MySQL vs Elasticsearch 검색 성능 비교
MySQL vs Elasticsearch 검색 성능 비교
Introduction
이 글에서는 전통적인 관계형 데이터베이스인 MySQL의 전문 검색(Full-Text Search)과 전문 검색 엔진인 Elasticsearch에 대해 알아보고자 한다.
MySQL의 Full-Text-Search
문장이나 문서 내용에서 키워드를 검색하는 기능
인덱싱 방식
1. 구분자(Stopword) 방식
- MySQL 5.6 이전까지 사용된 기본 방식
- 띄어쓰기나 특정 기호를 기준으로 단어를 구분하여 인덱스 구축
- “a”, “the”, “by”와 같이 의미 없는 단어는 제외
2. N-gram 방식
- MySQL 5.7부터 InnoDB에서 지원
- 한국어/중국어/일본어(CJK)와 같이 공백만으로 단어를 파싱할 수 없는 언어에 효과적
- 텍스트를 일정 길이(기본값 2)로 나누어 인덱싱
- 예: “대한민국”를 2-gram(bi-gram)으로 분석하면 “대한”, “한민”, “민국” 으로 토큰화
설정 및 특징
ngram_token_size : 인덱싱할 토큰의 크기를 설정(기본값 2)
- 이 값보다 짧은 검색어는 검색 불가
- 값이 낮을수록 토큰 수가 많아져 인덱스 크기 증가
MySQL 5.7 이후 사용 방법:
1
2
3
4
5
CREATE TABLE articles (
id BIGINT AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(100),
FULLTEXT INDEX ngram_idx(title) WITH PARSER ngram
) Engine=InnoDB;
검색 방법:
1
2
SELECT * FROM articles
WHERE MATCH(body) AGAINST('검색어' IN BOOLEAN MODE);
Elasticsearch 검색
Elasticsearch는 분산형 RESTful 검색 및 분석 엔진으로, 대용량 데이터를 실시간으로 검색하고 분석할 수 있는 시스템
핵심 특징 및 작동 방식
RDBMS에서 이렇게 저장된 데이터가 있을 때,

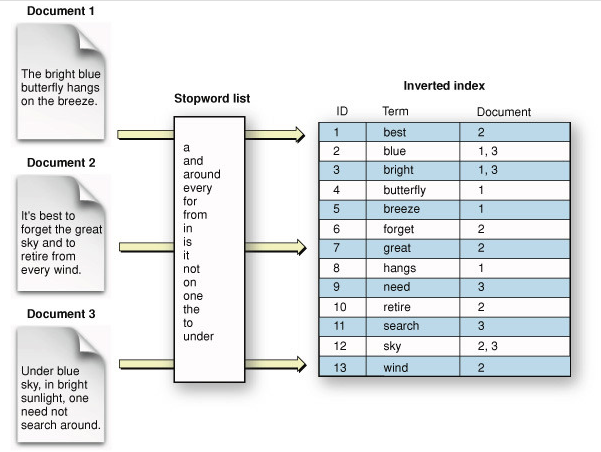
1. 역색인(Inverted Index) 구조

- 문서 내용을 분석하여 형태소 단위로 자르고 조사를 삭제해 의미 있는 데이터만 추출
- 검색어에 대해 유사도 점수 부여 가능
2. 랭킹 알고리즘
Elasticsearch 5.0부터 BM25 알고리즘 사용(이전에는 TF/IDF)
- TF(Term Frequency): 검색어가 문서에 많이 있을수록 점수 상승
- IDF(Inverse Document Frequency): 전체 문서에서 흔한 단어일수록 점수 하락
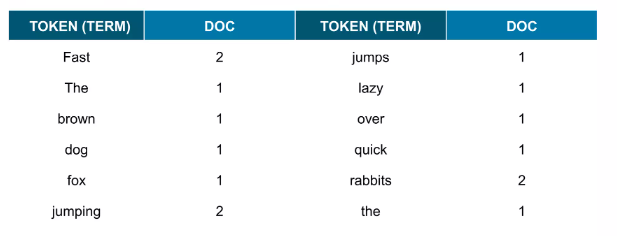
3. 텍스트 분석(Text Analysis) 과정
- 애널라이저(Analyzer): 0~3개의 캐릭터 필터, 1개의 토크나이저, 0~n개의 토큰 필터로 구성
- 토큰화: 텍스트를 분석해 검색에 용이한 단위로 분할
4. 분산 처리 아키텍처
- 클러스터, 노드, 샤드 개념으로 구성
- 노드는 Elasticsearch 클러스터에 포함된 단일 서버로, 데이터를 저장하고 클러스터의 색인화 및 검색 기능에 참여
- 수평적 확장 가능
텍스트 처리 과정
실제 저장될때는 다음과 같은 과정을 거친다.
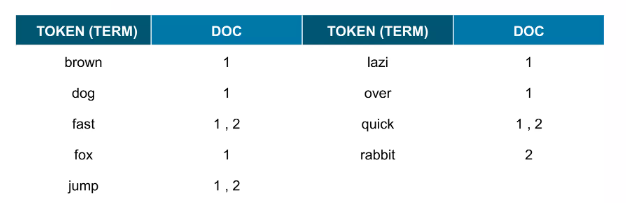
대소문자 변환
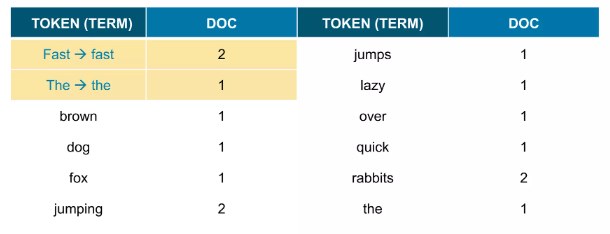
토큰 재정렬 (일반적으로 ASCII순서)
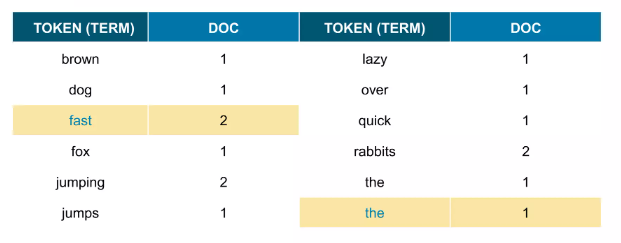
불용어(stopwords; 검색어로서 가치 없는 단어들) 를 제거 ( a, an, are, at, be, but, by, for, i, no, the, to, … 등등 )
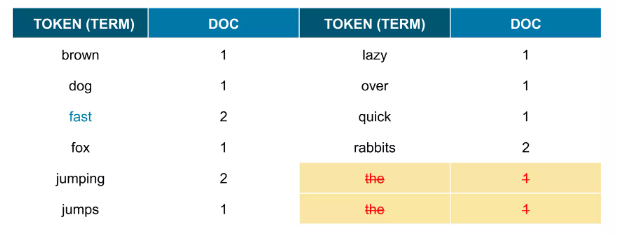
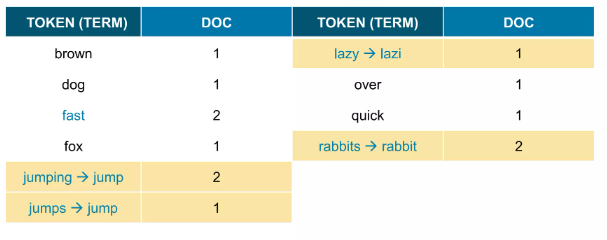
형태소 분석 과정 ( ~s, ~ing, 등을 제거하는 과정; 한글은 의미분석때문에 더 복잡하다)
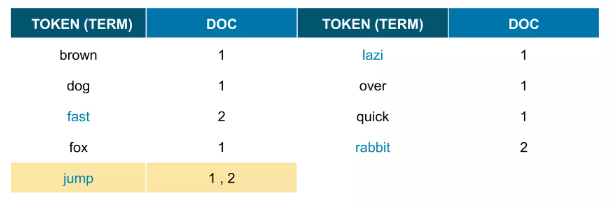
같아진 토큰들 병합
동의어 처리
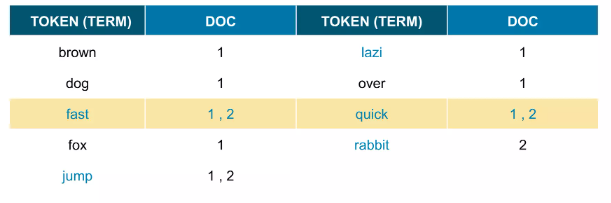
검색 과정
검색어도 똑같이 텍스트 처리 과정을 거친다.
ex) “The lazy spiders” 라고 검색
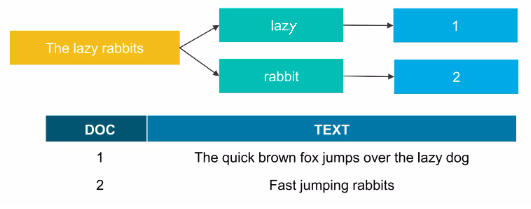
검색엔진과 RDBMS 비교
| RDBMS | 검색엔진 | |
|---|---|---|
| 데이터 저장 방식 | 정규화 | 역정규화 |
| 전문(Full Text) 검색 속도 | 느림 | 빠름 |
| 의미 검색 | 불가능 | 가능 |
| Join | 가능 | 불가능 |
| 수정 / 삭제 | 빠름 | 느림 |
Elasticsearch 클러스터링 과정
대용량 검색을 위해서는 클러스터링이 필요하다.
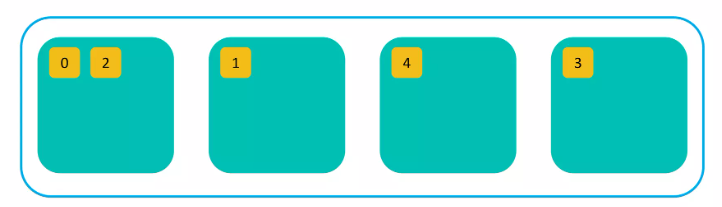
Elasticsearch는 데이터를 “샤드(Shard)” 단위로 분리해서 저장한다.
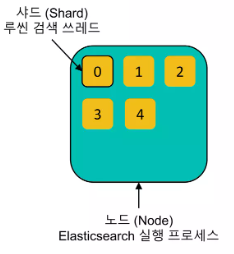
노드를 여러개 실행시키면 같은 클러스터로 묶인다.
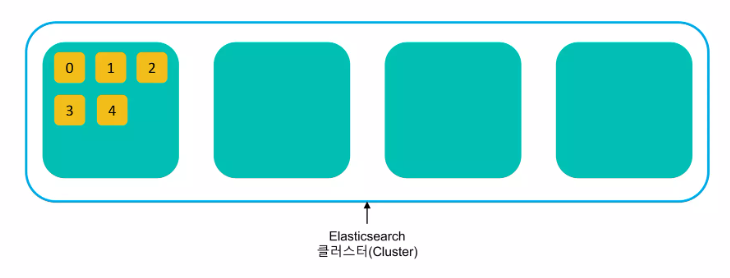
샤드들이 각각의 노드들에 분배된다.
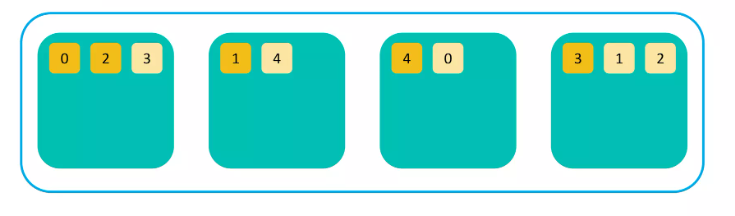
무결성과 가용성을 위해 샤드의 복제본을 만든다. (같은 내용의 복제본과 샤드는 서로 다른 노드에 저장된다)
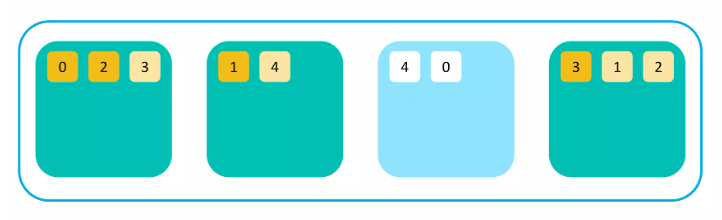
시스템 다운이나 네트워크 단절 등으로 유실된 노드가 생기면
복제본이 없는 샤드들은 다른 살아있는 노드로 복제를 시작한다.
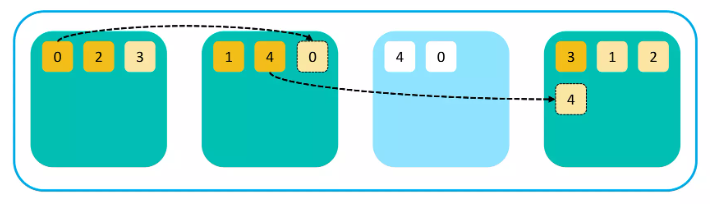
노드의 수가 줄어도 샤드의 수는 변함없이 무결성을 유지할 수 있다.
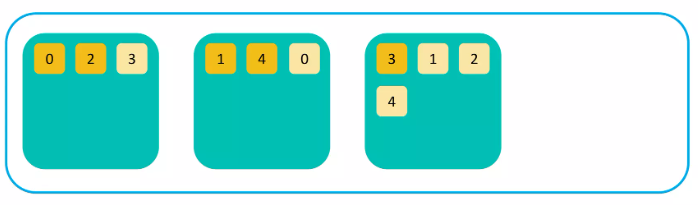
클러스터링 후…
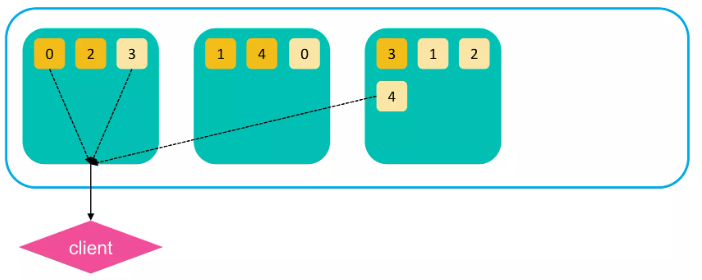
검색 과정 (Query Phase)
1. 처음 쿼리 수행 명령을 받은 노드는 모든 샤드에게 쿼리를 전달한다.
1차적으로 모든 샤드(or 복제본) 검색을 실행
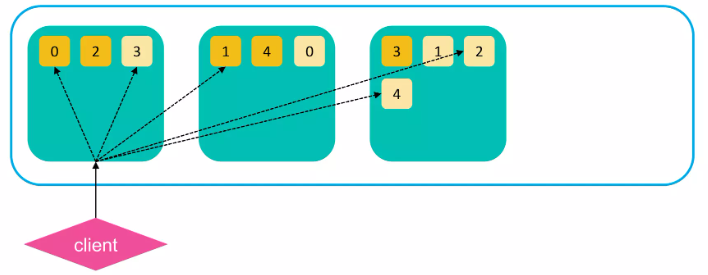
2. “from + size” 크기의 결과 큐를 처음 명령 받은 노드로 리턴한다.
- 리턴된 결과는 doc ID와 랭킹 점수만 포함하고 있다.
- 조정 노드는 이 결과들을 합치고, 랭킹 점수를 기준으로 정렬한다.
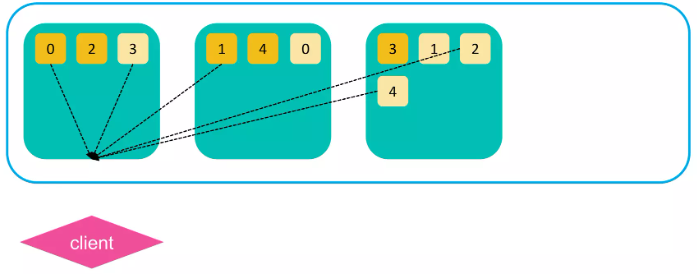
1
2
from: 결과 집합에서 시작할 위치(인덱스)를 지정. 0부터 시작하며, 기본값은 0아다.
size: 가져올 결과의 개수를 지정. 기본값은 10이다.
이후 문서 데이터를 가져오는 Fetch Phase 진행
검색 과정 (Fetch Phase)
1. 정렬된 값 기반으로 유효한 샤드들에 검색 결과를 요청.
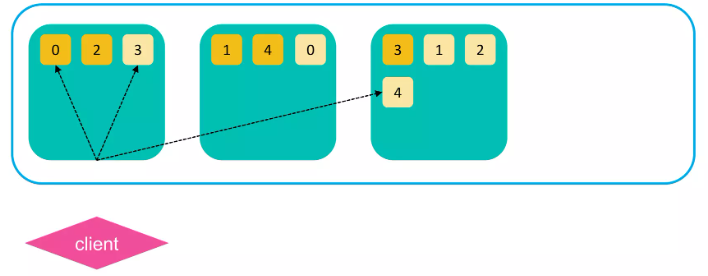
2. 전체 문서 내용 (_source) 등의 정보가 리턴되어 클라이언트로 전달된다.
랭킹 알고리즘
TF/IDF
Term Frequency: 찾는 검색어가 문서에 많을수록 해당 문서의 정확도가 높다.Inverse Document Frequency: 전체 문서에서 많이 출현한(흔한) 단어일수록 가중치가 낮다.
검색 랭킹이 중요한 이유
- 사용자들은 대부분 처음 나온 결과만 봄.
- 결과값이 큰 내용을 fetch하는 것은 상당히 부하가 큼 1 ~ 1,000을 fetch하는 것이나 990 ~ 1,000을 fetch하는 것이나 쿼리 작업 규모가 비슷하다.
루씬 세그먼트란?
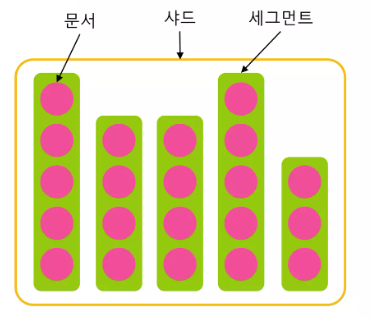
- 루씬은 inverted index를 하나의 거대한 파일이 아니라 여러개의 작은 파일 단위로 저장
- 하나씩 데이터가 들어가거나, 1초 마다 하나씩 생성
- 한번 생성된 세그먼트는 변경되지 않습니다(immutable)
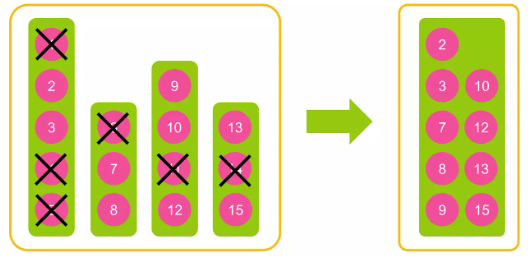
문서 변경/삭제 과정
- 한번 생성된 세그먼트는 변경되지 않습니다.
- update는 없다. 모두 delete & insert
- 문서를 삭제하면 삭제되었다는 상태만 표시하고 검색에서 제외
- 세그먼트 병합 과정은 비용이 큰 동작
세그먼트 병합(Segment Merge)
References
This post is licensed under
CC BY 4.0
by the author.