Operating System Concepts - (3)

Operating System Concepts - (3)
프로세스 관리 ( ch.3 )
Process Creation (프로세스 생성)
- Parent Process (부모 프로세스) 가 Children Process (자식 프로세스) 생성 ( 복제 생성; 프로세스가 또 다른 프로세스를 만드는 구조)
- 프로세스의 트리(계층 구조)가 형성됨
- 프로세스는 자원을 필요로 하고 자원은 운영체제(OS)로부터 받거나 부모와 공유함
- 자원의 공유
- 부모와 자식이 모든 자원을 공유하는 모델
- 일부를 공유하는 모델 (모든 자원을 공유하는 것보다 더 효율적임) ex) Linux
- 전혀 공유하지 않는 모델
- 자원의 공유
- Execution (수행)
- 부모와 자식 공존하며 수행되는 모델
- 자식이 terminate될 때까지 부모가 기다리는(wait = blocked) 모델
- 주소 공간(Address space)
- 자식은 부모의 문맥(공간)을 복사 (binary and OS data) -> Code, Data, Stack 전부 복사
- Data : 전역변수 & 데이터 그대로 가져감
- Stack : 현재 어디서부터 실행되었는가? 가 저장됨 -> 그 위치부터 시작
- PC(Program Counter) Register도 그대로 복사
- 자식은 그 공간에 새로운 프로그램을 올림
- 자식은 부모의 문맥(공간)을 복사 (binary and OS data) -> Code, Data, Stack 전부 복사
Copy-on-Write(COW)
- Write가 발생했을 때 Copy가 실행되는 것
- 내용이 변경된 경우에만 Copy를 진행, 그 전까진 공유만 함
- Ex) Unix
fork()시스템 콜이 새로운 프로세스를 생성- 부모를 그대로 복사 (OS data except PID + binary)
- 주소 공간 할당
- 시스템 콜이 호출되는 것이므로 OS가 해당 작업(프로세스 생성)을 대신 수행하는 의미!
- fork 다음에 이어지는
exec()시스템 콜을 통해 새로운 프로그램을 메모리에 올림.
- Ex) Unix
< 프로세스의 생성과정 >
- 부모 프로세스의 복제 (자식 프로세스 생성) –>
fork() - 새로운 프로세스를 주소 공간에 덮어씌움 –>
exec()
Process Termination (프로세스 종료)
Exit()- 프로세스가 마지막 명령을 수행한 후 OS에 알려줌- 자식이 부모에게 output data 보냄 (via wait)
- OS로 프로세스의 각종 자원들이 반납됨.
- 프로세스에서 자식 프로세스가 먼저 종료되고 부모 프로세스가 종료되어야 함
- 부모 프로세스가 자식 프로세스의 수행을 종료시킴 ( abort - 강제 종료 )
- 자식이 할당 자원의 한계치를 넘어섬
- 자식에게 할당된 태스크가 더 이상 필요하지 않음
- 부모가 종료(exit)하는 경우
- OS는 부모 프로세스가 종료하는 경우 자식이 더 이상 수행되도록 하지 않음
- 강제 종료 시에도 자식 프로세스가 먼저 종료 후 부모 프로세스가 종료되기 때문에 단계적 종료가 발생
fork() System Call
- A process is created by the
fork()system call- ✔ creates a new address space that is a duplicate of the caller - 발신자의 중복된 새 주소 공간을 만듦
1 2 3 4 5 6 7 8 9 10
int main() { int pid; pid = fork(); # fork() 함수가 실행되면 하나의 프로세스가 더 생성된다고 이해하는 것이 쉬움. if(pid == 0) { printf("\nHello, I am child!\n"); } eise if (pid > 0) { printf("\nHello, I am parent!\n"); } }
- ✔ creates a new address space that is a duplicate of the caller - 발신자의 중복된 새 주소 공간을 만듦
exec() System Call
- A process can execute a different program by the
exec()system call- ✔ replaces the memory image of the caller with a new program - 발신자의 메모리 이미지를 새 프로그램으로 대체
1 2 3 4 5 6 7 8 9 10 11 12 13 14
int main() { int pid; pid = fork(); # fork() 함수가 실행되면 하나의 프로세스가 더 생성된다고 이해하는 것이 쉬움. if(pid == 0) { # this is child printf("\nHello, I am child! Now I'll run date \n"); execlp("/bin/date", "/bin/date", (char *) 0); # execlp는 새로운 프로그램으로 덮어씌우는 함수, ( char * ) 0 은 제로포인터 } eise if (pid > 0) { # this is parent printf("\nHello, I am parent!\n"); } }
- ✔ replaces the memory image of the caller with a new program - 발신자의 메모리 이미지를 새 프로그램으로 대체
wait() System Call
- 자식이 종료(terminate)될 때까지 부모가 기다리는(wait = blocked) 모델
- 프로세스 A가
wait()시스템 콜을 호출하면- 커널은 child가 종료될 때까지 프로세스 A를 sleep 시킴 (block 상태)
- child process가 종료되면 커널은 프로세스 A를 깨움 (ready 상태)
- 프로세스 A가
1
2
3
4
5
6
7
8
9
10
11
12
13
main {
int childPID;
S1;
childPID = fork();
# 0이면 자식 프로세스를 위한 코드 생성
if(childPID == 0) {
} else {
# 부모 프로세스인 경우 wait() 실행
# 자식 프로세스가 종료될 때까지 기다리는 모델
wait();
}
S2;
}
정리 💡 프로세스와 관련된 시스템 콜
fork()- Create a child (copy)- 부모 프로세스에서 복제하여 자식 프로세스 생성
exec()- overlay new image- 새로운 프로그램으로 덮어씌우는 시스템 콜
wait()- sleep until child is done- 자식 프로세스가 종료될 때까지 대기
exit()- frees all the resources, notify parent- 모든 자원을 반납하고 부모 프로세스에게 종료되었다고 알림.
exit() System Call
- 프로세스의 종료
- 자발적 종료
- 마지막 statement 수행 후
exit()시스템 콜을 통해 중료 수행됨 - 프로그램에 명시적으로 적어주지 않아도 main 함수가 리턴되는 위치에 컴파일러가 넣어줌
- 마지막 statement 수행 후
- 비자발적 종료
- 부모 프로세스가 자식 프로세스를 강제 종료시킴
- 자식 프로세스가 한계치를 넘어서는 자원 요청
- 자식에게 할당된 Task가 더 이상 필요하지 않음
- 키보드로 kill, break 등을 친 경우
- 부모가 종료하는 경우
- 부모 프로세스가 종료되기 전에 자식들이 먼저 종료됨
- 부모 프로세스가 자식 프로세스를 강제 종료시킴
- 자발적 종료
## 프로세스 간 협력 (p.137 참조)
- Independent Process (독립적 프로세스)
- 프로세스는 각자의 주소 공간을 가지고 수행되므로 원칙적으로 하나의 프로세스는 다른 프로세스의 수행에 영향을 미치지 못함
- 경우에 따라서는 프로세스가 협력을 해야만 서로 효율적으로 실행되기도 함
- Cooperating Process (협력 프로세스)
- 프로세스 협력 메커니즘을 통해 하나의 프로세스가 다른 프로세스의 수행에 영향을 미칠 수 있음
- IPC : Interprocess Communication (프로세스 간 협력 메커니즘)
- 메세지를 전달하는 방법
- Message passing : 커널을 통해 메시지 전달.
- 프로세스 A가 프로세스 B에게 메세지를 전달함으로써 프로세스 B가 작업을 수행하는 것. 중간 커널이 메신저 역할을 해줌
- Message passing : 커널을 통해 메시지 전달.
- 주소 공간을 공유하는 방법
- shared memory : 서로 다른 프로세스 간에도 일부 주소 공간을 공유하게 하는 shared memory 메커니즘이 있음.
- 🚩 thread : Thread는 사실상 하나의 프로세스이므로 프로세스간 협력으로 보기는 어렵지만 동일한 process를 구성하는 thread들 간에는 주소 공간을 공유하므로 협력이 가능
- 메세지를 전달하는 방법
Message Passing
- Message System
- 프로세스 사이에 Shared variable (공유 변수)를 일체 사용하지 않고 통신하는 시스템
- Communication 방법에 관계 없이 운영체제 커널이 메세지를 전달하는 통신을 진행
- Direct Communication
- 통신하려는 프로세스의 이름을 명시적으로 표시
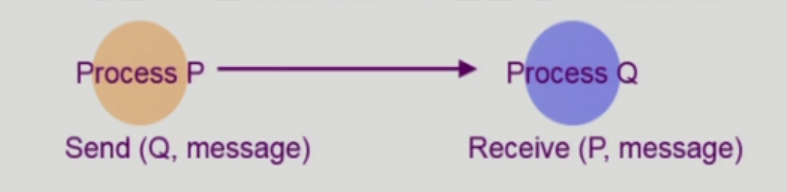
- 통신하려는 프로세스의 이름을 명시적으로 표시
- Indirect Communication
- mailbox(or port)를 통해 메세지를 간접 전달
- mailbox 역시 커널 안에 존재하는 것.

IPC Interprocess Communication
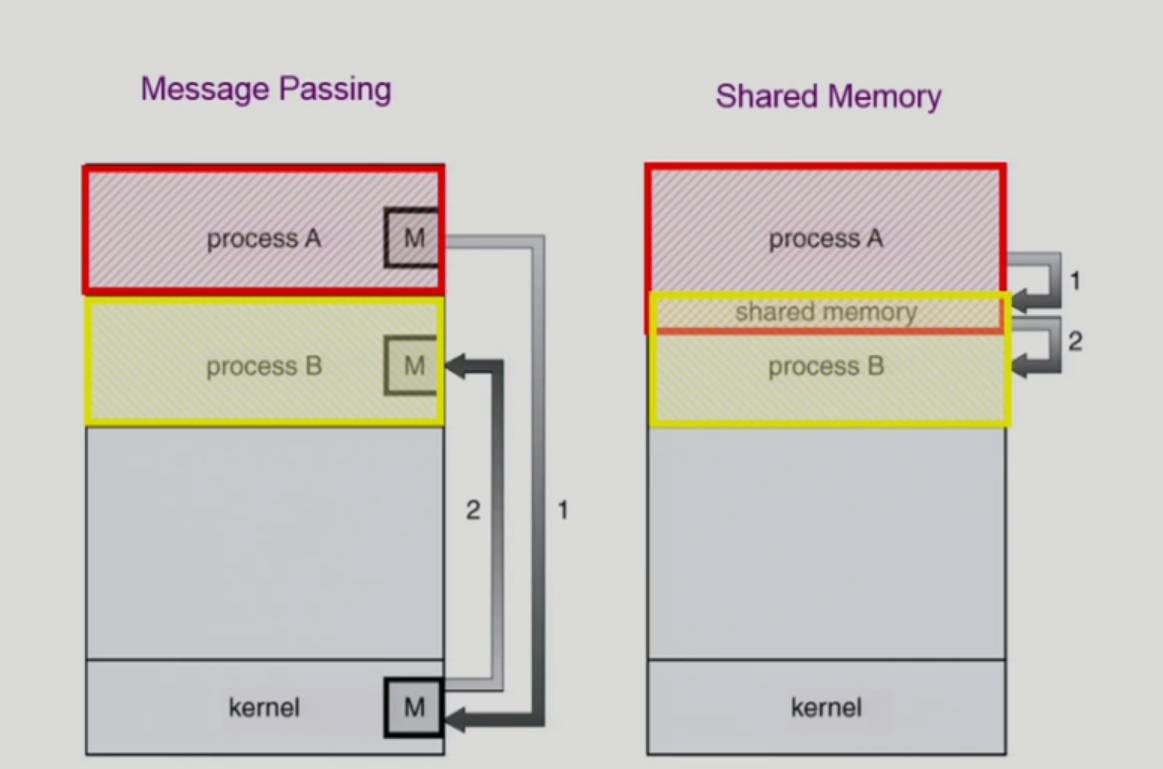
- 각각 주소공간이 따로 있지만, 일부의 shared 공간을 같이 사용하는 형태
- kernel에 명령을 보내 shared 공간을 쓴다는 것을 알려야 사용 가능함.
CPU Scheduling
CPU and I/O Bursts in Program Execution
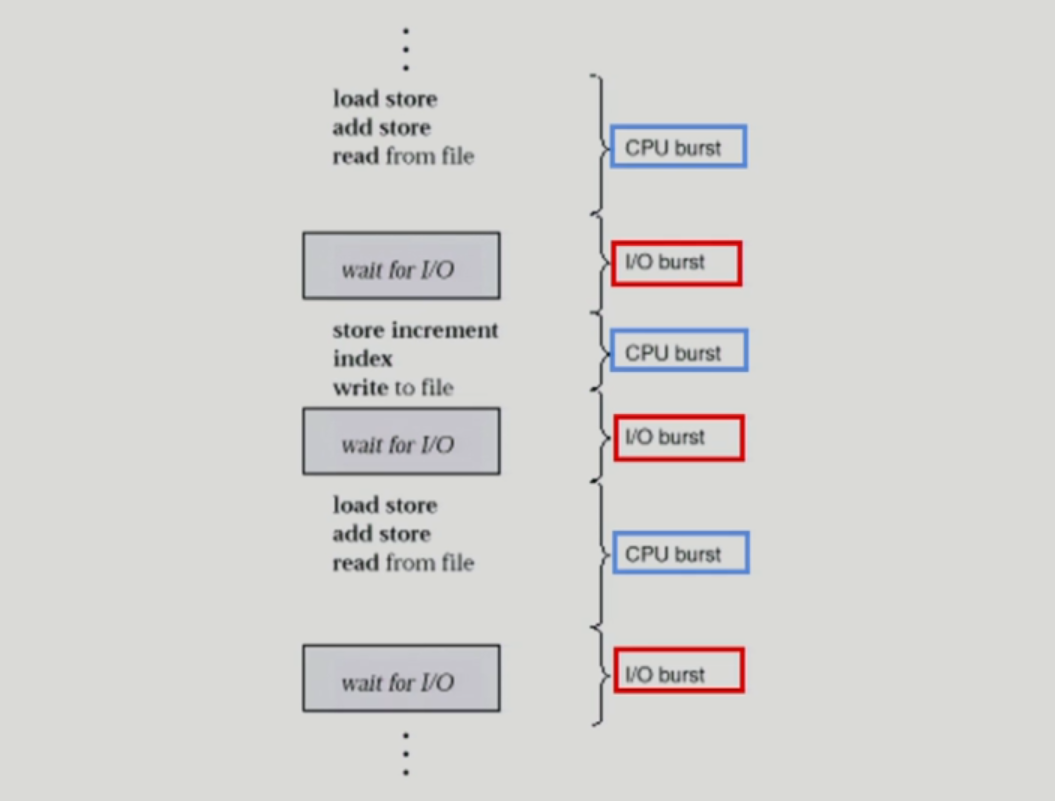
- 명령어 실행 도중 I/O 작업으로 넘어가면 wait이 발생하게 됨.
- CPU만 연속적으로 사용하는 CPU burst 상태와 I/O만 연속되어 발생하는 I/O Burst 상태가 반복되게 됨.
- 주로 사람이 연결되어 있는 프로그램에서 주로 반복되는 형태가 많이 발생함 (interactive한 job)
- 프로그램의 종류에 따라 빈도나 유형이 각각 다름.
CPU-burst time의 분포
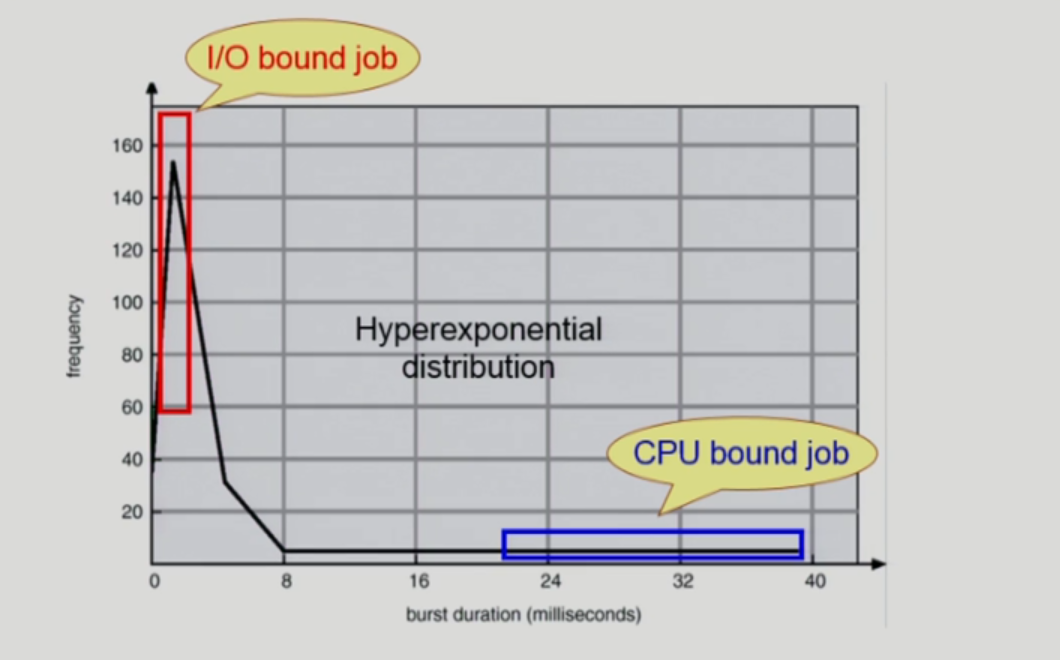
- 여러 종류의 job(=process)이 섞여 있기 때문에 CPU 스케쥴링이 필요
- interactive job에게 적절한 response 제공 필요
- CPU와 I/O 장치 등 시스템 자원을 골고루, 효율적으로 사용 -> CPU Scheduling이 필요한 이유
- 중간에 I/O가 많으면 CPU bust time이 적음. (= I/O bound job) -> 반대가 CPU bound job
-
CPU를 많이 사용하는 것은 CPU bound job이라고 보는게 맞고, I/O bound job은 I/O가 빈번하기 때문에 스위칭이 잦아 CPU 사용률이 많아 보이는 것. (frequency가 높은 이유)
- I/O bound job에 CPU 먼저 줘야하는 이유
- 먼저 I/O해서 뒤 작업 하려고
- 사람 측면에서 I/O 했는데 반응 느리면 답답하기 때문에
CPU Scheduler & Dispatcher
- CPU Scheduler Ready 상태의 프로세스 중에서 이번에 CPU를 줄 프로세스를 고른다. OS의 특정적인 기능 (code)를 Scheduler라고 부르는 것.
-
Dispatcher CPU의 제어권을 CPU Scheduler에 의해 선택된 프로세스에게 넘긴다. 이 과정을 context switch(문맥 교환)라고 한다.
- CPU 얻는 과정
- 얻는과정
- ready -> running
- 빼았는과정
- running -> ready
- running -> blocked
- 얻는과정
- CPU 스케쥴링이 필요한 경우
프로세스에게 다음과 같은 상태 변화가 있는 경우 스케쥴링이 필요하다.
- Running -> Blocked (예 : I/O 를 요청하는 System call) - I/O같이 오래 걸리는 작업 하게되면 다른것에 CPU를 줌
- Running -> Ready (예 : 할당시간만료로 timer interrupt) - 특정 작업만 오래 CPU 쓰게 할 수 없으므로 강제로 뺐음
- Blocked -> Ready (예 : I/O 완료 후 인터럽트) - CPU얻을 수 있는 권한 부여 - 강제로 줌
- Terminate
✔ 1,4에서의 스케쥴링은 nonpreemptive (강제 x, 자진 반납)
✔ 1,4번을 제외한 스케쥴링은 preemptive (강제로 문맥교환 발생)
Scheduling Criteria - Performance Index(스케쥴링 성능 척도)
- CPU Utilization (이용률) ; Keep the CPU as busy as possible
- CPU가 놀지 않고 일한 시간의 비율
- Throughput (처리량) ; # of processes that complete their execution per time unit
- 주어진 시간 동안 몇개의 작업을 처리했는지에 대한 비율
- Turnaround Time (소요 시간, 평균 시간) ; amount of time to execute a particular process
- CPU를 쓰기 시작해서 I/O 처리를 위해 종료할 때까지 (뺏길 때까지) 걸린 시간 (CPU burst time)
- Waiting Time (대기 시간) ; amount of time a process has been waiting in the ready queue
- CPU를 쓰기까지의 순서를 기다리는 시간
- waiting time은 여러 차례 발생하는 대기 시간을 합친 시간을 의미함 (response time과 조금 다름)
- Response time (응답 시간) ; amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)
- 처음으로 CPU를 점유하기까지 걸린 시간
Scheduling Algorithm (p.226 참조)
FCFS (First-Come First-Served)
- 먼저 온 순서대로 작업을 처리하는 것.
- 비선점형 스케쥴링 (non-preemptive)
- 그닥 효율적이진 않음. (짧게 쓰는 작업들이 대기중이더라도 만약 긴 작업이 실행중이라면 계속 그 작업이 끝날때까지 대기해야 하기 때문에)
- 앞에 어떤 유형의 프로세스가 존재하느냐에 따라 효율이 굉장히 달라짐
- Convoy effect : short process behind long process ( 짧은 프로세스가 긴 프로세스로 인해 오래 기다리는 것 )
SJF (Shortest-Job First)
- _CPU burst time_이 제일 짧은 프로세스에게 제일 먼저 CPU를 점유하게 해주는 것. ( Choose the job with the smallest expected CPU burst )
- Non-preemptive
- average waiting time이 제일 적은 스케쥴링 기법
- 일단 한번 CPU를 점유하면 더 짧은 프로세스가 도착하더라도 이미 진행중인 프로세스의 CPU burst time이 끝날때까지 대기
- Preemptive (Shortest-Remaining-Time-First : SRTF)
- 현재 수행중인 프로세스의 남은 burst time보다 더 짧은 CPU burst time을 가지는 새로운 프로세스가 도착하면 CPU를 빼앗김
- SJF is optimal
- 주어진 프로세스들에 대해** minimum average waiting time**을 보장
다음 CPU Burst Time 예측
- 다음 CPU burst time은 추정만 가능
- 과거의 CPU burst time을 이용해서 추정(exponential averaging)


Priority Scheduling (우선순위 스케쥴링)
- A priority number(integer) is associated with each process
- highest priority를 가진 프로세스에게 CPU 할당 (smallest integer = highest priority)
- Preemptive
- nonpreemptive
- SJF는 일종의 priority scheduling
- priority = predicted next CPU burst time
- Problem
- Starvation : low priority processes may never execute
- Solution
- Aging : as time progresses increase the priority of the process
Round Robin (RR)
- 현대적인 스케쥴링 기법은 거의 Round Robin을 사용함
- 각 프로세스는 동일한 크기의 할당 시간 (time quantum)을 가짐. ( 일반적으로 10-100 milliseconds )
- 할당 시간이 지나면 프로세스는 선점당하고, ready queue의 제일 뒤에 가서 다시 줄을 선다. 응답 시간이 제일 빠른 스케쥴링 기법
- n개의 프로세스가 ready queue에 있고, 할당 시간이 q_time unit인 경우 각 프로세스는 최대 q_time unit 단위로 CPU 시간의 1/n을 얻는다. => 어떤 프로세스도 (n-1)q time unit 이상을 기다리지 않음
- Performance
- q large (할당 시간이 큰 경우) => FCFS(FIFO)
- q small (할당 시간이 작은 경우) => context switch 오버헤드가 커지기 때문에 부하 발생 가능성 커짐.
Multilevel Queue (p.235 참조)
- Ready Queue를 여러 개로 분할
- foreground (interactive)
- background (batch - no human interaction)
- 각 큐는 독립적인 스케쥴링 알고리즘을 가짐
- foreground (RR)
- background (FCFS)
- 큐에 대한 스케쥴링이 필요
- fixed priority scheduling
- serve all from foreground then from background
- possibility of starvation : 우선순위가 낮은 프로세스에서는 기아 현상이 발생할 수 있음 ex) batch processes, student processes
- time slice
- starvation을 방지하기 위한 방법으로 사용
- 각 큐에 CPU time을 적절한 비율로 할당 ex) 80%는 foreground에 20%는 background에
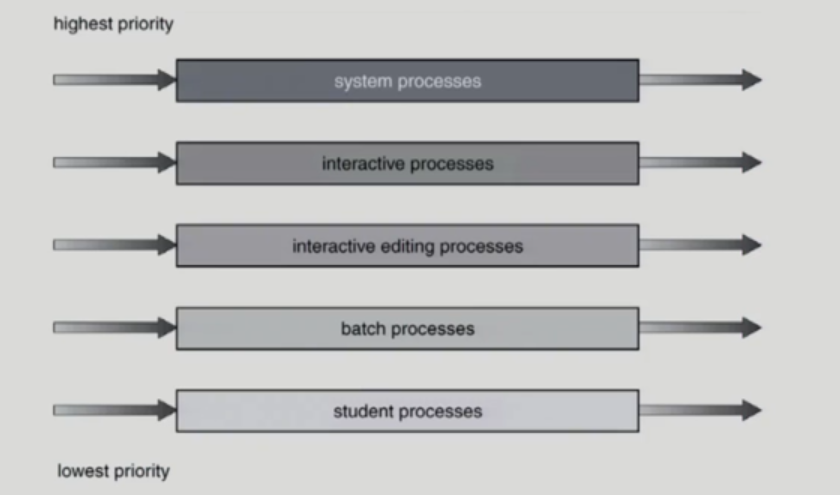
- fixed priority scheduling
Multilevel Feedback Queue
- 처음 들어오는 프로세스는 가장 높은 우선순위를 가지는 queue에 보냄. (quantum이 가장 짧음)
- 가장 높은 우선순위 queue에서 작업이 끝나지 않았을 경우 그 다음 우선순위를 가지는 queue로 할당됨 ===> 프로세스가 다른 큐로 이동 가능. Aging을 위와 같은 방식으로 구현하는 원리
- CPU burst time이 짧은 프로세스에게 우선순위가 높게 적용되는 알고리즘
- CPU burst time 예측이 필요 없다는 장점 보유
- Multilevel-feedback-queue schedular를 정의하는 파라미터들
- Queue의 수
- 각 큐의 scheduling algorithm
- Process를 상위 큐로 보내는 기준
- Process를 하위 큐로 내쫒는 기준
- Process가 CPU Service를 받으려 할 때 들어갈 큐를 결정하는 기준
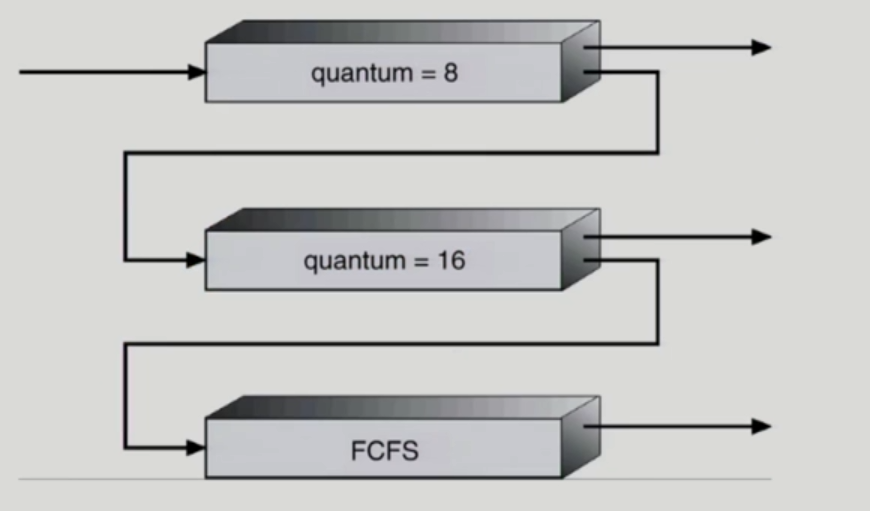
Multiple-Processor Scheduling
- CPU가 여러 개인 경우 스케쥴링은 더욱 복잡해진다.
- Homogeneous processor인 경우
- Queue에 한줄로 세워서 각 프로세스가 알아서 꺼내가게 할 수 있다.
- 반드시 특정 프로세서에서 수행되어야 하는 프로세스가 있는 경우에는 문제가 더 복잡해진다. ( 보통 우선순위를 부여해 특정 프로세서에 수행되도록 처리함. )
- Load Sharing
- 일부 프로세서에 job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘 필요
- 별개의 큐를 두는 방법 vs 공동 큐를 사용하는 방법
- Symmetric Multiprocessing (SMP)
- 각 프로세서가 각자 알아서 스케줄링 결정
- Asymmetric Multiprocessing
- 하나의 프로세서가 시스템 데이터의 접근과 공유를 책임지고 나머지 프로세서는 거기에 따름.
Real-Time Scheduling
- 정해진 시간 (deadline)안에 반드시 수행되어야 하는 프로세스 스케쥴링
- 주로 미리 스케쥴링을 해서 적재적소에 배치되도록 함.
- Hard Real-time systems
- 정해진 시간 안에 반드시 끝내도록 스케쥴링 해야 함.
- Soft Real-time computing
- 일반 프로세스에 비해 높은 priority를 갖도록 해야 함.
Thread Scheduling
- Local Scheduling
- User level thread의 경우 사용자 수준의 thread library에 의해 어떤 thread를 스케쥴링할지 결정
- Global Scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케쥴러가 어떤 thread를 스케쥴링할지 결정
Real Time Scheduling
- 정해진 시간(Deadline)안에 반드시 수행되어야 하는 프로세스 스케줄링
- 주로 미리 스케줄링을 해서 적재적소에 배치되도록 함
- Hard Reat-time systems
- 정해진 시간 안에 반드시 끝내도록 스케줄링 해야함
- Soft Real-time computing
- 일반 프로세스에 비해 높은 priority를 갖도록 해야 함.
Thread Scheduling
- Local Scheduling
- User level thread의 경우 사용자 수준의 thread library에 의해 어떤 thread를 스케쥴링할지 결정
- Global Scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케쥴러가 어떤 thread를 스케쥴링할지 결정
Scheduling Algorithm Evaluation
- Queueing models
- 굉장히 이론적인 평가 방법
- 확률 분포로 주어지는 arrival rate와 service rate 등을 통해 각종 performance index 값을 계산
- Implementation(구현) & Measurement(성능 측정)
- 실제 시스템에 알고리즘을 구현하여 실제 작업(workload)에 대해서 성능을 측정 및 비교
- 사용하기 어려운 방법 (직접 OS kernel을 수정해야 함.)
- Simulation (모의 실험)
- 알고리즘을 모의 프로그램으로 작성 후 trace를 입력으로 하여 결과 비교
This post is licensed under
CC BY 4.0
by the author.