Operating System Concepts - 실시간 CPU 스케줄링

Operating System 공룡책 5.6절의 실시간 CPU 스케줄링에 대해 정리해보았다
실시간 CPU 스케줄링
실시간 CPU 스케줄링은 연성(soft) 실시간 시스템과 경성(hard) 실시간으로 구분
-
연성 실시간 시스템 중요한 실시간 프로세스가 스케줄 되는 시점에 관해 아무런 보장을 하지 않는다. 오직 중요 프로세스가 그렇지 않은 프로세스들에 비해 우선권을 가진다는 것만 보장
-
경성 실시간 시스템 태스크는 반드시 마감시간까지 서비스를 받아야 한다. → 더 엄격한 요구 조건을 만족해야 함 마감시간이 지난 이후에 서비스를 받는 것은 서비스를 받지 않는 것과 같다.
1. 지연시간 최소화 (Minimizing Latency)
실시간 시스템의 이벤트-중심 특성
- 시스템은 일반적으로 실시간으로 발생하는 이벤트를 기다린다.
- 이벤트가 발생하면 시스템은 가능한 한 빨리 그에 응답하고 그에 맞는 동작을 수행해야 한다.
- 이벤트의 소프트웨어적 발생 → ex) 타이머 만료 등
- 이벤트의 하드웨어적 발생 → ex) 원격으로 제어되던 장치가 방해물을 만났을 때
이벤트 지연 시간
이벤트가 발생해서 그에 맞는 서비스가 수행될 때까지의 시간
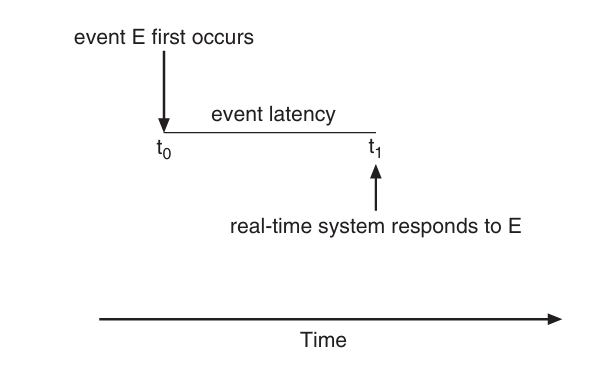 이벤트가 다르면 그에 따른 지연시간 역시 다르다.
이벤트가 다르면 그에 따른 지연시간 역시 다르다.
2가지 유형의 지연시간
- 인터럽트 지연시간
- 디스패치 지연시간
1. 인터럽트 지연시간
CPU에 인터럽트가 발생한 시점부터 해당 인터럽트 처리 루틴이 시작하기까지의 시간
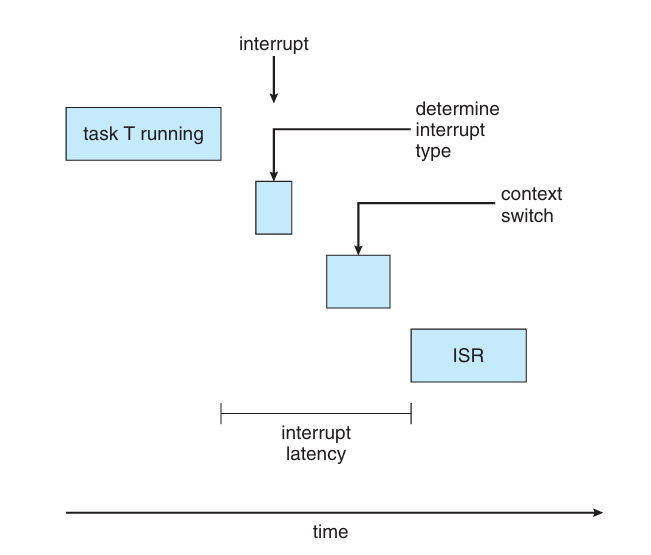
인터럽트 발생 시 과정
- 수행 중인 명령어를 완수
- 발생한 인터럽트의 종류를 결정
- 결정한 인터럽트 서비스 루틴(ISR)을 사용하여 인터럽트를 처리하기 전에 현재 수행 중인 프로세스의 상태를 저장
→ 이러한 작업을 모두 수행하는 데 걸리는 시간이 인터럽트 지연 시간
실시간 태스크의 즉시 수행을 위해 인터럽트 지연시간을 최소화하는 것은 실시간 운영체제의 핵심
경성(hard) 실시간 시스템 (엄격한 요구조건) 에서는 인터럽트 지연시간을 최소화 + 정해진 시간보다 작아야 함
인터럽트 지연시간에 영향을 주는 요인
- 커널 데이터 구조체를 갱신하는 동안 인터럽트가 불능케 되는 시간 → 실시간 운영체제는 인터럽트 불능 시간을 매우 짧게 해야 함
2. 디스패치 지연시간
스케줄링 디스패처가 하나의 프로세스를 블록 시키고 다른 프로세스를 시작하는 데까지 걸리는 시간
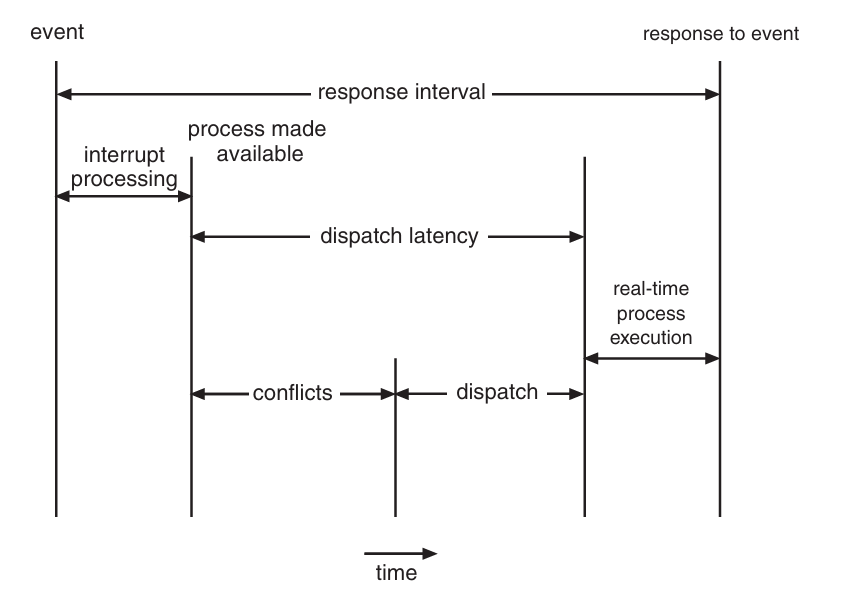
CPU를 즉시 사용해야 하는 실시간 태스크가 있다면, 이 지연시간을 최소화해야 함
디스패치 지연시간을 최소화하는 가장 효과적인 방법 → 선점형 커널
디스패치 지연시간의 충돌 단계
- 커널에서 동작하는 프로세스에 대한 선점
- 높은 우선순위의 프로세스가 필요한 자원을 낮은 우선순위 프로세스 자원이 방출
충돌 단계에 이어 디스패치 단계는 우선순위가 높은 프로세스를 사용 가능한 CPU에 스케줄 한다.
2. 우선순위 기반 스케줄링 (Priority-Based Scheduling)
실시간 운영체제에서 가장 중요한 기능
- 실시간 프로세스에 CPU가 필요할 때 바로 응답해 주는 것
- 따라서 실시간 운영체제의 스케줄러는 선점을 이용한 우선순위 기반의 알고리즘을 지원해야 한다.
선점 및 우선순위 기반의 스케줄링 알고리즘
-
각각의 프로세스의 중요성에 따라 우선순위를 부여
-
더 중요한 태스크가 그렇지 않은 태스크들보다 더 높은 우선순위를 갖게 됨
-
스케줄러가 선점 기법을 제공하는 경우, 현재 CPU를 이용하고 있는 프로세스가 더 높은 우선순위를 갖는 프로세스에 선점될 수 있다.
연성 실시간 스케줄링 사례
- Linux, Windows, Solaris 운영체제
- 실시간 프로세스에게 가장 높은 스케줄링 우선권을 부여
- Windows에는 32개의 우선순위가 존재함
- 가장 높은 순위인
16 ~ 31의 값이 실시간 프로세스들에 할당
- 가장 높은 순위인
경성 실시간 시스템에 적합한 스케줄링 알고리즘
- 선점 및 우선순위 기반의 스케줄러를 통해 제공할 수 있는 것은 연성 실시간 기능뿐
- 경성 실시간 시스템에서의 마감시감 내에 확실히 수행되는 것을 보장하지 못한다. → 경성 실시간 시스템에 맞는 부가적인 스케줄링 기법이 필요하다.
개별 스케줄러에 스케줄 될 프로세스의 특성
- 프로세스들은 주기적이다. 즉, 프로세스들은 일정한 간격으로 CPU가 필요하다.
- 각각의 주기 프로세스들은 CPU 사용권을 얻을 때마다
t,d,p가 정해져 있다.t: 고정된 수행시간d: CPU로부터 반드시 받아야 하는 마감시간p: 주기 (주기 태스크의 실행 빈도는1/p)0 ≤ t ≤ d ≤ p
스케줄러는 이들의 주기, 마감시간, 수행 시간 사이의 관계를 이용하여 마감시간을 정한다.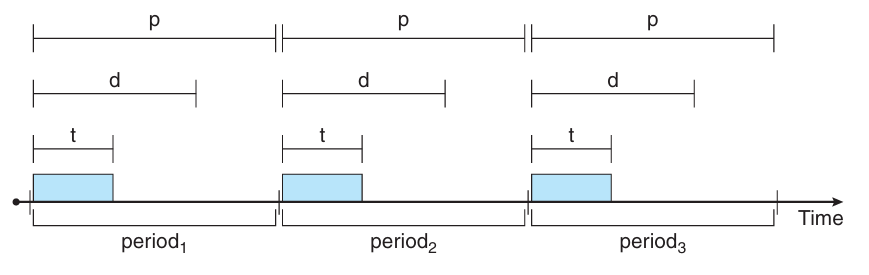
스케줄러는 주기적 프로세스의 실행 빈도에 따라서 우선순위를 정함
승인 제어(admission-control)
위와 같은 형식의 스케줄링에서 일반적이지 않을 때 프로세스가 자신의 마감시간을 스케줄러에게 알려줘야 할 수도 있음 → 승인 제어 알고리즘
승인 제어를 통해 스케줄러는 마감시간 이내에 완수할 수 있는 프로세스는 실행을 허락하고, 그렇지 못한 경우에는 요구를 거절한다.
3. Rate-Monotonic 스케줄링 (Rate-Monotonic Scheduling)
선점 가능한 정적 우선순위 정책을 이용하여 주기 태스크들을 스케줄 한다.
낮은 우선순위의 프로세스가 실행 중이고 높은 우선순위의 프로세스가 실행 준비하면 높은 우선순위의 프로세스가 낮은 우선순위의 프로세스를 선점
각각의 주기 태스크들은 시스템 진입 시 주기에 따라 우선순위가 정해짐 주기가 짧을수록 높은 우선순위에 배정
(CPU를 더 자주 필요로 하는 태스크에 더 높은 우선순위를 주려는 원리)
rate-monotonic 스케줄링은 주기 프로세스들의 처리 시간은 각각의 CPU 버스트와 같다고 가정
즉, 프로세스가 CPU를 차지한 시간 = 각각의 CPU 버스트 시간
ex) 우선순위 P2 > P1
2개의 프로세스 P1, P2
- P1의 주기 = 50, 수행 시간 = 20
- P2의 주기 = 100, 수행 시간 = 35
Q) 두 프로세스가 마감시간을 충족시키도록 스케줄링이 가능한가?
→ CPU 이용률, 즉 주기에 대한 수행 시간을 계산
- P1의 CPU 이용률 = 2/5 = 0.4
- P2의 CPU 이용률 = 35/100 = 0.35
총 CPU 이용률 75% → 마감시간을 모두 충족시킬것이라 예상
Case 1) Rate-Monotonic 스케줄링을 사용하지 않은 경우
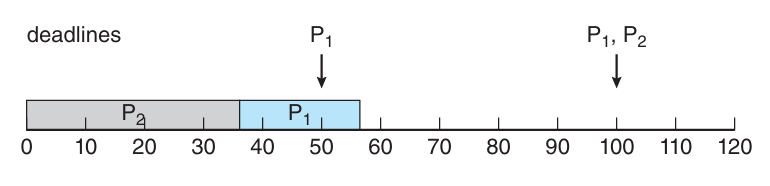
(P2 > P1라 가정)
P1의 마감시간이 50인데 P1은 55에 끝나기 때문에 스케줄러 P1의 마감시간을 충족시키지 못한다.
Case 2) Rate-Monotonic 스케줄링을 사용한 경우

P1의 주기가 P2의 주기보다 짧음 → P1 > P2
수행 과정
- P1이 먼저 수행이 시작하여 시간 20에 수행이 종료 → P1의 마감시간 만족
- 바로 P2가 수행을 시작해서 시간 50까지 수행을 끝낸다. (P1에게 선점됨) 이때 아직 5ms의 CPU 할당 시간이 남아있는 상태
- P1은 시간 70까지 수행을 하고, 스케줄러는 다시 P2를 수행시킴
- P2는 남은 5ms의 시간의 수행을 75에 끝낸다. → P2의 마감시간 만족
- 시스템은 시간 100까지 유휴시간을 갖다가 P1이 다시 스케줄 된다.
Rate-monotonic 스케줄링 기법이 스케줄 할 수 없는 프로세스 집합
해당 스케줄링 기법이 스케줄링할 수 없다면 정적 우선순위를 이용하는 다른 알고리즘 역시 스케줄링할 수 없다.
N개의 프로세스를 스케줄 하는 데 있어 허용하는 CPU 이용률
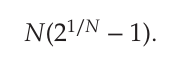
예시 2개의 프로세스 p1, p2
- p1의 주기 = 50, 수행시간 = 25
- p2의 주기 = 80, 수행시간 = 35 전체 CPU 이용률 → 25/50 + 35/80 = 0.94 = 94%
2개의 프로세스를 스케줄 하는데 허용하는 CPU 이용률 = 2 * (1.414 - 1) = 0.828 = 약 83%
→ 스케줄 불가능
4. Earliest-Deadline-First 스케줄링 (EDF)
마감시간에 따라서 우선순위를 동적으로 부여 마감시간이 빠를수록 우선순위가 높아진다.
프로세스가 실행 가능하게 되면 자신의 마감시간을 시스템에 알려야 함
우선순위는 새로 실행 가능하게 된 프로세스의 마감시간에 맞춰 다시 조정 → 우선순위가 고정되어 있는 rate-monotonic 스케줄링과는 다름
ex) 2개의 프로세스 p1과 p2
- p1의 주기 = 50, 수행시간 = 25
- p2의 주기 = 80, 수행시간 = 35

스케줄링 과정
-
P2는 P1의 CPU 버스트가 끝난 후 수행을 시작 처음에는 프로세스 P1의 마감시간이 더 빠르기 때문에 P1의 우선순위가 P2보다 높다.
-
시간 50에서 P2의 마감시간은 80, P1의 마감시간은 100이다. → EDF에 의해 우선순위는 P2 > P1, P2를 계속 수행 (rate-monotonic 스케줄링에서는 시간 50에서 P1이 선점했다.)
-
시간 60에 P2의 CPU 버스트가 끝난다. → P1과 P2 모두 첫 번째 마감시간을 만족
-
프로세스 P1은 시간 60에 다시 수행을 시작하여 시간 85에 두 번째 CPU 버스트가 종료
-
P2는 다시 수행을 시작하고 다음 주기인 시간 100에 P1에게 선점된다. P1 > P2 ( P1의 마감시간 = 150, P2의 마감시간 = 165 )
-
시간 125에서 P1은 CPU 할당량을 완수하고 P2가 수행을 시작하여 시간 145에 끝난다. → 둘 다 마감시간 만족
-
시간 150까지 유휴시간을 가지고 다시 P1이 스케줄 되어 수행을 시작 …
EDF 스케줄링 알고리즘 특징
- 프로세스들이 주기적일 필요 없다.
- CPU 할당 시간이 상수 값으로 정해질 필요가 없다.
- 중요한 것은 프로세스가 실행 가능해질 때 자신의 마감시간을 스케줄러에게 알려주는 것
- 이론적으론 최적의 알고리즘: 모든 프로세스가 마감시간을 만족할 수 있고, CPU 이용률 100% 하지만 프로세스 사이, 인터럽트 핸들링 때의 문맥교환 비용에 의해 100% CPU 이용은 불가능
5. 일정 비율의 몫 스케줄링 (Proportional share)
모든 응용들에게 T개의 시간 몫을 할당하여 동작 한 개의 응용이 N개의 시간 몫을 할당받으면 그 응용은 모든 프로세스 시간 중 N/T를 할당받는 것
승인 제어 정책과 함께 동작
- 사용 가능한 충분한 몫이 존재할 때 그 범위 내의 몫을 요구하는 클라이언트에게만 실행을 허락해죽, 몫을 초과하면 시스템 진입을 거부