MySQL 옵티마이저 에러
옵티마이저 에러 & 힌트
옵티마이저는 제한된 정보를 이용해서 최적의 실행계획을 최대한 짧은 시간안에 수립해야한다. 따라서 빠르고 정확하게 실행되어야한다.
실제 실무에서 RDBMS사용할 때 옵티마이저 관련 오류가 많이 발생하고 이런 문제를 최대한 회피하고자 옵티마이저 힌트를 사용하고, 많은 힌트 기능들이 제공된다.
SQL문장에서 옵티마이저 힌트를 사용하면 RDBMS는 그 힌트를 매우 신뢰한다. 그래서 더 나은 실행계획이 있어도 여전히 SQL에 주어진 힌트를 사용하는 경향이 있다.
시간이 지나면서 데이터가 바뀌고 예전 실행계획이 최적이 아니게 될 수 있기 때문에 옵티마이저 힌트를 사용하지 않는것을 추천한다.
이 글에서 치명적인 옵티마이저 오류 케이스를 보고 왜 옵티마이저가 그런 잘못된 선택을 했는지 분석해보고자 한다.
실행 계획 오류 (ref vs range) 케이스
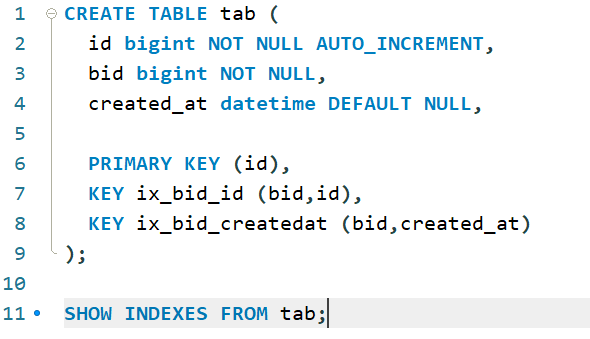
대상 테이블의 구조와 테이블 정보
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
CREATE TABLE tab (
id bigint NOT NULL AUTO_INCREMENT,
bid bigint NOT NULL,
created_at datetime DEFAULT NULL,
...
PRIMARY KEY (id),
KEY ix_bid_id (bid,id),
KEY ix_bid_createdat (bid,created_at)
);
mysql> SHOW INDEXES FROM tab;
+-------+------------+------------------+--------------+-------------+-------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Cardinality |
+-------+------------+------------------+--------------+-------------+-------------+
| tab | 0 | PRIMARY | 1 | id | 11797584 |
| tab | 1 | ix_bid_id | 1 | bid | 581387 |
| tab | 1 | ix_bid_id | 2 | id | 11797584 |
| tab | 1 | ix_bid_createdat | 1 | bid | 561151 |
| tab | 1 | ix_bid_createdat | 2 | created_at | 11702179 |
+-------+------------+------------------+--------------+-------------+-------------+
이제 ix_bid_createdat(bid, created_at) 인덱스와 ix_bid_id(bid, id) 인덱스를 사용할 것으로 예상되는 2개 쿼리의 실행 계획을 확인해보자.
실행계획 결과
1
2
3
4
5
6
7
8
9
10
11
12
13
14
mysql> EXPLAIN SELECT COUNT(*) FROM tab WHERE bid=1198442 AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
+------+-----------+---------+-------+---------+----------+-------------+
| type | key | key_len | ref | rows | filtered | Extra |
+------+-----------+---------+-------+---------+----------+-------------+
| ref | ix_bid_id | 8 | const | 1632722 | 33.33 | Using where |
+------+-----------+---------+-------+---------+----------+-------------+
mysql> EXPLAIN SELECT COUNT(*) FROM tab WHERE bid=1198442 AND id<14025956;
+------+------------------+---------+-------+---------+----------+--------------------------+
| type | key | key_len | ref | rows | filtered | Extra |
+------+------------------+---------+-------+---------+----------+--------------------------+
| ref | ix_bid_createdat | 8 | const | 1426712 | 50.00 | Using where; Using index |
+------+------------------+---------+-------+---------+----------+--------------------------+
MySQL 옵티마이저가 뭔가 잘못된 인덱스를 선택한 것이 보인다.
- 첫번째 쿼리는
ix_bid_createdat(bid, created_at)인덱스를 사용하면 커버링 인덱스로 매우 빠르게 처리될 수 있다. - 두번째 쿼리는
ix_bid_id(bid, id)인덱스를 사용하면 똑같이 커버링 인덱스로 빠르게 처리될 쿼리라는 것을 알수 있다.
하지만 MySQL 옵티마이저는 2개 쿼리에 대해서 거꾸로 인덱스를 선택한 상황이다.
간단한 해결 방법
옵티마이저 힌트 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- 첫 번째 쿼리: 올바른 인덱스 강제 사용
SELECT /*+ INDEX(tab ix_bid_createdat) */ COUNT(*)
FROM tab
WHERE bid=1198442
AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
-- 두 번째 쿼리: 올바른 인덱스 강제 사용
SELECT /*+ INDEX(tab ix_bid_id) */ COUNT(*)
FROM tab
WHERE bid=1198442
AND id<14025956;
힌트를 사용한 쿼리의 실행 계획
1
2
3
4
5
6
7
8
9
SELECT /*+ INDEX(tab ix_bid_createdat) */ COUNT(*)
FROM tab
WHERE bid=1198442
AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
+-------+------------------+---------+------+---------+----------+--------------------------+
| type | key | key_len | ref | rows | filtered | Extra |
+-------+------------------+---------+------+---------+----------+--------------------------+
| range | ix_bid_createdat | 14 | NULL | 1490996 | 100.00 | Using where; Using index |
+-------+------------------+---------+------+---------+----------+--------------------------+
Q) 왜 옵티마이저가 이런 판단을 했을까? 옵티마이저 힌트 없이 최적화 오류를 회피할 수 있는 방법은 없을까?
여기서 주의깊게 봐야 할 부분은 성능이 느린 실행 계획에서는 type 필드의 값이 ref 였었는데, 옵티마이저 힌트를 사용해서 성능이 개선된 쿼리의 실행 계획에서는 range로 바뀌었다는 것이다.
실제 이 쿼리의 최적화 오류는 ref 접근 방법의 비용 계산이 너무 낮게 계산되면서 발생한 문제인데, ref 접근 방법의 비용이 이렇게 낮게 계산된 이유를 살펴보자.
쿼리 비용 계산
우선 MySQL 서버의 쿼리 비용 계산 과정을 살펴보기 전에, MySQL 서버에서 사용하는 2가지 단위 작업에 대한 비용 상수( Cost Model )에 대해서 이해를 해야 하는데, MySQL 서버에서 단위 작업에 대한 비용 상수는 다음과 같다. (이 비용 상수에 대한 자세한 설명은 Real MySQL 1권 p.409 에 나와있다.) 우선 지금은 비용 상수는 변경없이 MySQL 서버의 기본 값을 그대로 사용중이라는 것을 기억하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
mysql> SELECT * FROM mysql.server_cost;
+------------------------------+------------+---------------+
| cost_name | cost_value | default_value |
+------------------------------+------------+---------------+
| disk_temptable_create_cost | NULL | 20 |
| disk_temptable_row_cost | NULL | 0.5 |
| key_compare_cost | NULL | 0.05 |
| memory_temptable_create_cost | NULL | 1 |
| memory_temptable_row_cost | NULL | 0.1 |
| row_evaluate_cost | NULL | 0.1 |
+------------------------------+------------+---------------+
mysql> SELECT * FROM mysql.engine_cost;
+------------------------+------------+---------------+
| cost_name | cost_value | default_value |
+------------------------+------------+---------------+
| io_block_read_cost | NULL | 1 |
| memory_block_read_cost | NULL | 0.25 |
+------------------------+------------+---------------+
이제 MySQL 서버에서 다음 쿼리가 ix_bid_id(bid, id)인덱스와 ix_bid_createdat(bid, created_at)인덱스를 사용할 때, 각각 쿼리 처리에 필요한 비용이 얼마일지 예측한 값을 비교.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
mysql> EXPLAIN FORMAT=JSON
SELECT /*+ INDEX(tab ix_bid_id) */ COUNT(*)
FROM tab
WHERE bid=1198442 AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "236946.95"
},
"table": {
"table_name": "tab",
"access_type": "ref",
"key": "ix_bid_id",
"used_key_parts": [
"bid"
],
"key_length": "8",
"rows_examined_per_scan": 1632722,
"rows_produced_per_join": 544186,
"filtered": "33.33",
"cost_info": {
"read_cost": "73674.75",
"eval_cost": "54418.62",
"prefix_cost": "236946.95",
"data_read_per_join": "24M"
},
...
}
}
}
mysql> EXPLAIN FORMAT=JSON
SELECT /*+ INDEX(tab ix_bid_createdat) */ COUNT(*)
FROM tab
WHERE bid=1198442 AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "302192.75"
},
"table": {
"table_name": "tab",
"access_type": "range",
"key": "ix_bid_createdat",
"used_key_parts": [
"bid",
"created_at"
],
"key_length": "14",
"rows_examined_per_scan": 1490996,
"rows_produced_per_join": 1490996,
"filtered": "100.00",
"using_index": true,
"cost_info": {
"read_cost": "153093.15",
"eval_cost": "149099.60",
"prefix_cost": "302192.75",
"data_read_per_join": "68M"
},
...
}
}
}
ix_bid_id(bid, id) 인덱스를 사용한 경우 전체 쿼리 비용은 234128.51(query_cost)이며,
ix_bid_createdat(bid, created_at) 인덱스를 사용한 경우 쿼리 비용은 302192.75(query_cost) 라는 것을 확인할 수 있다.
이 결과만 보면, 옵티마이저는 ix_bid_id 인덱스를 사용하는 실행 계획이 더 빠를 것이라고 예측했다는 것을 알 수 있다. 하지만 실제 쿼리 실행 결과는 10배나 더 걸렸다.
MySQL 의 쿼리 비용은 참조해야 하는 모든 테이블의(read_cost + eval_cost)의 합이다
read_cost는 CPU 기반 처리 작업의 비용eval_cost는 디스크 또는 메모리에서 데이터 페이지 읽기 작업의 비용
이 예제는 조인이 없기 때문에 단순히 read_cost와 eval_cost의 합이 전체 쿼리 비용(query_cost)이 된다.
그런데 ix_bid_createdat 인덱스의 경우 query_cost=(read_cost + eval_cost) 수식이 성립되지만,
ix_bid_id 인덱스의 경우 query_cost는 (read_cost + eval_cost)와 일치하지 않는다.
이는 ref 접근 방법의 비용 표현에서 일부가 누락되었기 때문이다.
또한 MySQL 8.0 버전부터는 테이블의 데이터 페이지가 메모리(InnoDB Buffer Pool)에 얼마나 적재되어 있는지 비율도 같이 계산되도록 개선되었는데, 이 비율은 다음과 같이 확인할 수 있다고 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
SELECT tables.NAME as table_name,
indexes.NAME as index_name,
stats.stat_value as n_total_pages,
cached.N_CACHED_PAGES as n_cached_pages,
(stats.stat_value - cached.N_CACHED_PAGES) as n_not_cached_pages,
(100.0*cached.N_CACHED_PAGES/stats.stat_value) as cached_ratio,
(100-(100.0*cached.N_CACHED_PAGES/stats.stat_value)) as not_cached_ratio
FROM information_schema.INNODB_TABLES AS tables
INNER JOIN information_schema.INNODB_INDEXES indexes ON indexes.TABLE_ID = tables.TABLE_ID
INNER JOIN information_schema.INNODB_CACHED_INDEXES cached ON cached.INDEX_ID = indexes.INDEX_ID
INNER JOIN mysql.innodb_index_stats stats ON stats.database_name=substring_index(tables.NAME,'/',1) AND stats.table_name=substring_index(tables.NAME,'/',-1) AND stats.index_name=indexes.NAME AND stats.stat_name='size'
WHERE tables.NAME='test/tab';
+------------+------------------+---------------+----------------+--------------------+--------------+------------------+
| table_name | index_name | n_total_pages | n_cached_pages | n_not_cached_pages | cached_ratio | not_cached_ratio |
+------------+------------------+---------------+----------------+--------------------+--------------+------------------+
| test/tab | PRIMARY | 47680 | 30829 | 16851 | 64.65814 | 35.34186 |
| test/tab | ix_bid_id | 28672 | 11 | 28661 | 0.03836 | 99.96164 |
| test/tab | ix_bid_createdat | 36608 | 11 | 36597 | 0.03005 | 99.96995 |
+------------+------------------+---------------+----------------+--------------------+--------------+------------------+
이제 각 인덱스를 사용하는 실행 계획의 비용 계산 과정을 살펴보자.
MySQL 서버 내부 코드 로직은 접근 방법에 따라서 매우 다양한 형태의 계산식을 활용한다.
아래의 계산식이 모든 쿼리의 비용 계산에 사용될 수 있는 공식은 아니고, 이 쿼리에만 적용된다는 것을 주의. 하지만 이 계산식을 통해서 MySQL 옵티마이저가 어떻게 쿼리의 비용을 예측하는지 대략적으로 살펴볼 수 있다.
MySQL에서 ref와 range는 모두 인덱스를 효율적으로 사용하는 실행 계획이긴 하지만, 두 접근 방법의 비용 계산 방식은 매우 다르게 구현되어 있다.
ix_bid_id 인덱스 활용 실행 계획
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
total_pages_of_table = 47680
estimated_rows = 1632722
pct_cached_pages(Primary) = 64.65814 %
pct_not_cached_pages(Primary) = (100 - 64.65814) %
row_evaluate_cost = 0.10
memory_block_read_cost = 0.25
disk_block_read_cost = 1.00
-- 1️⃣ worst_seek_cost (최악의 랜덤 액세스 비용)
worst_seek_cost(84095.62) = (estimated_rows/10 * pct_cached_pages * 0.25) + (estimated_rows/10 * pct_not_cached_pages * 1)
-- 2️⃣ total_scan_cost (전체 스캔 비용)
total_scan_cost(24558.25) = (total_pages_of_table * pct_cached_pages * 0.25) + (total_pages_of_table * pct_not_cached_pages * 1)
eval_cost(163272.2) = estimated_rows * row_evaluate_cost
read_cost(73674.75) = MIN(worst_seek_cost, total_scan_cost*3)
query_cost(236946.95) = read_cost + eval_cost
ix_bid_createdat 인덱스 활용 실행 계획
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
estimated_rows = 1490996
pct_cached_pages(Index ix_bid_createdat) = 0.03005 %
pct_not_cached_pages(Index ix_bid_createdat) = (100 - 0.03005) %
row_evaluate_cost = 0.10
memory_block_read_cost = 0.25
disk_block_read_cost = 1.00
-- 1️⃣ keys_per_block (한 페이지당 키 개수)
keys_per_block(373.36) = 16 * 1024 / 2 / (8+5+1+8) + 1
-- 2️⃣ read_index_pages (읽어야 할 인덱스 페이지)
read_index_pages(3994.45) = (estimated_rows + keys_per_block - 1) / keys_per_block
-- 3️⃣ read_time (인덱스 읽기 시간)
read_time(3993.55) = (read_index_pages * pct_cached_pages * 0.25) + (read_index_pages * pct_not_cached_pages * 1)
eval_cost(149099.6) = estimated_rows * row_evaluate_cost
read_cost(153093.15) = eval_cost + read_time
query_cost(302192.75) = read_cost + eval_cost
이 계산 과정에서 ix_bid_id 인덱스가 채택될 수밖에 없는 결정적인 이유는 이 인덱스를 사용할 때 실행 계획의 read_cost를 매우 낮은 수준으로 판단했기 때문이다.
read_cost를 계산할 때 MySQL 옵티마이저는 worst_seek_cost와 total_scan_cost 2개의 값중에서 최소값을 선택하는데, worst_seek_cost는 ix_bid_id 인덱스를 읽고 레코드 건수만큼 데이터 페이지를 읽는 비용을 의미하고, total_scan_cost는 테이블의 모든 데이터 페이지를 읽는 비용을 의미한다.
그런데 total_scan_cost가 너무 낮은 비용으로 평가되면서 쿼리의 실행 계획이 잘못되었다. total_scan_cost가 너무 낮은 비용으로 계산된 이유는 ref 실행 계획의 비용은 ix_bid_id 인덱스가 아닌 PRIMARY 인덱스의 데이터 페이지 읽기를 계산하는데, 일반적으로 인덱스보다 데이터 파일의 페이지가 메모리에 상주할 가능성이 높기 때문이다.
처음에 살펴보았던 아래 쿼리도 ix_bid_id 가 아닌 ix_bid_createdat 인덱스를 사용하게 되는 이유는
1
SELECT COUNT(*) FROM tab WHERE bid=1198442 AND id<14025956;
range 접근 방식보다 ref 접근 방식의 비용이 낮게 계산되면서, 쿼리 조건에 딱 맞는 인덱스는 사용하지 못하고 조금 비슷한 패턴의 인덱스만 사용하도록 실행 계획이 수립되고 있었던 것이다.
비유하자면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
MySQL :
ix_bid_id 쓰면 두 가지 방법
1. 인덱스 읽고 → 테이블 하나씩 찾아가기 (worst_seek_cost)
2. 아니면 그냥 테이블 전체 스캔하기 (total_scan_cost)
이 중에 더 싼 걸로 선택
read_cost = MIN(worst_seek_cost, total_scan_cost × 3)
문제의 원인
total_scan_cost가 너무 낮게 계산됨
MySQL의 오류 원인:
"PRIMARY 테이블은 메모리에 많이 올라와 있음 (64.65%)
전체 스캔해도 별로 안 비쌈
total_scan_cost = 24,558 (매우 낮음)
worst_seek_cost = 84,096 (높음)
결과: MIN(84,096, 24,558×3) = 73,674 선택
현실:
- bid=1198442 레코드가 160만 개
- 160만 개마다 테이블 액세스 필요
- 메모리에 있어도 160만 번 읽기는 느림
Cost Model 해결 방법
아래 쿼리가 ix_bid_id 인덱스가 아닌 ix_bid_createdat 인덱스를 사용하도록 하려면, 옵티마이저의 단위 비용 상수를 조정하여 ref 접근 방법의 비용을 더 높이거나 range 접근 방법의 비용을 더 낮춰야한다
1
2
3
SELECT COUNT(*)
FROM tab
WHERE bid=1198442 AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
이 쿼리가 ix_bid_createdat 을 사용하지 못하고 ix_bid_id 를 사용하게 되는 가장 큰 이유는 읽는 레코드에 대해서 eval_cost (row_evaluate_cost) 가 전체 비용에 두번이나 영향을 미치고 있기 때문이다.
그래서 우리는 row_evaluate_cost 비용 상수를 더 낮은 값으로 설정해서, ix_bid_createdat 의 실행 계획 비용을 상대적으로 더 낮출 수 있다.
1
2
3
4
5
6
UPDATE mysql.server_cost
SET cost_value=0.03 /* 데이터 분포도에 따라서 옵티마이저는 여전히 ix_bid_id 인덱스를 선호할 수 있음*/
WHERE cost_name='row_evaluate_cost';
FLUSH OPTIMIZER_COSTS;
-- // 현재 세션은 종료하고, 새로 MySQL 서버에 로그인해야 변경된 비용으로 쿼리 실행 계획이 수립되는 것을 확인할 수 있음
다시 쿼리의 실행 계획 실행하면
1
2
3
4
5
6
mysql> EXPLAIN SELECT COUNT(*) FROM tab WHERE bid=1198442 AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
+-------+------------------+---------+------+---------+----------+--------------------------+
| type | key | key_len | ref | rows | filtered | Extra |
+-------+------------------+---------+------+---------+----------+--------------------------+
| range | ix_bid_createdat | 14 | NULL | 1490996 | 100.00 | Using where; Using index |
+-------+------------------+---------+------+---------+----------+--------------------------+
쿼리의 실행 계획이 ix_bid_createdat 인덱스를 사용하도록 변경되었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
mysql> EXPLAIN FORMAT=JSON
SELECT /*+ INDEX(tab ix_bid_id) */ COUNT(*)
FROM tab
WHERE bid=1198442 AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
...
"cost_info": {
"read_cost": "73429.79",
"eval_cost": "16325.59",
"prefix_cost": "122411.45",
"data_read_per_join": "24M"
},
mysql> EXPLAIN FORMAT=JSON
SELECT /*+ INDEX(tab ix_bid_createdat) */ COUNT(*)
FROM tab
WHERE bid=1198442 AND created_at<DATE_SUB(NOW(), INTERVAL 9 HOUR);
...
"cost_info": {
"read_cost": "48727.16",
"eval_cost": "44729.88",
"prefix_cost": "93457.04",
"data_read_per_join": "68M"
},
실제 쿼리의 비용을 한번 살펴보면,
ix_bid_id 인덱스를 사용하는 실행 계획은 전체 비용이 122411.45로 감소했고, ix_bid_createdat인덱스를 사용하는 실행 계획은 93457.04로 비용이 더 크게 감소했다.
References
-
Ref Access Cost 관련 주요 코드
-
Range Access Cost 관련 주요 코드