Pytorch로 시작하는 딥러닝
Pytorch와 딥러닝 공부를 시작하며 기록하고자 한다.
머신 러닝 워크플로우(Machine Learning Workflow)
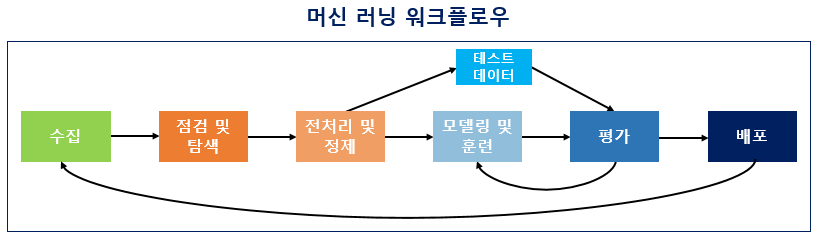
1. 데이터 수집 (Acquisition)
자연어 데이터인 코퍼스(corpus) 수집 다양한 출처(음성 데이터, 웹 크롤링, 리뷰 등)와 형식(txt, csv, xml 등)의 텍스트 데이터 확보
2. 데이터 탐색 (Exploration)
탐색적 데이터 분석(EDA) 수행 데이터 구조, 노이즈, 변수 특성 파악 시각화 및 기초 통계 분석
3. 데이터 전처리 (Preprocessing)
토큰화, 정제, 정규화, 불용어 제거 등 수행 다양한 라이브러리 활용
4. 모델링 및 훈련 (Modeling & Training)
적절한 머신러닝 알고리즘 선택 및 모델 구축
데이터를 훈련/검증/테스트 세트로 분리
훈련 데이터로 모델 학습
5. 평가 (Evaluation)
테스트 데이터로 모델 성능 평가 예측 결과와 실제 정답 비교
6. 배포 (Deployment)
완성된 모델 실제 환경에 배포 필요시 피드백 반영하여 프로세스 반복
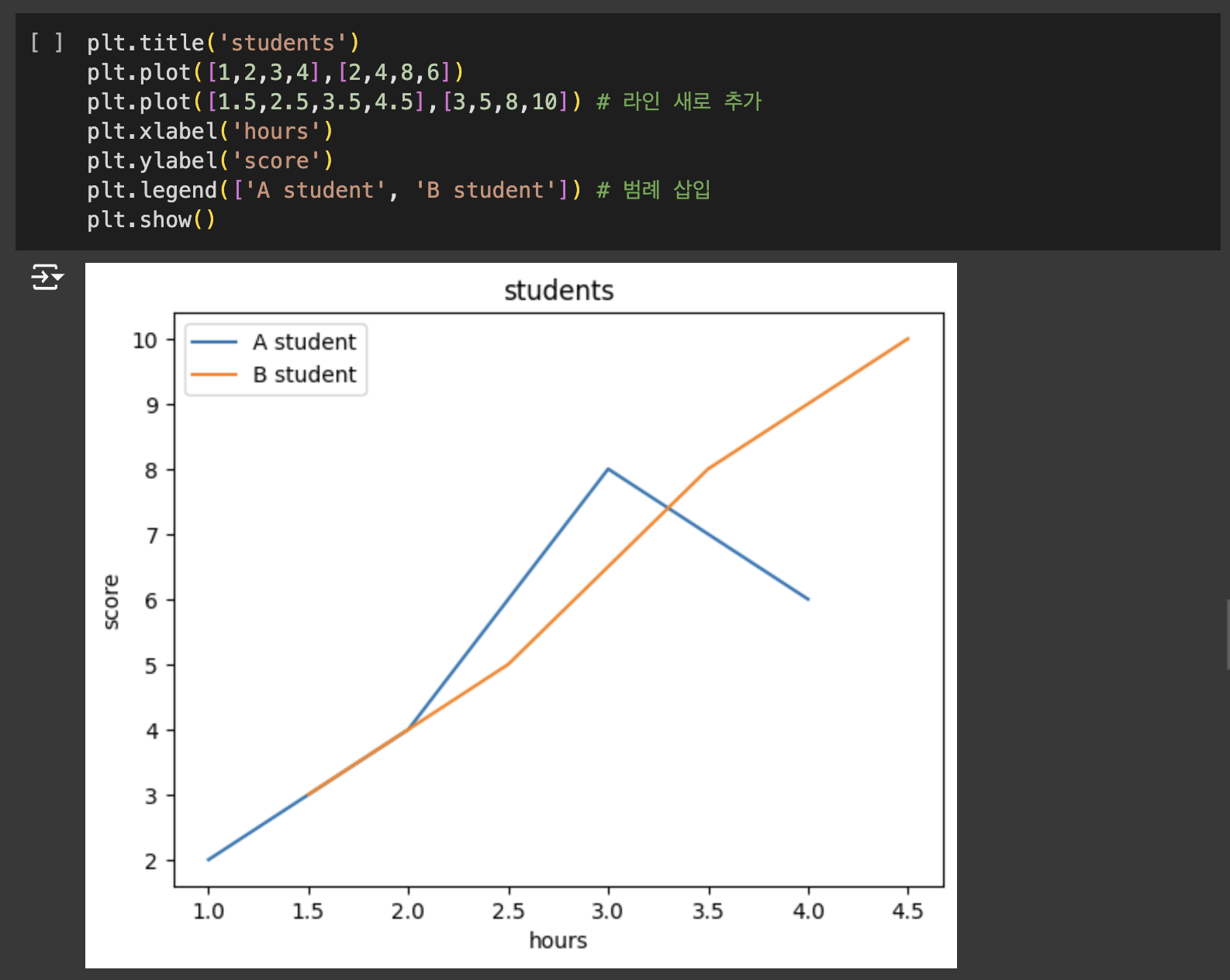
판다스(Pandas) and 넘파이(Numpy) and 맷플롭립(Matplotlib)
판다스(Pandas)
판다스(Pandas)는 파이썬 데이터 처리를 위한 라이브러리
 시리즈 클래스는 1차원 배열의 값(values)에 각 값에 대응되는 인덱스(index)를 부여할 수 있는 구조를 갖고 있습니다.
시리즈 클래스는 1차원 배열의 값(values)에 각 값에 대응되는 인덱스(index)를 부여할 수 있는 구조를 갖고 있습니다.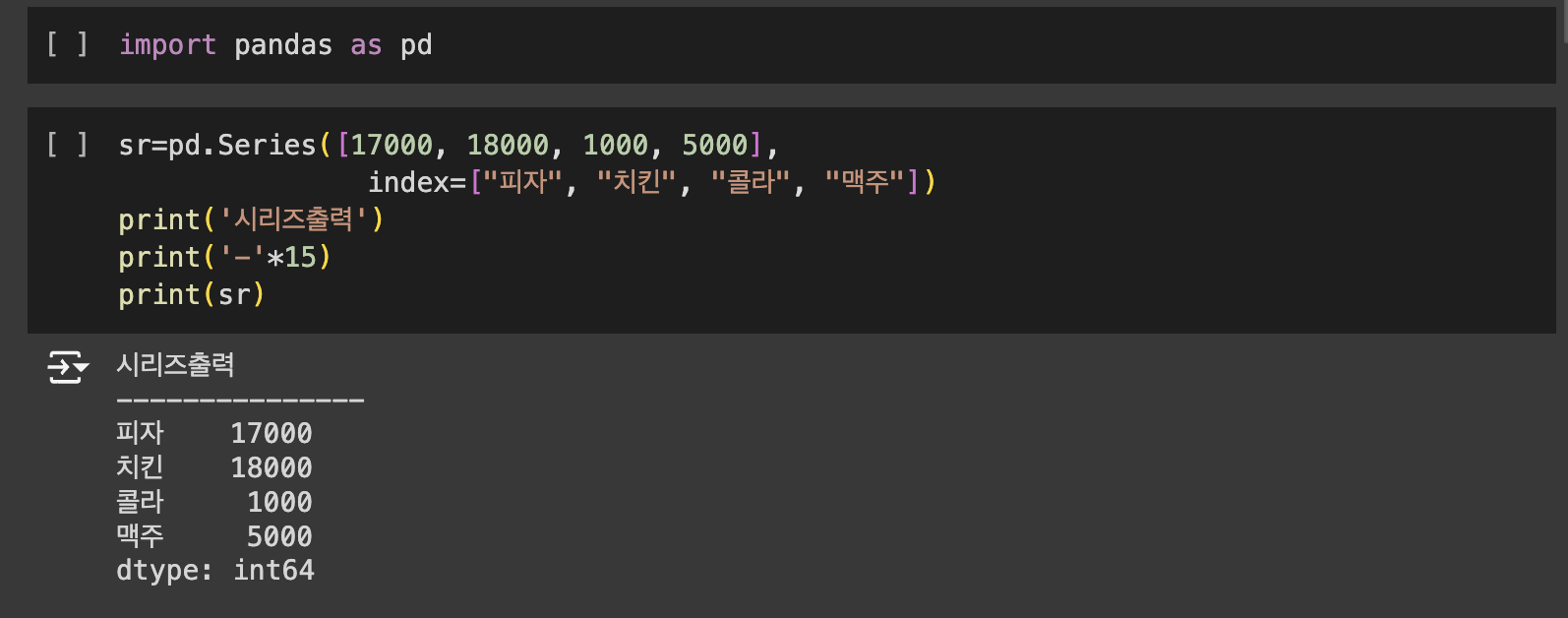 데이터프레임은 2차원 리스트를 매개변수로 전달합니다. 2차원이므로 행방향 인덱스(index)와 열방향 인덱스(column)가 존재합니다. 다시 말해 행과 열을 가지는 자료구조입니다.
데이터프레임은 2차원 리스트를 매개변수로 전달합니다. 2차원이므로 행방향 인덱스(index)와 열방향 인덱스(column)가 존재합니다. 다시 말해 행과 열을 가지는 자료구조입니다. 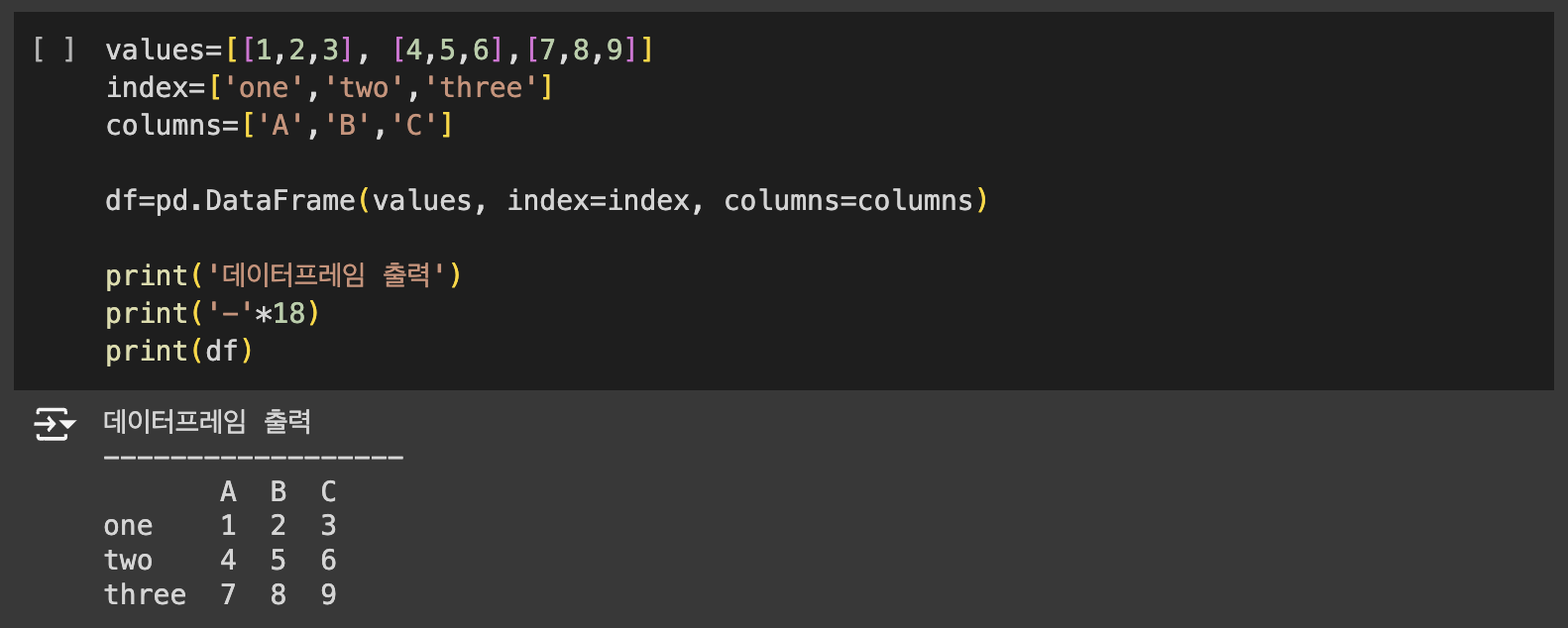
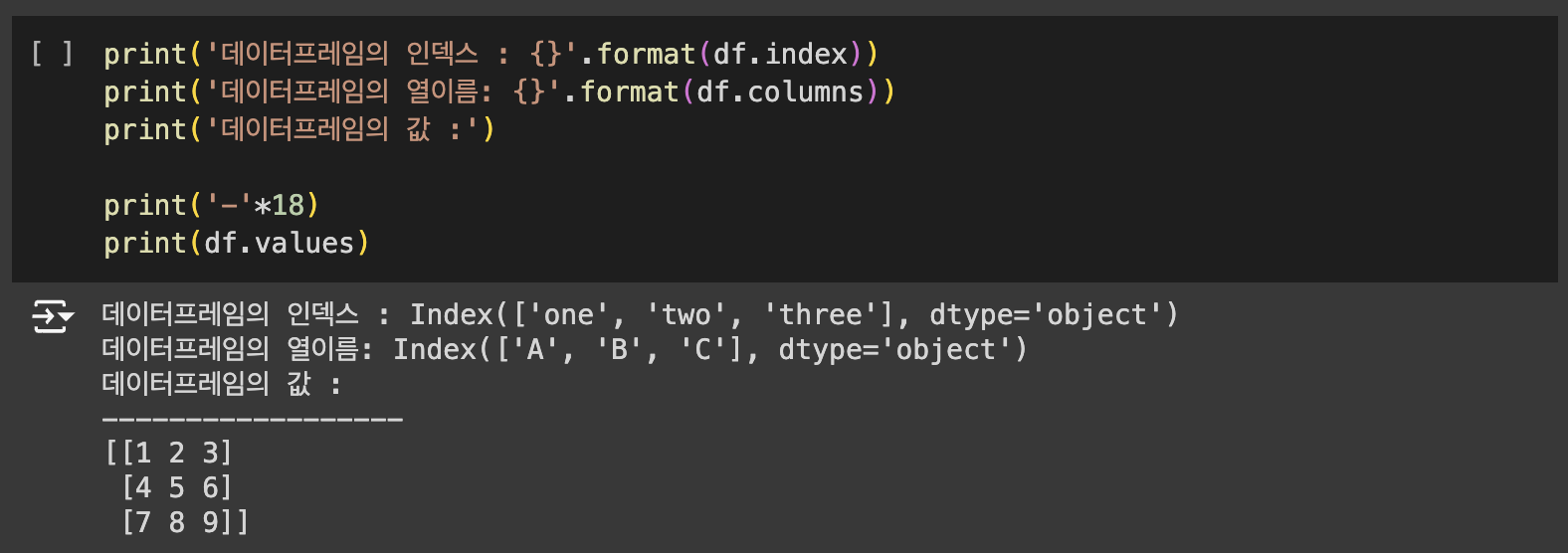 데이터프레임은 리스트(List), 시리즈(Series), 딕셔너리(dict), Numpy의 ndarrays, 또 다른 데이터프레임으로부터 생성할 수 있습니다.
데이터프레임은 리스트(List), 시리즈(Series), 딕셔너리(dict), Numpy의 ndarrays, 또 다른 데이터프레임으로부터 생성할 수 있습니다.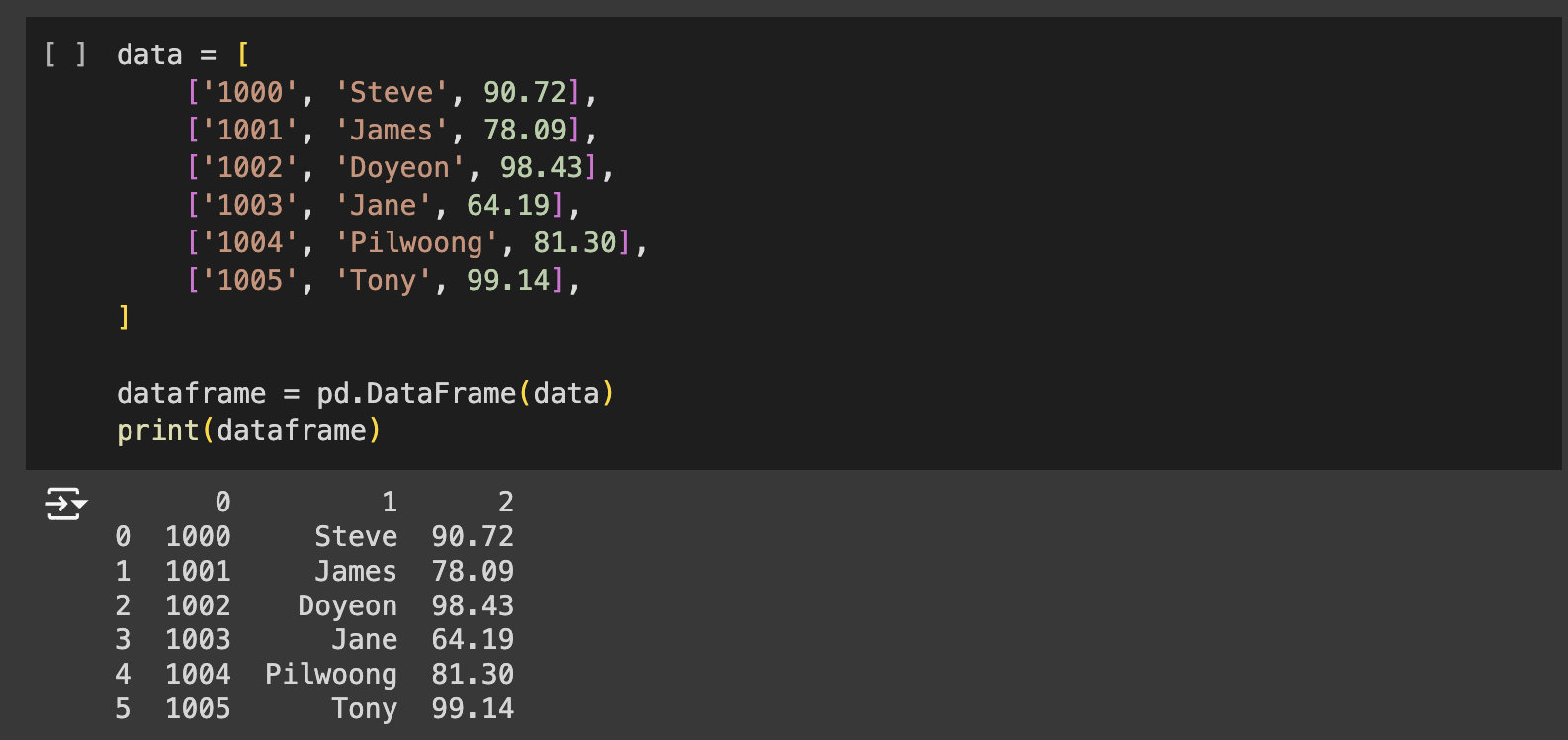
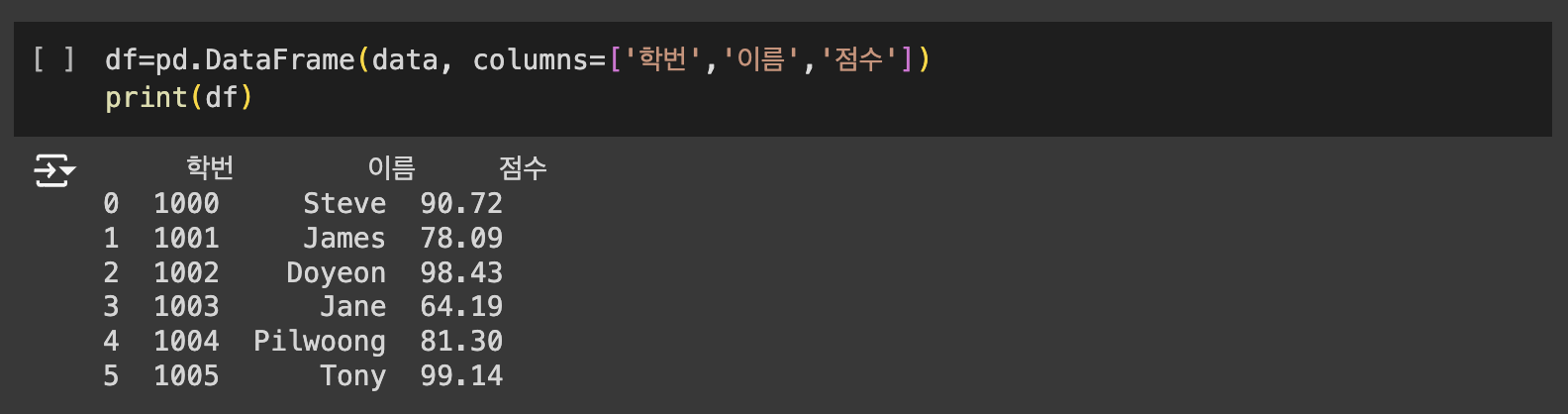
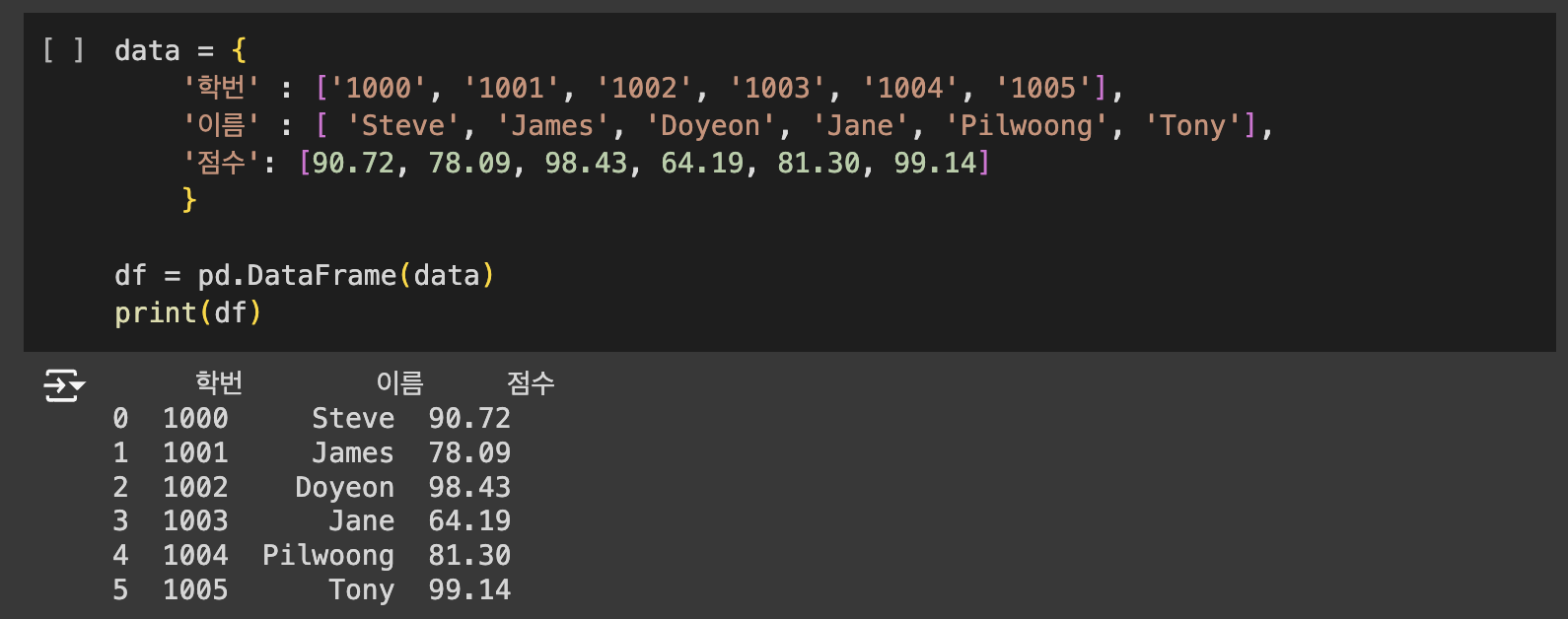 아래의 명령어는 데이터프레임에서 원하는 구간만 확인하기 위한 명령어로서 유용하게 사용됩니다.
아래의 명령어는 데이터프레임에서 원하는 구간만 확인하기 위한 명령어로서 유용하게 사용됩니다.
- df.head(n) - 앞 부분을 n개만 보기
- df.tail(n) - 뒷 부분을 n개만 보기
- df[‘열이름’] - 해당되는 열을 확인
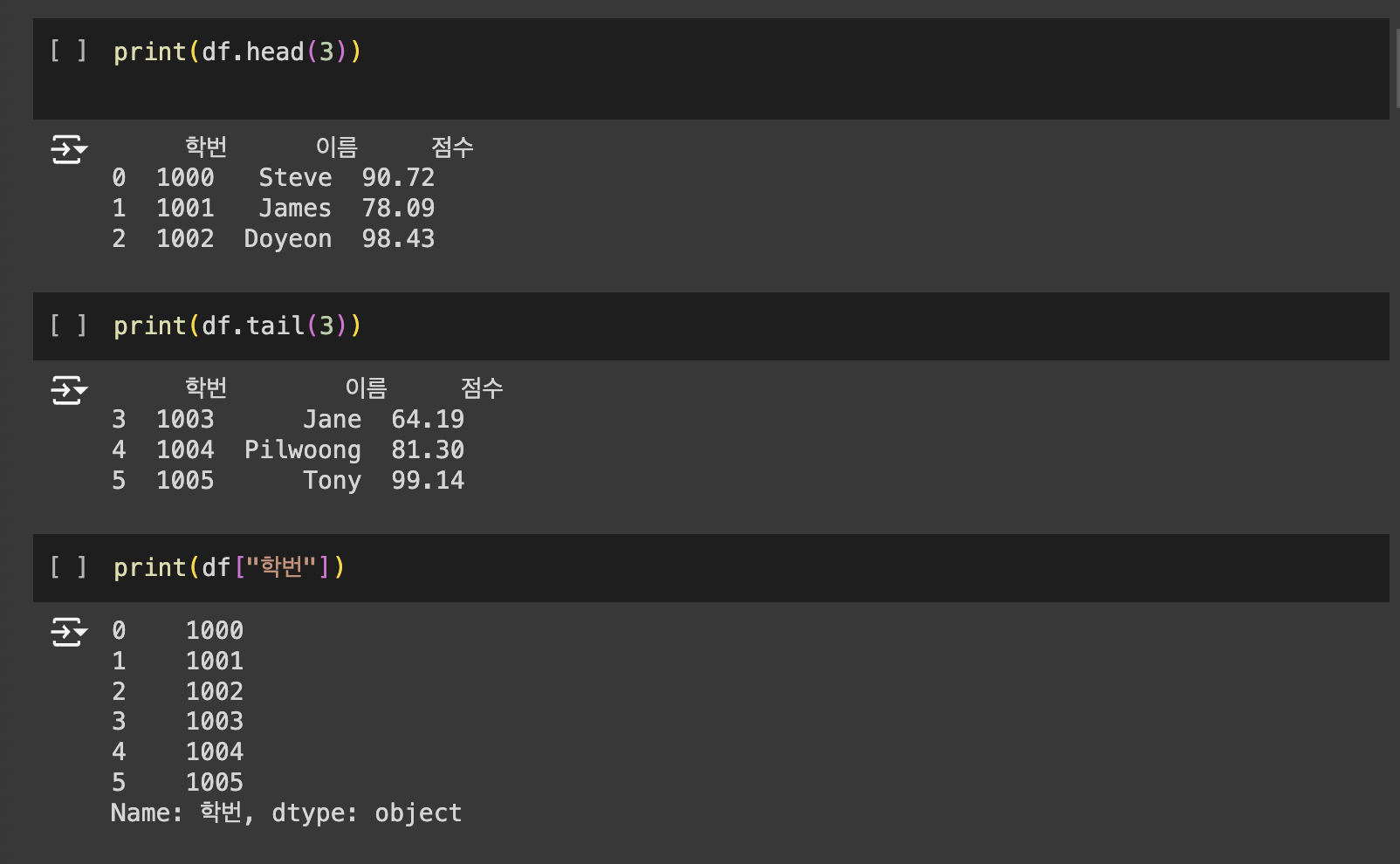
넘파이(Numpy)
넘파이(Numpy)는 수치 데이터를 다루는 파이썬 패키지입니다. Numpy의 핵심이라고 불리는 다차원 행렬 자료구조인 ndarray를 통해 벡터 및 행렬을 사용하는 선형 대수 계산에서 주로 사용됩니다. Numpy는 편의성뿐만 아니라, 속도면에서도 순수 파이썬에 비해 압도적으로 빠르다는 장점이 있습니다.
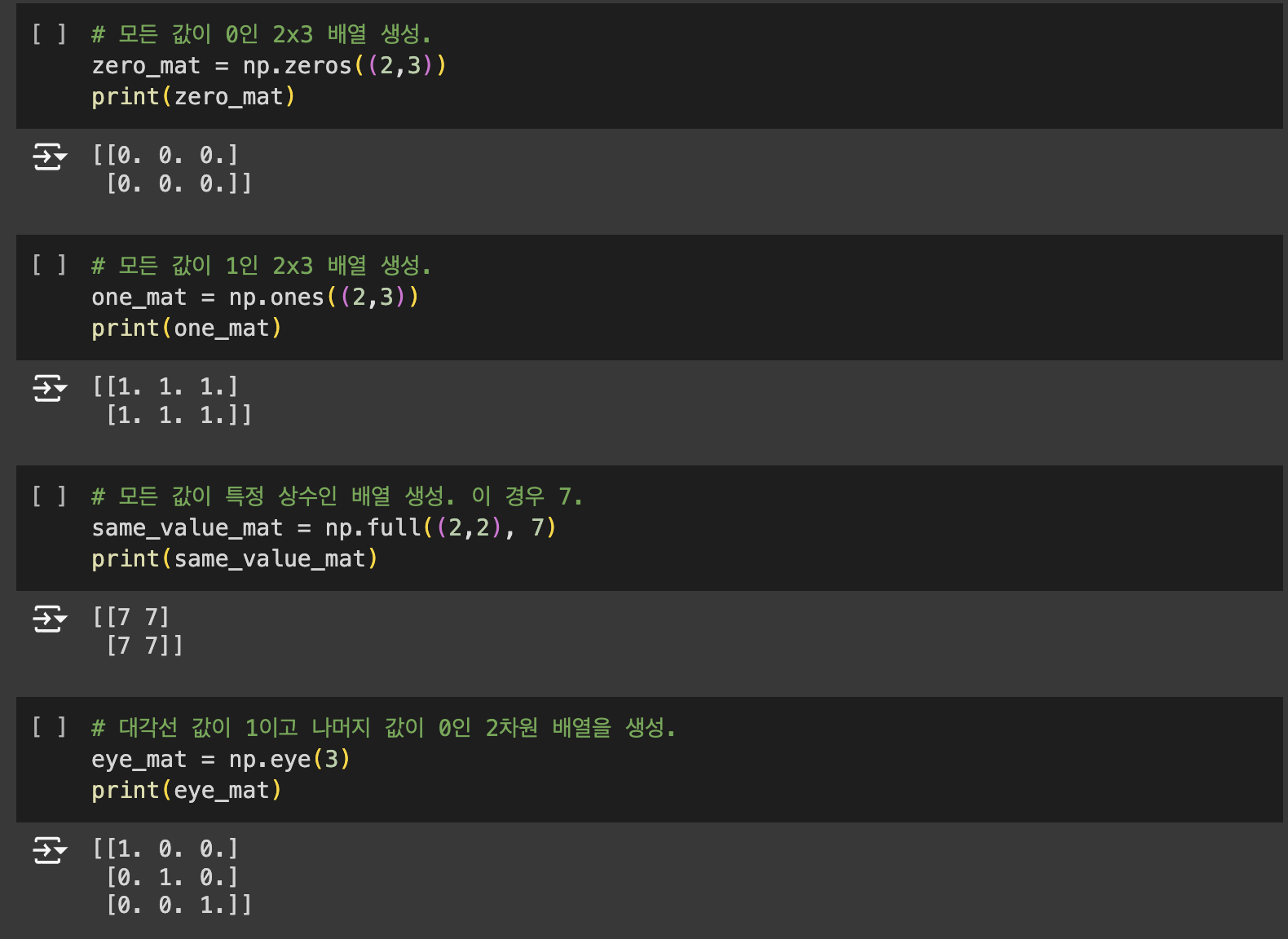
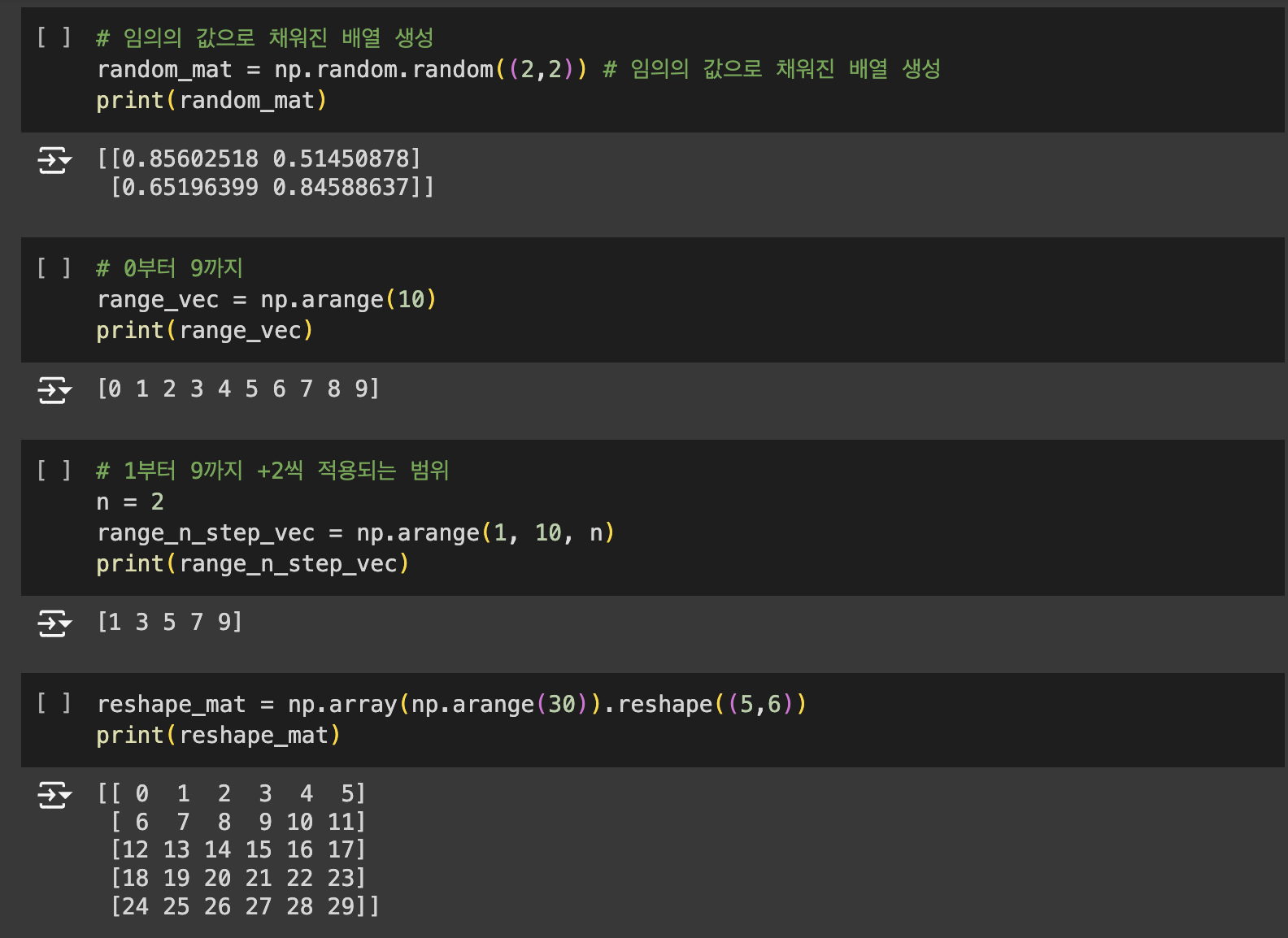
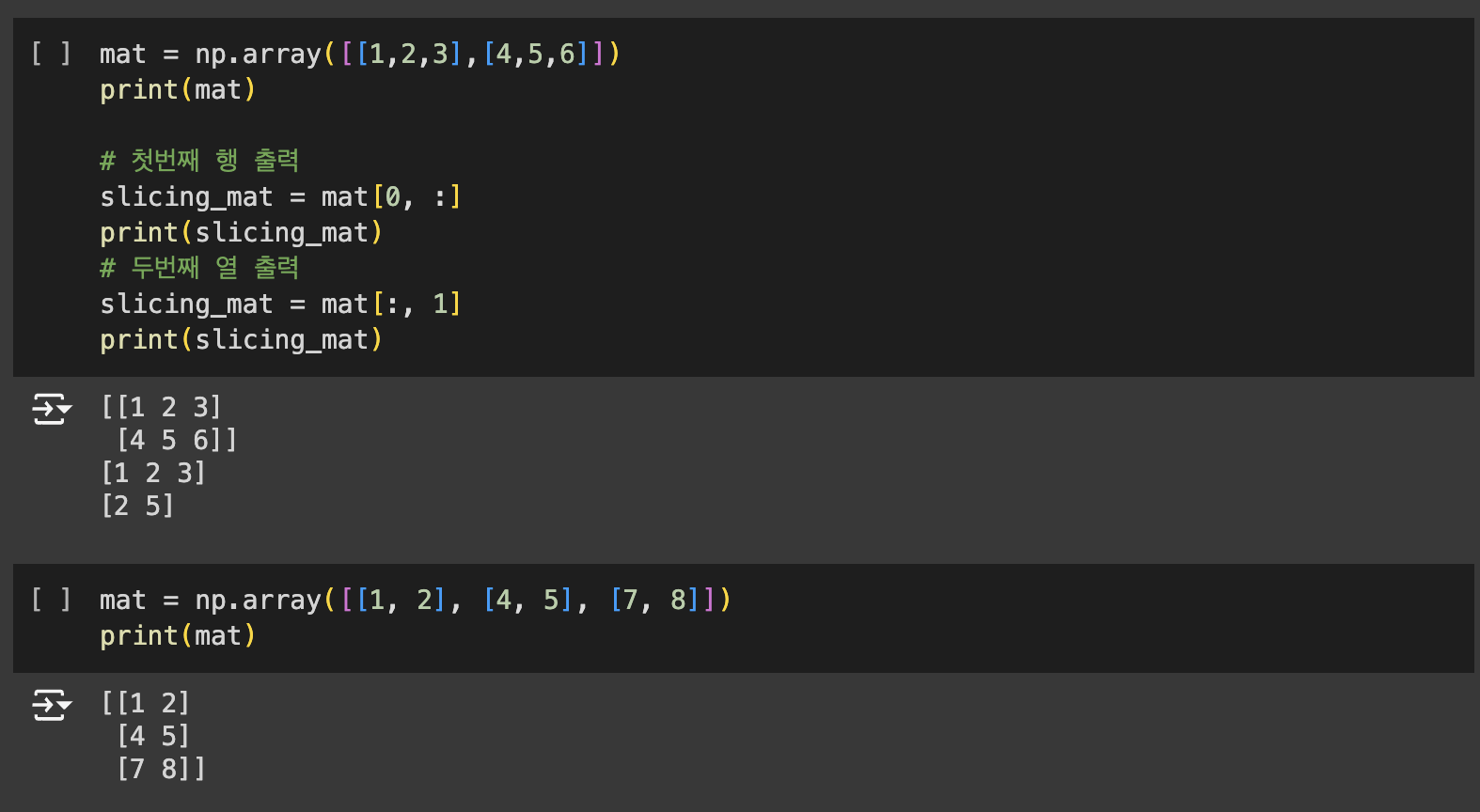
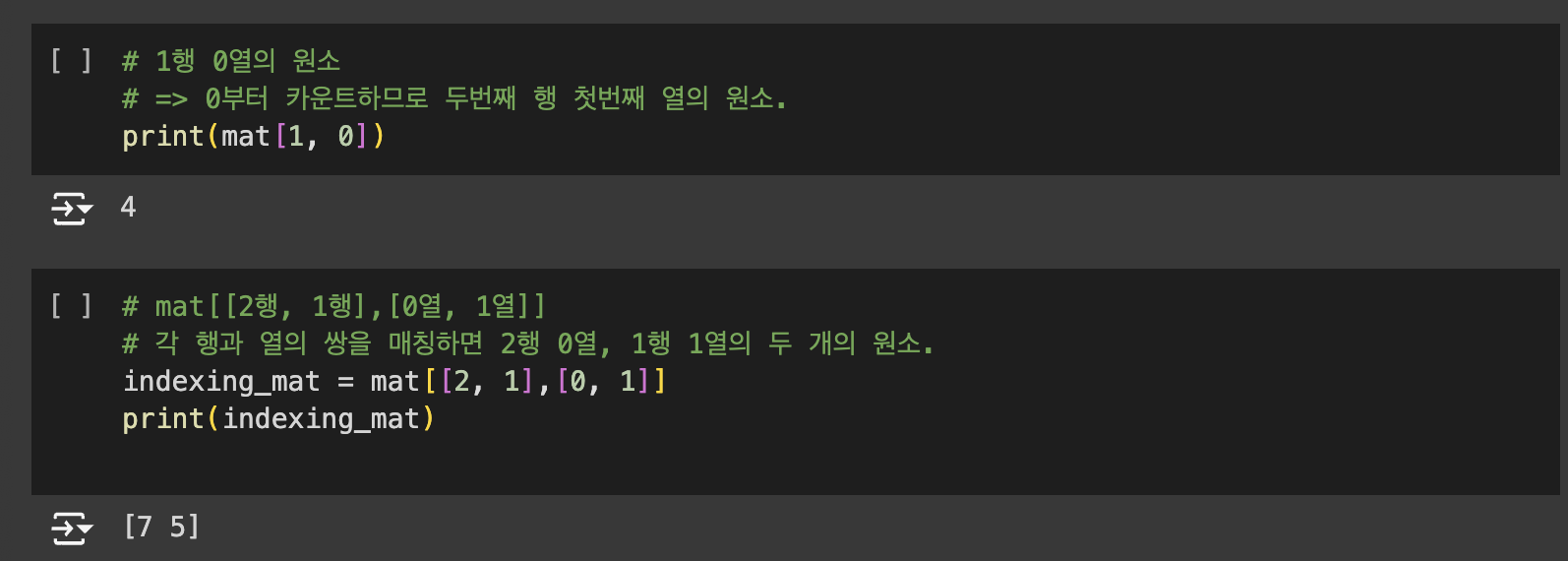
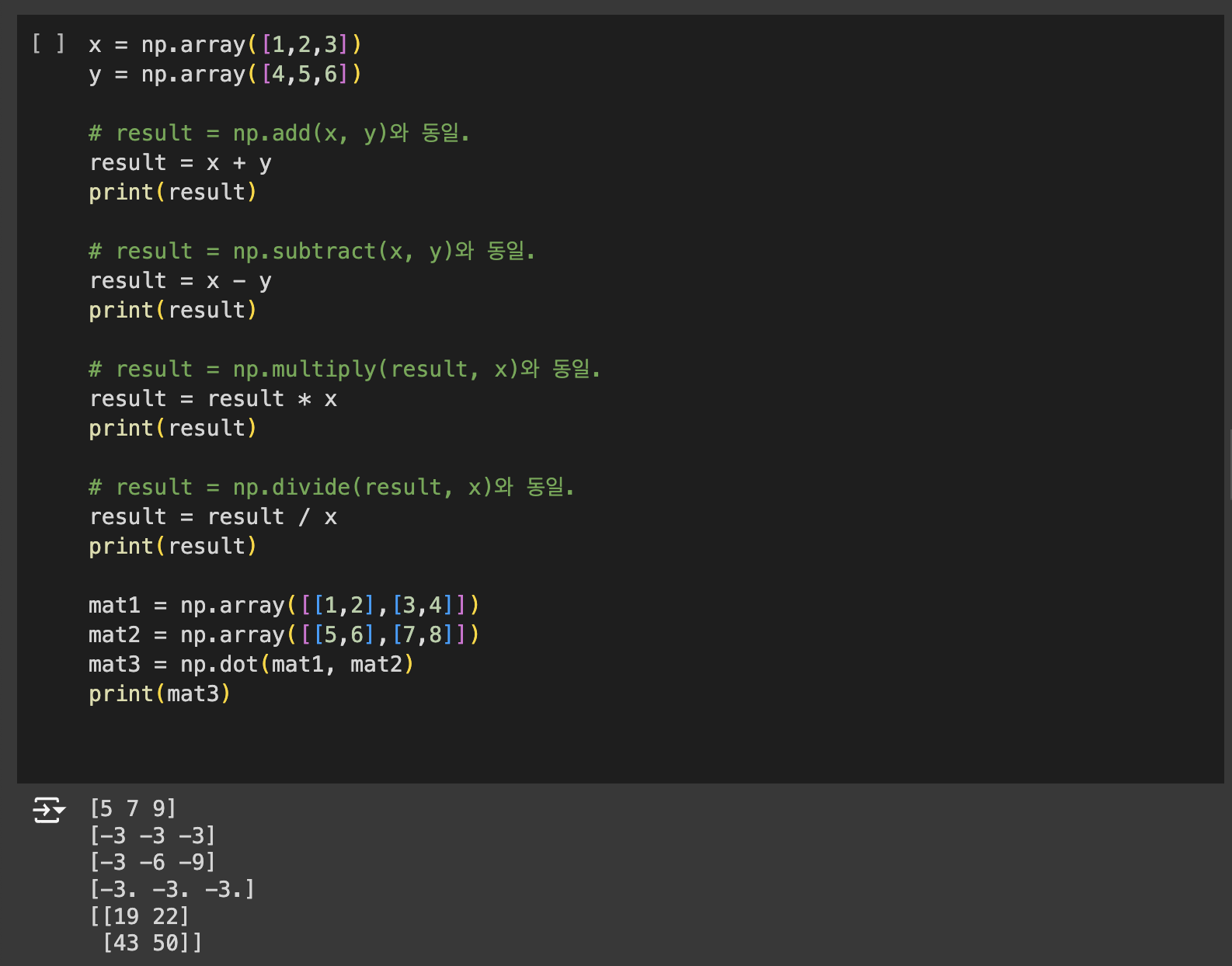
 Numpy의 핵심은 ndarray입니다. np.array()는 리스트, 튜플, 배열로 부터 ndarray를 생성합니다.
Numpy의 핵심은 ndarray입니다. np.array()는 리스트, 튜플, 배열로 부터 ndarray를 생성합니다.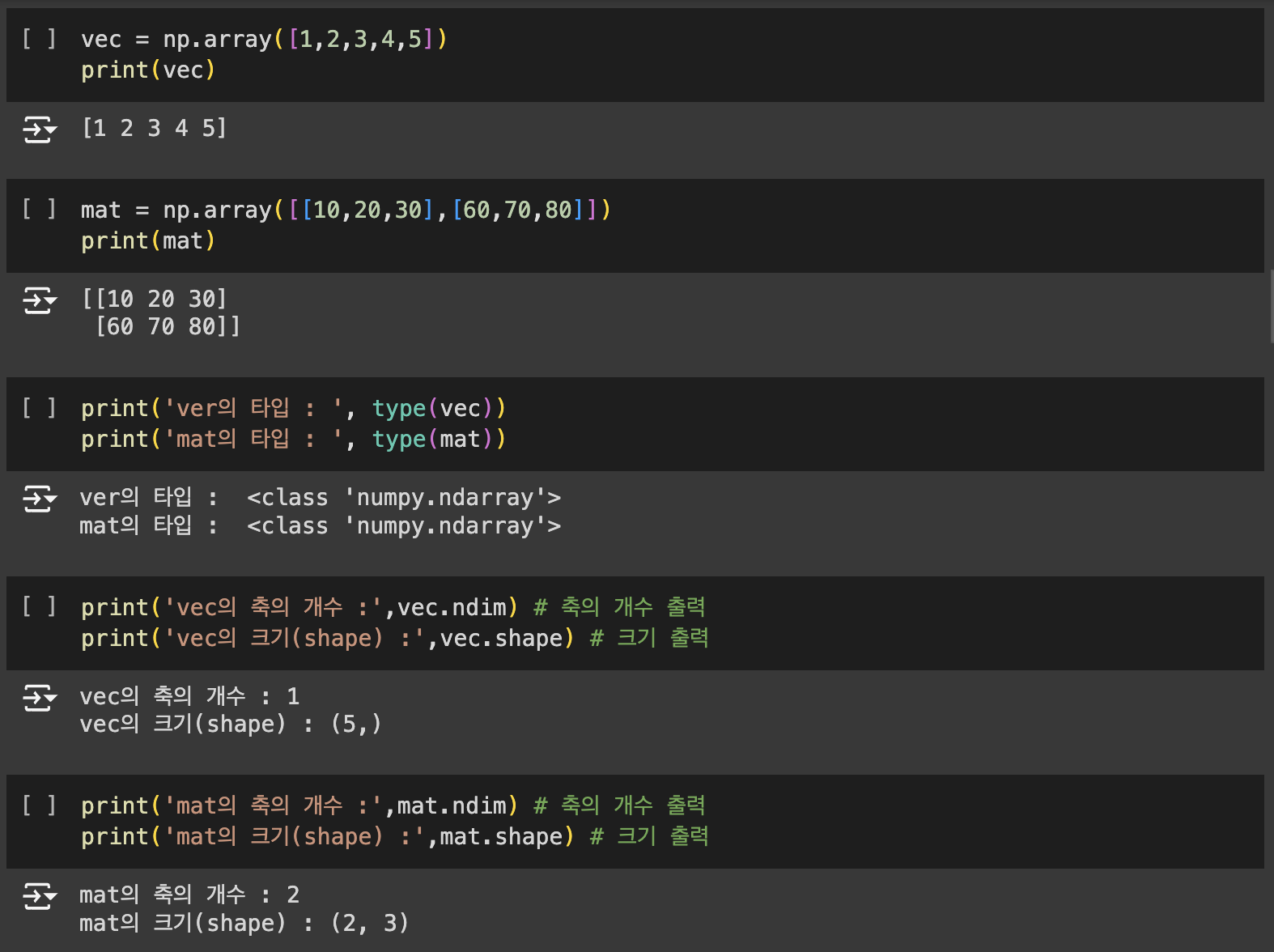
맷플롯립(Matplotlib)
맷플롯립(Matplotlib)은 데이터를 차트(chart)나 플롯(plot)으로 시각화하는 패키지입니다. 데이터 분석에서 Matplotlib은 데이터 분석 이전에 데이터 이해를 위한 시각화나, 데이터 분석 후에 결과를 시각화하기 위해서 사용됩니다.
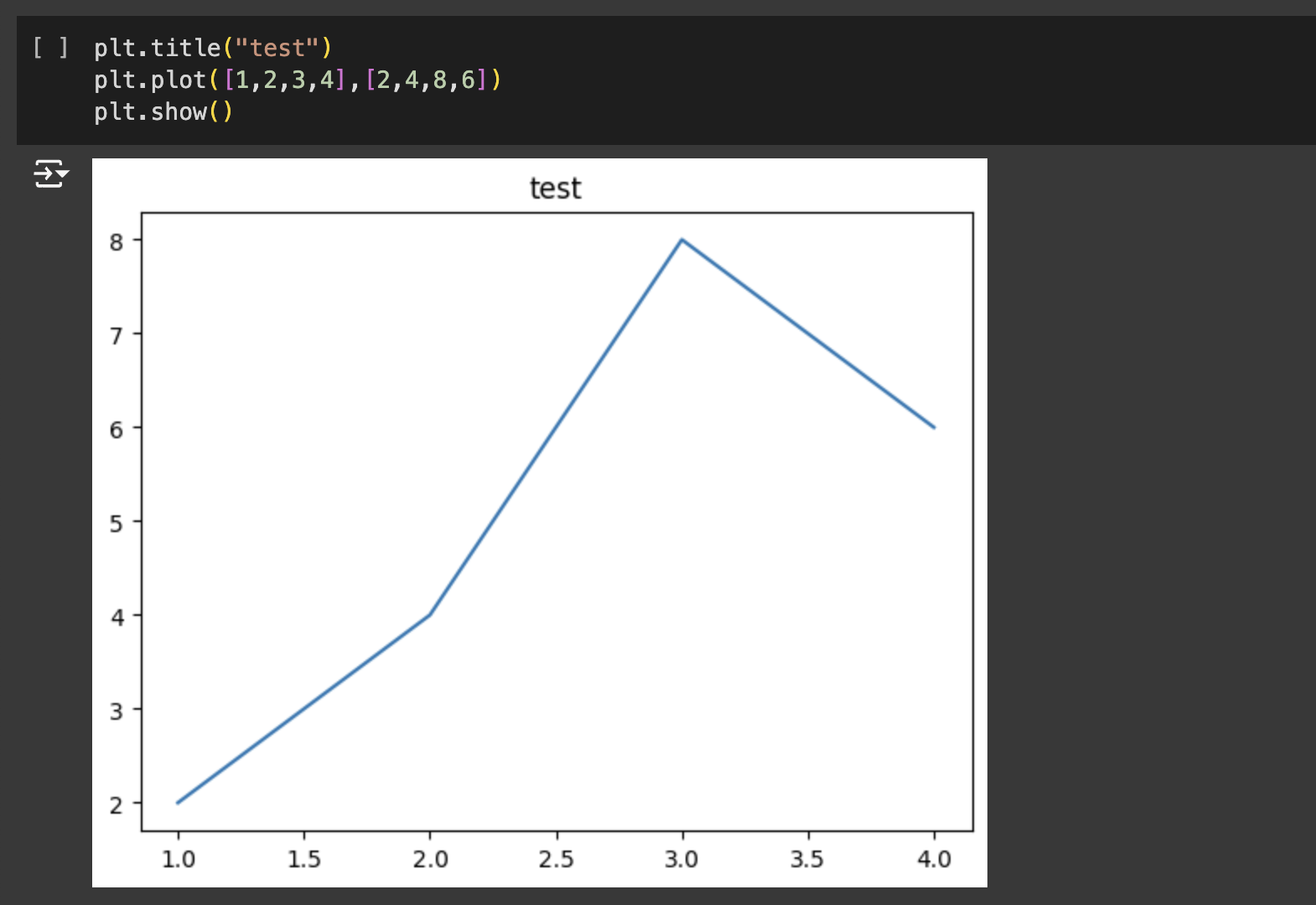
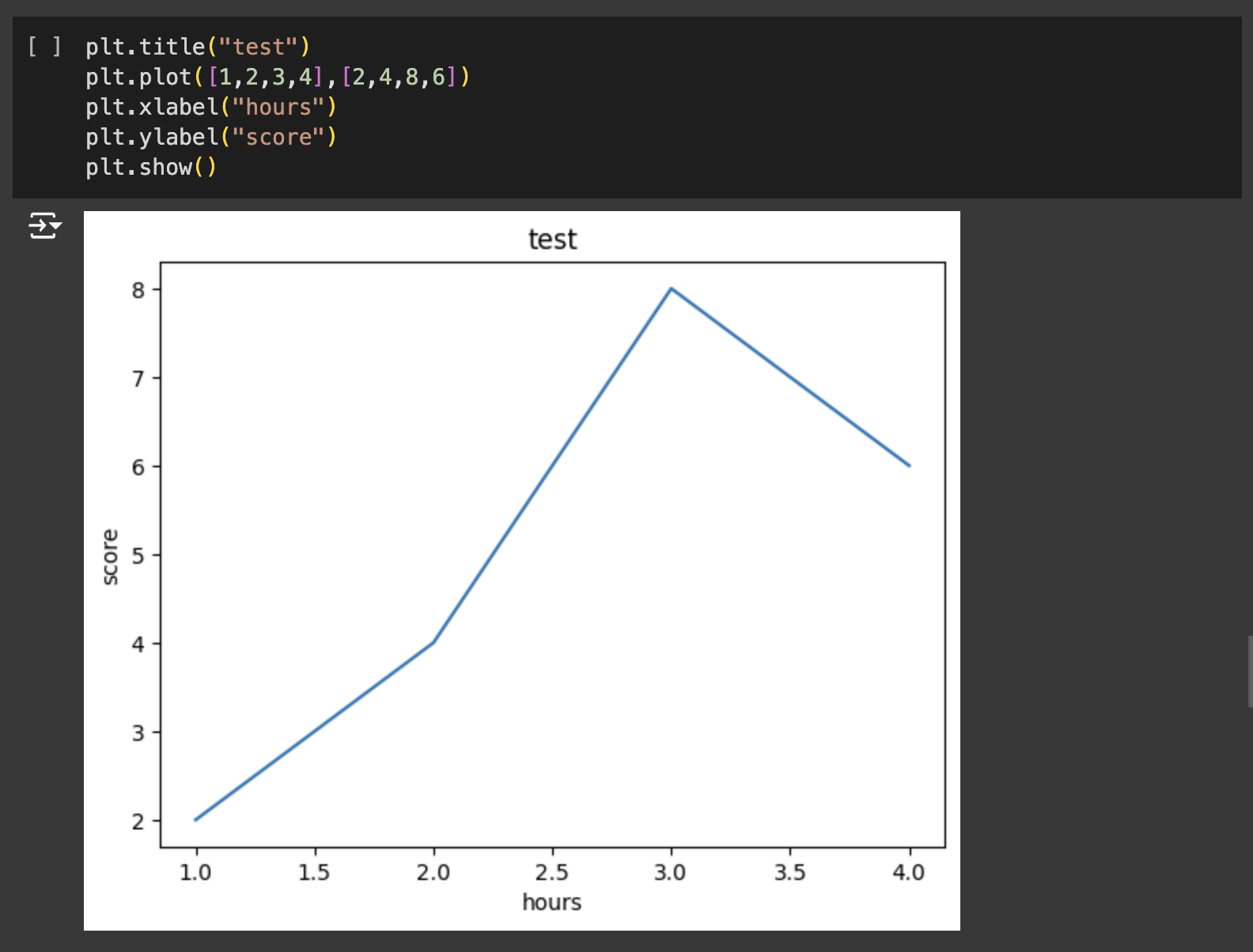
데이터의 분리(Splitting Data)

1. 지도 학습(Supervised Learning)
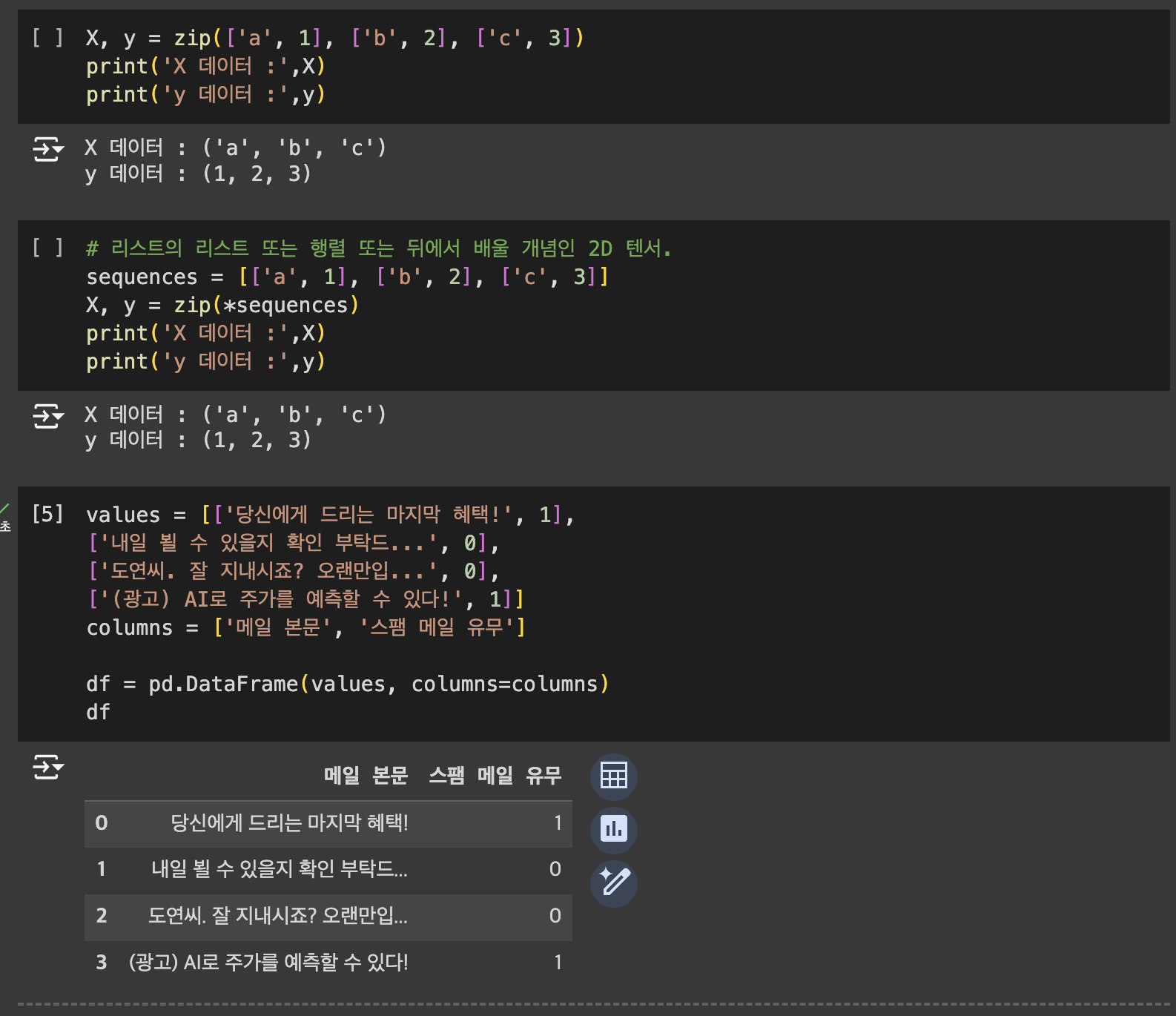
2. X와 y분리하기
zip 함수를 이용하여 분리하기 + 데이터프레임을 이용하여 분리하기
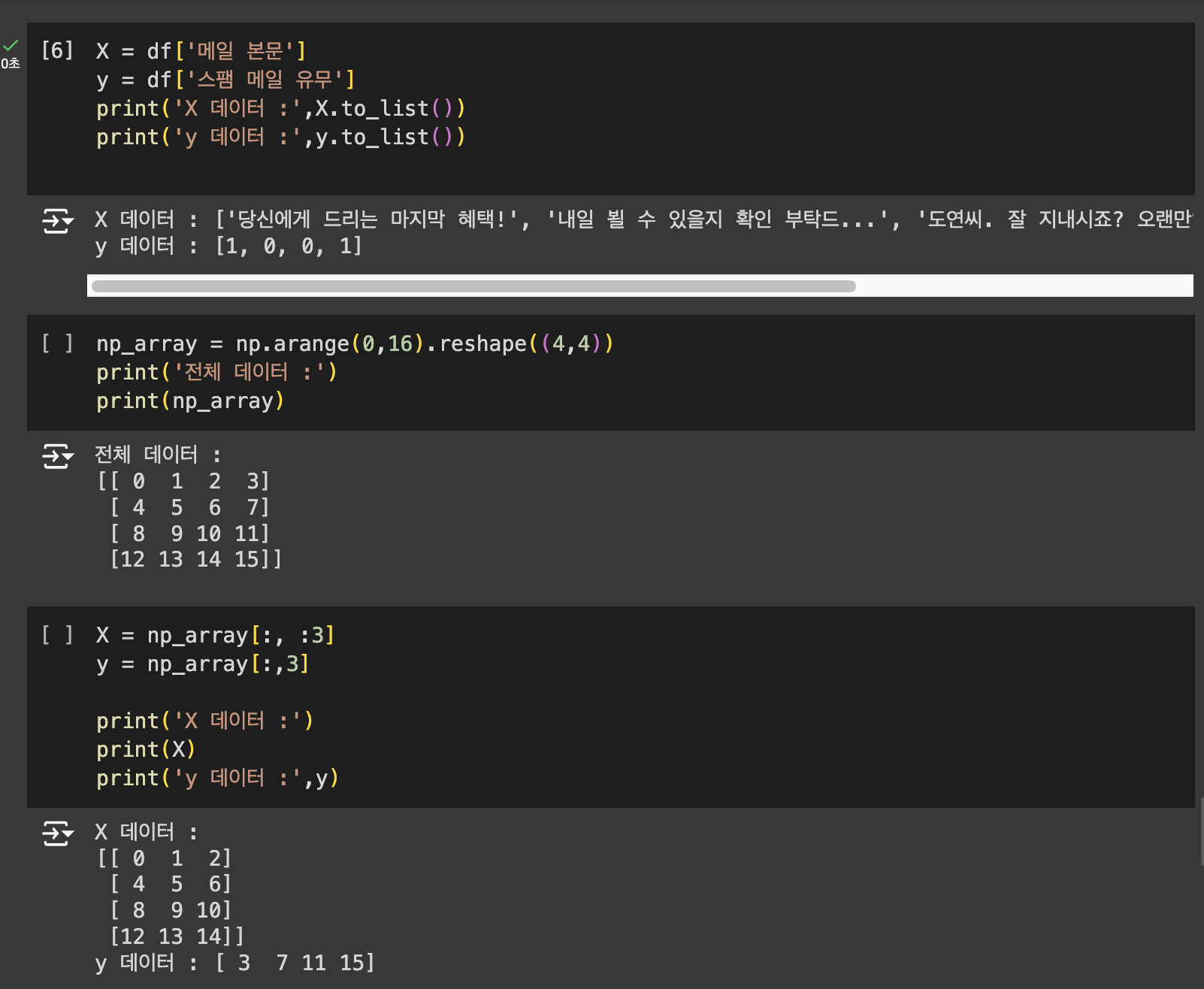
Numpy를 이용하여 분리하기
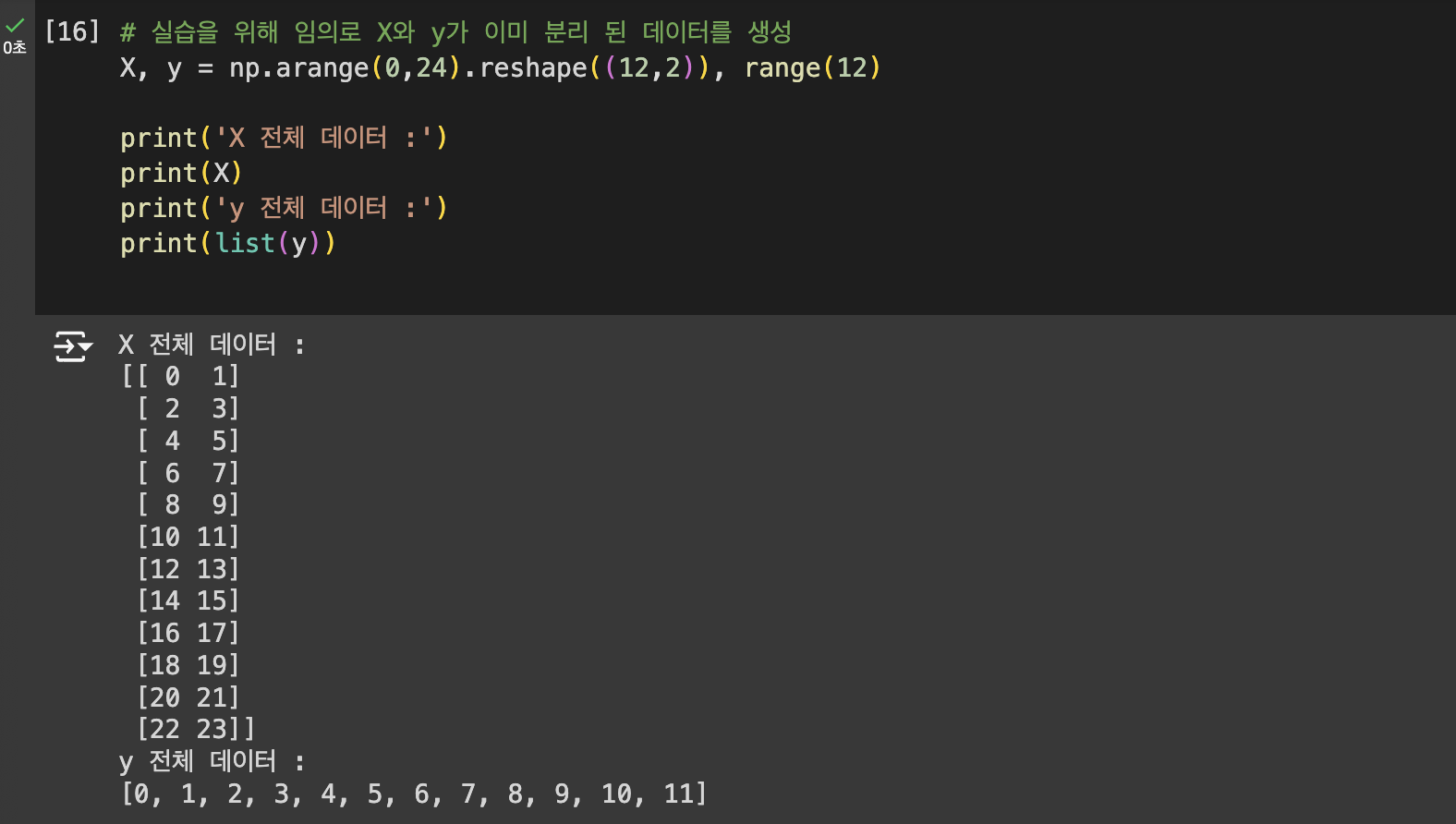
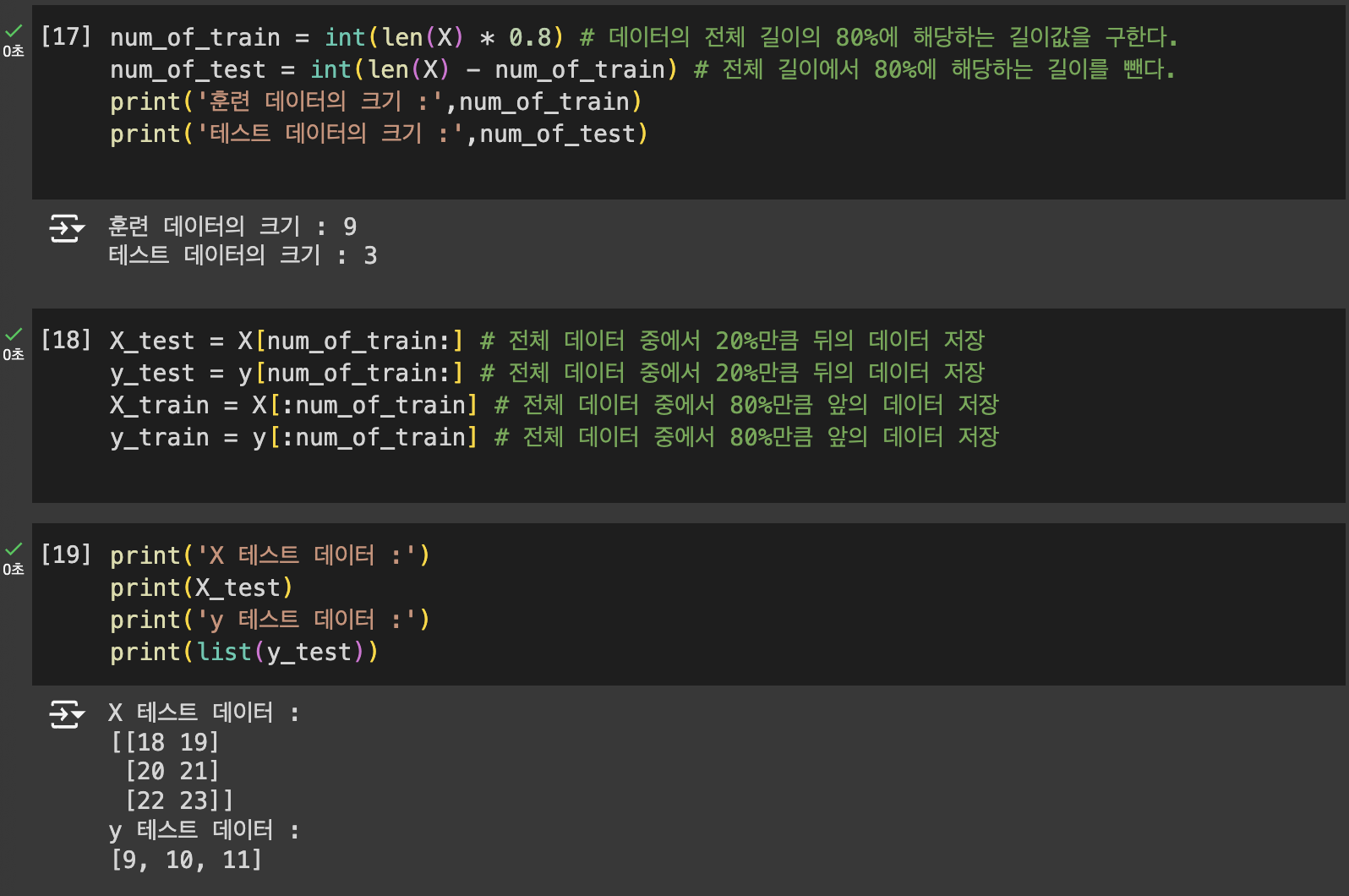
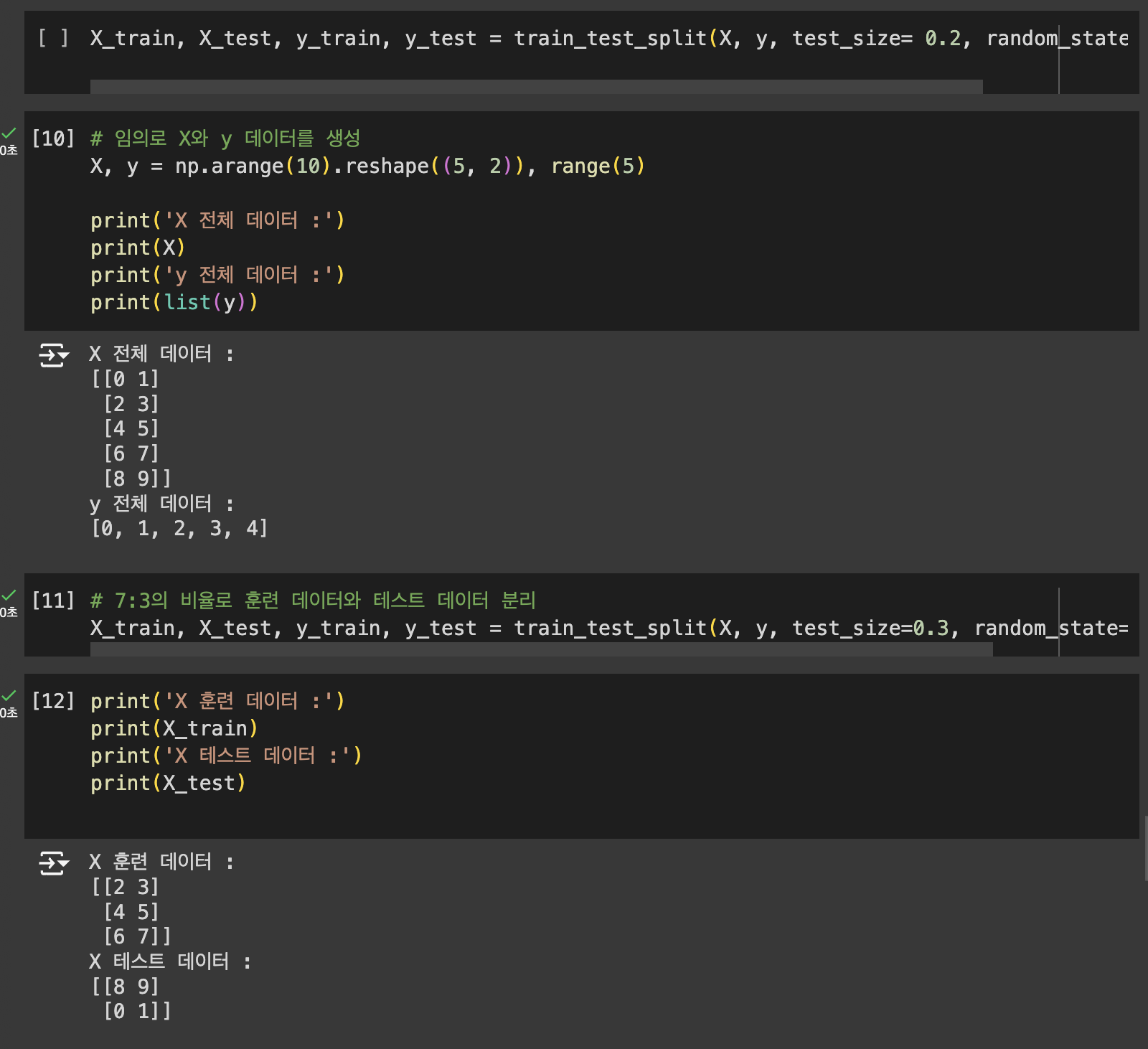
3. 테스트 데이터 분리하기
사이킷 런을 이용하여 분리하기
수동으로 분리하기