Operating System Concepts - (9)

Operating System Concepts - (9)

Virtual Memory (1)
가상 메모리는 운영체제가 관리한다.
Demand Paging (요구 페이징)
- 실제로 필요할 때 page를 메모리에 올리는 것. (요청이 있으면 페이지를 메모리에 올리겠다는 의미)
- 실제로 대부분의 시스템들은 Paging 기법 사용 중
- 요구 페이징의 장점
- I/O양의 감소 (프로그램 중에 빈번하게 사용되는 부분은 지극히 제한적이고, 좋은 소프트웨어일수록 프로그램 사용에 있어 굉장히 방어적으로 코드를 작성하기 때문에 잘 사용되지 않는다.)
- 물리 Memory 사용량 감소
- I/O 요청이 있을때만 메모리에 올리기 때문에 한정된 메모리 공간을 효율적으로 사용하고, 메모리에서 직접 서비스하는 비율이 높아지기 때문에 응답 시간이 빨라진다.
- 멀티프로그래밍 환경에서는 더 많은 사용자 수용 가능. (프로그램 여러개가 동시에 메모리에 올라가는 환경에서는 더 많은 사용자가 동시에 메모리에 올라갈 수 있기 때문에 효과적)
- Vaild / Invaild bit의 사용 (페이지 테이블의 엔트리마다 존재)
- Invaild의 의미
- 사용되지 않는 주소 영역인 경우
- 페이지가 물리적 메모리에 없는 경우
- 처음에는 모든 page entry가 invaild로 초기화
- address translation시에 invalid bit이 set 되어 있으면 ==> page Fault 발생!
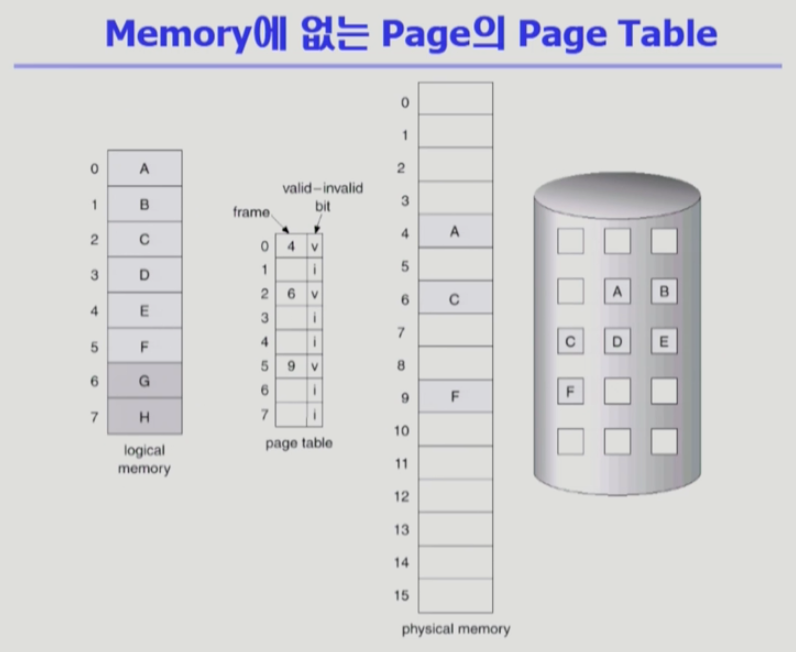
- Invaild의 의미
Page Fault
- 운영체제의 Page Fault 처리루틴.
- invalid page를 접근하면 MMU가 trap을 발생시키게 된다. (page fault trap)
- CPU가 자동적으로 OS에게 넘어감. kernel mode로 들어가 OS에 page fault를 처리하는 코드인 page fault handler가 실행된다.
-
다음과 같은 순서로 page fault를 처리함
- 잘못된 요청이 아닌지? address가 잘못되있거나(프로세스가 사용하지 않는 주소인지), 접근권한을 잘못 사용했다던가 하면 => process를 abort시킴.
- 정상적인 요청이라면 디스크에서 페이지를 메모리로 올려준다.
- 만약 비어있는 메모리가 없다면(페이지 프레임이 없다면), 하나를 쫓아내야 한다.(replace)
- 빈 페이지 프레임을 획득하면 해당 페이지를 디스크에서 메모리로 읽어온다. (이 작업은 매우 느린 작업.) (1) disk I/O 작업이 끝날때까지, 이 프로세스는 CPU를 뺏기고(CPU 낭비이기 때문에) block 상태가 됨. (preempt) (페이지 폴트가 난 프로세스는 CPU를 뺏기고 당장 CPU를 사용할 수 있는 ready 상태의 프로세스 에게 CPU를 넘겨준다. 넘겨주기 전에 디스크 컨트롤러에게 그 페이지를 읽어오라고 부탁한다.) (2) Disk Read가 끝나면 page tables entry기록, valid/invalid bit = “valid” (그리고 디스크 I/O가 끝나면, 인터럽트가 걸려서 OS가 CPU를 가지고 페이지 폴트 처리가 끝났으므로 테이블에 valid로 표시하고 해당 페이지 프레임 번호를 적어둠.) (3) ready queue에 process를 insert -> dispatch later (페이지 폴트났던 프로세스가 CPU를 다시 잡고 정상적으로 MMU에의해 주소변환이 되고 running 상태가 됨.)
- instruction 수행 재개.
Steps in Handling a Page Fault
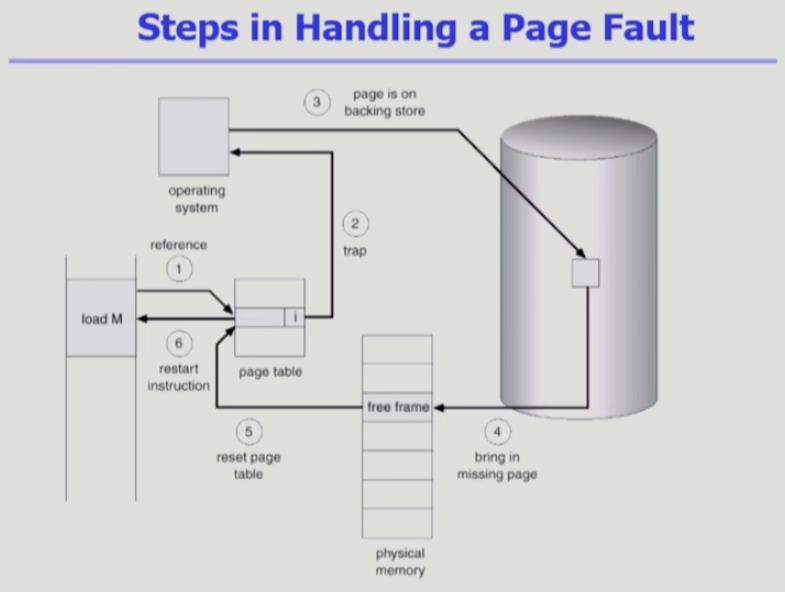
- 주소변환을 하려고 봤더니 invalid로 표시되어 있음.
- 페이지가 메모리위에 올라와있지 않다는 말이고 trap에 걸려서 CPU가 OS에게 자동으로 넘어간다.
- OS는 백킹스토어에 있는 페이지를 물리메모리로 올린다.
- 빈 페이지 프레임이 없으면 뭔가를 쫓아내고 올린다.
- 올렸으면, 해당 프레임번호를 엔트리에 적어두고, invalid -> valid로 수정한다.
- 나중에 CPU를 다시 얻어서, 정상적으로 주소 변환을 하면 물리 메모리에 정상 접근이 가능해진다.
Performance of Demand Paging (요구 페이징 성능)

- 페이지 폴트가 발생했을 때 디스크 접근하는 것은 매우 오래 걸리는 작업이기 때문에 페이지 폴트가 얼마나 발생하는가에 따라서 메모리 접근하는 시간이 크게 좌우됨.
- 페이지 폴트의 비율(Page Fault Rate) : (0 <= p <= 1.0)
- if p=0 : 페이지폴트 발생 X. 메모리 위에 항상 페이지가 있음
- if p=1 : 메모리 참조할때마다 항상 페이지폴트가 발생함.
- 실제로는 거의 페이지폴트가 발생하지 않음. (0.0xx)
- Effective Access Time
- = (1-p) * memory access + p ( OS & HW page fault overhead + 공간 없을때 내쫓기[swap page out if needed] + swap page in + (나중에 CPU얻으면 restart) OS & HW restart overhead )
- 그러므로 페이지가 부재하면 오버헤드가 발생함.
Free page frame이 없는 경우
-
Page replacement
- 어떤 frame을 빼앗아올지 결정
- 곧바로 사용되지 않을 page를 쫒아내는 것이 좋음
- 동일한 페이지가 여러 번 메모리에서 쫒겨났다가 다시 들어올 수 있음.
- OS가 담당하는 업무
-
Replacement algorithm
- 가능하면 Page-fault rate를 최소화하는 것이 목표
- 알고리즘의 평가
- 주어진 page reference string에 대해 page fault를 얼마나 내는지 조사
- (p(페이지 폴트 발생비율)을 가급적 0으로 만드는게 이 알고리즘의 목표)
- reference string의 예시 1,2,3,4,1,2,5,1,2,3,4,5 (시간순서에 따라 페이지 참조 순서를 나열한 것)
Page Replacement
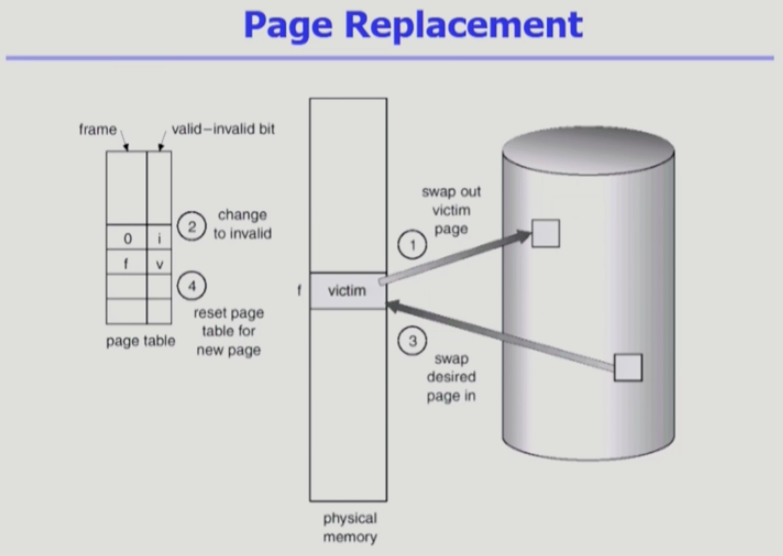
- Page Replacement 라는 것은 어떤것을 쫓아낼 지 결정하고, 그 쫓아낼 victim 이 결정되면 Disk로 쫓아내는 것이다.
- 어떤걸 쫓아낼 지 결정하고, 만약 쫓아낼 때, victim이 Disk에서 메모리에 올라온 이후에 변경(Write)된 내용이 있다면 변경된 내용을 백킹스토어에 써줘야 한다. 그 상황이 아니라면 그냥 physical memory에서 지워주기만 하면 된다.
- 쫓아내고 빈 자리에 새로운 page를 올려준다. 쫓겨난 페이지에 대한 테이블 valid-invalid bit를
invalid로 변경하고, 메모리에 올라온 페이지에 대한 페이지 엔트리에는 페이지 테이블에frame number를 적고,valid로 바꿔준다. - 이런 역할을 OS가 맡아 진행하는 것
Replacement Algorithm(교체 알고리즘)
1. 최적 알고리즘 (Optimal Algorithm)
- 페이지 폴트를 가장 적게하는 알고리즘. 하지만, 미래의 일을 예측할 수 없기 때문에 이론적인 알고리즘임.
- Offline Optimal Algorithm 이라고도 부름. (실제 시스템에서 온라인으로 사용하는게 아니기 때문에)
- 제일 먼 미래에 사용될 page를 쫓아내는 방식.
- 다른 알고리즘의 성능에 대한 upper bound를 제공. 아무리 좋은 알고리즘을 만들어도 이 최적 알고리즘보다 더 좋은 알고리즘은 만들 수 없기 때문에 참고용으로만 사용 가능함.
- 빨간색으로 적은 부분이 페이지 폴트가 발생하는 부분. 연보라색은 페이지 폴트가 나지 않고 메모리에서 직접 참조되는 경우.
2. FIFO (Fist In First Out) Algorithm
- 여기서부터 실사용 가능한 알고리즘 (미래를 모르는 상황에서 사용하는 알고리즘. 미래 예측.)
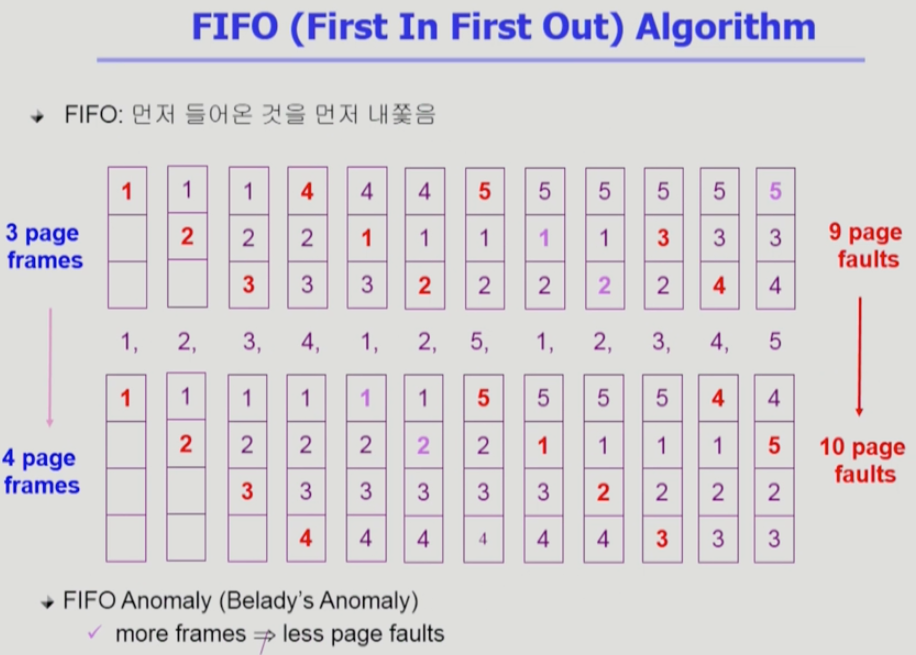
- 먼저 들어온 것을 먼저 내쫓음
- FIFO Anomaly(Belady’s Anomaly) : 메모리 크기(page frame 갯수)를 늘려줘도 성능이 더 나빠지는 특이한 상황이 발생할 수 있음.
3. LRU (Least Recently Used) Algorithm
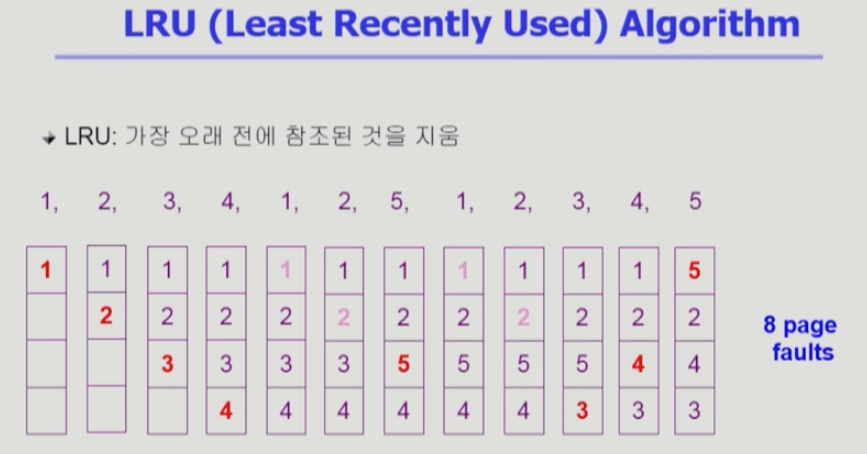
- 실제로 가장 많이 사용하고 있는 알고리즘
- 가장 오래 전에 참조된 것을 지우고 최근에 쓰인 것은 남기는 것. 최근에 쓰인 페이지가 또 쓰일 것이라고 가정하는 알고리즘.
4. LFU (Least Frequently Used) Algorithm
- 참조 횟수 (reference count)가 가장 적은 페이지를 지우는 것.
- 최저 참조 횟수인 page가 여럿 있는 경우
- LFU 알고리즘 자체에서는 여러 page 중 임의로 선정한다.
- 성능 향상을 위해 가장 오래 전에 참조된 page를 지우게 구현할 수도 있다.
- 최저 참조 횟수인 page가 여럿 있는 경우
- 장점
- LRU처럼 직전 참조 시점만 보는 것이 아니라 장기적인 시간규모를 보기 때문에 page의 인기도를 좀 더 정확하게 반영할 수 있음.
- 단점
- 참조시점의 최근성을 반영하지 못함. LRU보다 구현이 복잡함.
5. LRU vs LFU 예제

- 페이지 프레임은 4개 존재. 1,2,3,4중에 하나를 쫓아내야 함.
- LRU : 1번을 쫓아냄 / LFU : 4번을 쫓아냄.
- 제일 참조횟수가 많은 1번을 쫒아내는 LRU, 제일 최근에 참조된 페이지를 쫒아낸 LFU -> 누가 더 비효율적인지 측정 힘듬.
6. LRU, LFU 알고리즘의 구현
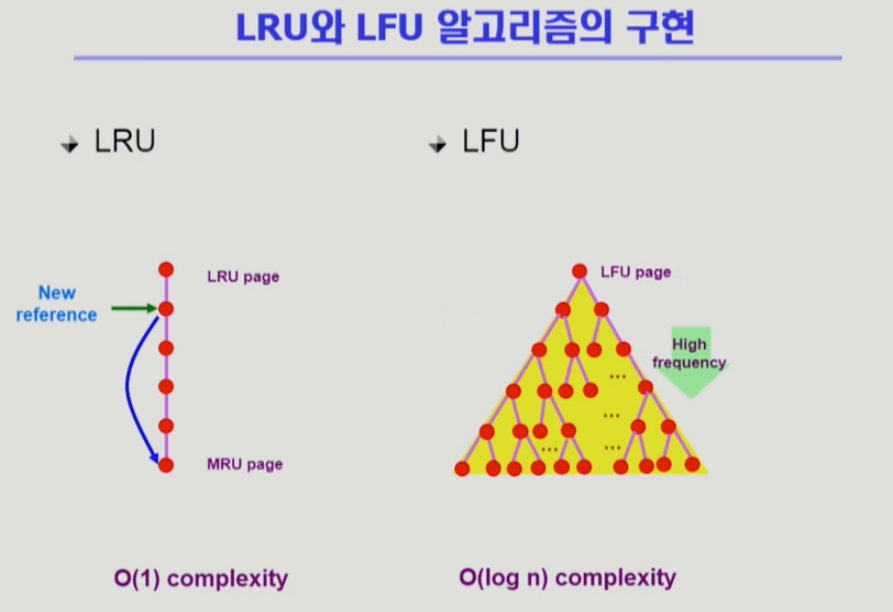
**1. LRU **
- LRU는 메모리에 있는 페이지들을 참조 순서에 따라 한줄로 줄세우기를 한다. 맨 위에 페이지는 가장 오래전에 참조된 페이지.
- LRU : Linkedlist 형태로 맨 아래로 갈수록 가장 최근에 참조한 페이지.
- 쫓아낼 때 비교가 필요없다. 제일 위에 있는 페이지를 내쫓으면 됨.
- 시간복잡도 : O(1)
2. LFU
- LFU : 밑으로 갈수록 참조 횟수가 많은 페이지.
- 하지만 이 알고리즘은 한 줄로 줄세우기가 불가능함. 카운팅 될 때마다 비교를 해서 어디까지 내려올 수 있는지 비교하고 자리 바꿈을 해야 하기 때문.
- 시간복잡도 : O(n)
- 힙을 사용(Complete binary tree)하게 되면 시간복잡도 : O(log n)
- 경로를 따라가면서 자식 2개와만 비교하기 때문에 log n 의 시간복잡도가 발생하게 됨. (이진트리의 장점)
This post is licensed under
CC BY 4.0
by the author.