있다. 반면 멤버 변수는 실행 시 할당될 수 있어 판단이 불가능하며, “기본값 없음” 오류를 잘못 발생시키면 사용자 경험에 영향을 미치므로 자동 기본값 할당 방식을 채택한다.
멤버 변수와 지역 변수 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class VariableExample {
// 멤버 변수
private String name;
private int age;
// 메서드 내의 지역 변수
public void method() {
int num1 = 10; // 스택에 할당된 지역 변수
String str = “Hello, world!”; // 스택에 할당된 지역 변수
System.out.println(num1);
System.out.println(str);
}
// 매개변수를 가진 메서드 내의 지역 변수
public void method2(int num2) {
int sum = num2 + 10; // 스택에 할당된 지역 변수
System.out.println(sum);
}
// 생성자 내의 지역 변수
public VariableExample(String name, int age) {
this.name = name; // 멤버 변수에 할당
this.age = age; // 멤버 변수에 할당
int num3 = 20; // 스택에 할당된 지역 변수
String str2 = “Hello, ” + this.name + “!”; // 스택에 할당된 지역 변수
System.out.println(num3);
System.out.println(str2);
}
}
정적 변수의 기능은 무엇인가?
정적 변수는 static 키워드로 선언된 변수를 말한다. 이는 클래스의 모든 인스턴스가 공유할 수 있으며, 클래스가 생성한 객체의 수와 관계없이 동일한 정적 변수를 공유한다. 즉, 정적 변수는 메모리가 한 번만 할당되며, 여러 객체를 생성하더라도 메모리를 절약할 수 있다.
정적 변수는 클래스명을 통해 접근한다. ex) StaticVariableExample.staticVar (private 키워드로 선언된 경우는 이런 식으로 접근할 수 없다)
1
2
3
4
public class StaticVariableExample {
// 정적 변수
public static int staticVar = 0;
}
일반적으로 정적 변수는 final 키워드로 수식되어 상수가 된다.
1
2
3
4
public class ConstantVariableExample {
// 상수
public static final int constantVar = 0;
}
문자 상수와 문자열 상수의 차이점
-
형식 : 문자 상수는 작은따옴표로 시작하는 단일 문자이고, 문자열 상수는 큰따옴표로 시작하는 0개 이상의 문자다.
-
의미 : 문자 상수는 정수 값 (ASCII 값)과 동일하며, 표현식 연산에 참여할 수 있다. 문자열 상수는 주소값(해당 문자열이 메모리에 저장된 위치)을 나타낸다.
-
메모리 크기 : 문자 상수는 2바이트만 차지하지만, 문자열 상수는 여러 바이트를 차지한다.
⚠️ 참고: Java에서 char 은 2바이트를 차지한다.
문자 상수와 문자열 상수 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class StringExample {
// 문자형 상수
public static final char LETTER_A = ‘A’;
// 문자열 상수
public static final String GREETING_MESSAGE = “Hello, world!”;
public static void main(String[] args) {
System.out.println(“문자 상수가 차지하는 바이트 수는:” + Character.BYTES);
System.out.println(“문자열 상수가 차지하는 바이트 수는:” + GREETING_MESSAGE.getBytes().length);
}
}
//결과
//문자형 상수가 차지하는 바이트 수는:2
//문자열 상수가 차지하는 바이트 수는:13
메서드
메서드의 반환값이란? 메서드에는 어떤 유형이 있는가?
메서드의 반환 값 은 특정 메서드 본문의 코드 실행 후 생성된 결과를 의미한다. (해당 메서드가 결과를 생성할 수 있다는 전제 하에). 반환값의 역할은 결과를 받아 다른 작업에 활용할 수 있도록 하는 것이다.
메서드의 반환값과 매개변수 유형에 따라 메서드를 다음과 같이 분류할 수 있다.
- 매개변수와 반환 값이 없는 메서드
1 2 3 4 5 6 7 8 9 10 11
public void f1() { //...... } // 아래 메서드도 반환값이 없으며, return을 사용했음에도 불구하고 public void f(int a) { if (...) { // 메서드 실행 종료 표시, 아래 출력 문장은 실행되지 않음 return; } System.out.println(a); }
- 매개변수는 있지만 반환 값이 없는 메서드
1 2 3
public void f2(Parameter 1, ..., Parameter n) { //...... }
- 반환 값은 있으나 매개변수가 없는 메서드
1 2 3 4
public int f3() { //...... return x; }
- 반환 값과 매개변수가 있는 메서드
1 2 3
public int f4(int a, int b) { return a * b; }
정적 메서드는 왜 비정적 멤버를 호출할 수 없을까?
이를 이해하기 위해서는 JVM 관련 지식이 필요하다. 주요 원인은 다음과 같다.
- 정적 메서드는 클래스에 속하며, 클래스 로딩 시 메모리가 할당되어 클래스명으로는 직접 접근할 수 있다. 반면 비정적 멤버는 인스턴스 객체에 속하며, 객체가 인스턴스화 된 후에만 존재하므로 클래스의 인스턴스 객체를 통해 접근해야 한다.
- 클래스의 비정적 멤버가 존재하지 않을 때 정적 메서드는 이미 존재한다. 이때 메모리에 아직 존재하지 않는 비정적 멤버를 호출하는 것은 불법적인 작업에 해당한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class Example {
// 문자 상수 정의
public static final char LETTER_A = ‘A’;
// 문자열 상수 정의
public static final String GREETING_MESSAGE = “Hello, world!”;
public static void main(String[] args) {
// 문자 상수의 값 출력
System.out.println(“문자 상수의 값은 : ” + LETTER_A);
// 문자열 상수의 값 출력
System.out.println(“문자열 상수의 값은 : ” + GREETING_MESSAGE);
}
}
정적 메서드와 인스턴스 메서드의 차이점
- 호출 방식
외부에서 정적 메서드를 호출할 때는 클래스명.메서드명 또는 객체.메서드명 방식을 사용할 수 있지만, 인스턴스 메서드는 후자의 방식만 가능하다. 즉, 정적 메서드를 호출할 때 객체를 생성할 필요가 없다.
하지만 일반적으로 객체.메서드명 방식으로 정적 메서드를 호출하는 것은 권장되지 않는다. 이 방식은 혼동을 초래하기 쉬우며, 정적 메서드는 특정 객체가 아닌 해당 클래스 자체에 속한다.
따라서 일반적으로 정적 메서드 호출에는 클래스명.메서드명 방식을 사용하는 것이 권장된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class Person {
public void method() {
//......
}
public static void staicMethod(){
//......
}
public static void main(String[] args) {
Person person = new Person();
// 인스턴스 메서드 호출
person.method();
// 정적 메서드 호출
Person.staicMethod()
}
}
- 클래스 멤버 접근 제한 여부
정적 메서드는 본 클래스의 멤버를 접근할 때 정적 멤버(즉 정적 멤버 변수와 정적 메서드)에만 접근할 수 있으며, 인스턴스 멤버(인스턴스 멤버 변수와 인스턴스 메서드)에는 접근할 수 없다. 인스턴스 메서드에는 이러한 제한이 없다.
오버로딩과 오버로딩의 차이점
오버로드는 동일한 메서드가 다른 입력 데이터에 따라 다른 처리를 할 수 있는 것이다. 오버라이드는 하위 클래스가 상위 클래스의 동일한 메서드를 상속할 때, 입력 데이터는 같지만 상위 클래스와 다른 응답을 해야할 때 상위 클래스 메서드를 덮어쓰는 것이다.
오버로딩
동일한 클래스 내에서 (또는 상위 클래스와 하위 클래스 간에) 발생하며, 메서드 이름은 동일해야 하지만 매개변수 유형, 개수, 순서가 다를 수 있다. 메서드 반환 값과 접근 수정자는 다를 수 있다.
“Java Core Technology”라는 책에서는 오버로딩을 다음과 같이 소개한다.
여러 메서드(예:
StringBuilder의 생성자)가 동일한 이름을 가지면서 매개변수가 다를 경우 중복 정의가 발생한다.
컴파일러는 구체적으로 어떤 메서드를 실행할 지 선택해야하며, 각 메서드가 제공하는 매개변수 유형과 특정 메서드 호출에 사용된 값 유형을 매칭하여 해당 메서드를 선택한다. 컴파일러가 매칭되는 매개변수를 찾지 못하면 컴파일 시 오류를 발생한다. 매칭 자체가 존재하지 않거나, 다른 것보다 더 나은 매칭이 없기 때문이다. (이 과정을 Overloading resolution이라고 한다). Java는 생성자 메서드뿐만 아니라 모든 메서드의 오버로딩을 허용한다.
요약하먄 오버로딩은 동일한 클래스 내 여러 개의 동일 이름 메서드가 서로 다른 매개변수를 기반으로 서로 다른 논리 처리를 수행하는 것 이다.
오버라이딩
재정의는 런타임에 발생 하며, 하위 클래스가 상위 클래스의 접근이 허용된 메서드 구현 과정을 다시 작성하는 것이다.
- 메서드명과 매개변수 목록은 동일해야 하며, 하위 클래스 메서드의 반환 값 유형은 상위 클래스 메서드보다 작거나 같아야 한다. 발생 가능한 예외 범위는 상위 클래스보다 작거나 같아야 하며, 접근 제한자 범위는 상위 클래스보다 크거나 같아야 한다.
- 상위 클래스 메서드의 접근 수정자가
private/final/static인 경우 하위 클래스에서 해당 메서드를 재정의할 수 없다. 단,static으로 수식된 메서드는 재선언이 가능하다. - 생성자는 재정의할 수 없다.
정리
오버라이딩은 하위 클래스가 부모 클래스의 메서드를 변형하는 것 이다. 외부적인 모습은 변경할 수 없지만, 내부 로직은 변경할 수 있다.
| 구분점 | 중복 정의 (Overloading) | 재정의 (Overriding) |
|---|---|---|
| 발생 범위 | 동일한 클래스 내 | 부모 클래스와 자식 클래스 사이 (상속 관계 존재) |
| 메서드 시그니처 | 메서드명은 동일해야 하지만, 매개변수 목록은 달라야 함 (매개변수의 유형, 개수 또는 순서 중 적어도 하나가 다름) | 메서드명과 매개변수 목록이 완전히 동일해야 함 |
| 반환 유형 | 반환 값 유형과 무관하며 임의로 수정 가능 | 자식 클래스 메서드의 반환 유형은 부모 클래스 메서드의 반환 유형과 동일하거나 그 하위 유형이어야 함 |
| 접근 수정자 | 접근 수정자와 무관하며 임의로 수정 가능 | 자식 클래스 메서드의 접근 권한은 부모 클래스 메서드의 접근 권한보다 낮아서는 안 됨. (public > protected > default > private) |
| 바인딩 시기 | 컴파일 시 바인딩 또는 정적 바인딩 | 런타임 바인딩(Run-time Binding) 또는 동적 바인딩 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class Hero {
public String name() {
return “히어로”;
}
}
public class SuperMan extends Hero{
@Override
public String name() {
return “슈퍼히어로”;
}
public Hero hero() {
return new Hero();
}
}
public class SuperSuperMan extends SuperMan {
@Override
public String name() {
return “슈퍼슈퍼히어로”;
}
@Override
public SuperMan hero() {
return new SuperMan();
}
}
가변길이 매개변수란?
Java 5부터 Java는 가변 길이 매개변수 정의를 지원한다. 가변 길이 매개변수란 메서드 호출 시 불확정 길이의 매개변수를 전달할 수 있도록 허용하는 것을 말한다. 예를 들어 아래 메서드는 0개 이상의 매개변수를 받을 수 있다.
1
2
3
public static void method1(String... args) {
//......
}
또한 가변 매개변수는 함수의 마지막 매개변수로만 사용될 수 있으며, 그 앞에는 다른 매개변수가 있을 수도 있고 없을 수도 있다.
1
2
3
public static void method2(String arg1, String... args) {
//......
}
메서드 오버로드 상황이 발생하면 어떻게 처리할까? 고정 매개변수 메서드와 가변 매개변수 메서드 중 어느 쪽이 우선적으로 매칭될까?
정답은 고정 매개변수 메서드가 우선적으로 매칭된다. 고정 매개변수 메서드가 매칭도가 더 높기 때문이다.
아래 예시를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class VariableLengthArgument {
public static void printVariable(String... args) {
for (String s : args) {
System.out.println(s);
}
}
public static void printVariable(String arg1, String arg2) {
System.out.println(arg1 + arg2);
}
public static void main(String[] args) {
printVariable(“a”, “b”);
printVariable(“a”, “b”, ‘c’, “d”);
}
}
// 결과
ab
a
b
c
d
또한, Java의 가변 매개변수는 컴파일 후 실제로 배열로 변환된다. 컴파일 후 생성된 클래스 파일을 보면 이를 확인할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class VariableLengthArgument {
public static void printVariable(String... args) {
String[] var1 = args;
int var2 = args.length;
for(int var3 = 0; var3 < var2; ++var3) {
String s = var1[var3];
System.out.println(s);
}
}
// ......
}