Spring AI에 대하여

들어가며
최근 AI와 LLM이 소프트웨어 개발의 새로운 패러다임으로 자리 잡으면서, 기존 Spring 생태계에서도 이러한 변화에 대응할 수 있는 프레임워크가 필요해졌다. Spring AI는 이런 요구에 응답하여 탄생한 프레임워크로, Spring 개발자들이 익숙한 방식으로 AI 기능을 통합할 수 있게 해준다.
AI에 큰 관심과 향후 커리어에 AI를 접목하고싶은 서버 개발자로서, 이 글을 통해 Spring AI의 핵심 개념들을 기술적으로 간단히 살펴보고 실제 구현에서 고려해야 할 세부사항들을 정리해보려 한다.
Spring AI란?
Spring AI는 AI 엔지니어링을 위한 애플리케이션 프레임워크다. 핵심 목표는 Spring 생태계의 설계 원칙인 이식성(Portability)과 모듈화 설계(Modular Design) 를 AI 도메인에 적용하여, POJO를 애플리케이션의 구성 요소로 활용할 수 있게 하는 것이다.
Spring AI의 핵심 가치
1. 벤더 중립성 (Vendor Neutrality)
Spring AI의 가장 큰 장점 중 하나는 벤더 중립성인 추상화다. 이는 다음과 같은 이점을 제공한다.
1
2
3
4
5
6
7
8
// OpenAI 사용
ChatModel openAiModel = new OpenAiChatModel(openAiApi);
// Anthropic으로 변경 시 - 인터페이스는 동일
ChatModel anthropicModel = new AnthropicChatModel(anthropicApi);
// 코드 변경 없이 모델 교체 가능
String response = chatModel.call("안녕하세요");
2. Spring 생태계와의 일관성
Spring Boot의 Auto Configuration, Dependency Injection 등 기존 Spring 개발자들이 익숙한 패턴을 그대로 활용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@RestController
public class ChatController {
private final ChatModel chatModel;
// Constructor Injection
public ChatController(ChatModel chatModel) {
this.chatModel = chatModel;
}
@PostMapping("/chat")
public String chat(@RequestBody String message) {
return chatModel.call(message);
}
}
Spring AI의 핵심 아키텍처
1. Message 추상화 계층
Spring AI는 다양한 LLM 벤더들의 메시지 형식을 통일된 인터페이스로 추상화한다.
1
2
3
4
5
public interface Message {
MessageType getMessageType();
String getContent();
Map<String, Object> getMetadata();
}
Message 타입별 특징
SystemMessage: LLM의 행동을 정의하는 시스템 지시사항
1
2
3
SystemMessage systemMessage = new SystemMessage(
"당신은 한국어로 친근하게 대화하는 AI 어시스턴트입니다."
);
UserMessage: 사용자의 실제 질문이나 요청
1
UserMessage userMessage = new UserMessage("Spring AI에 대해 설명해주세요.");
AssistantMessage: AI의 응답 메시지
1
AssistantMessage assistantMessage = new AssistantMessage("Spring AI는...");
2. ChatOptions의 상세 파라미터
ChatOptions는 LLM 호출 시 사용되는 파라미터들을 정의한다. 각 파라미터의 의미와 활용법을 살펴보자.
Temperature (창의성 조절)
- 범위:
0.0 ~ 2.0 - 의미: 응답의 창의성과 무작위성 조절
- 활용:
0.0: 일관되고 예측 가능한 응답 (FAQ, 번역)0.7: 균형잡힌 창의성 (일반 대화)1.5+: 높은 창의성 (브레인스토밍, 창작)
1
2
3
4
5
6
7
ChatOptions conservativeOptions = ChatOptions.builder()
.temperature(0.1f) // 매우 일관된 응답
.build();
ChatOptions creativeOptions = ChatOptions.builder()
.temperature(1.2f) // 창의적인 응답
.build();
MaxTokens (응답 길이 제한)
1
2
3
4
5
6
7
ChatOptions shortResponse = ChatOptions.builder()
.maxTokens(100) // 짧은 응답
.build();
ChatOptions detailedResponse = ChatOptions.builder()
.maxTokens(2000) // 상세한 응답
.build();
Stop Sequences (응답 중단 조건)
1
2
3
ChatOptions codeGeneration = ChatOptions.builder()
.stopSequences(Arrays.asList("```", "END_CODE"))
.build();
TopP와 TopK (토큰 선택 전략)
TopP (Nucleus Sampling): 누적 확률이 P 이하인 토큰들만 고려TopK: 상위 K개 토큰만 고려
1
2
3
4
ChatOptions focusedOptions = ChatOptions.builder()
.topP(0.8f) // 상위 80% 확률 토큰만 사용
.topK(40) // 상위 40개 토큰만 고려
.build();
3. ChatModel의 내부 동작 메커니즘
ChatModel 인터페이스의 구현체들이 어떻게 동작하는지 상세히 살펴보자.
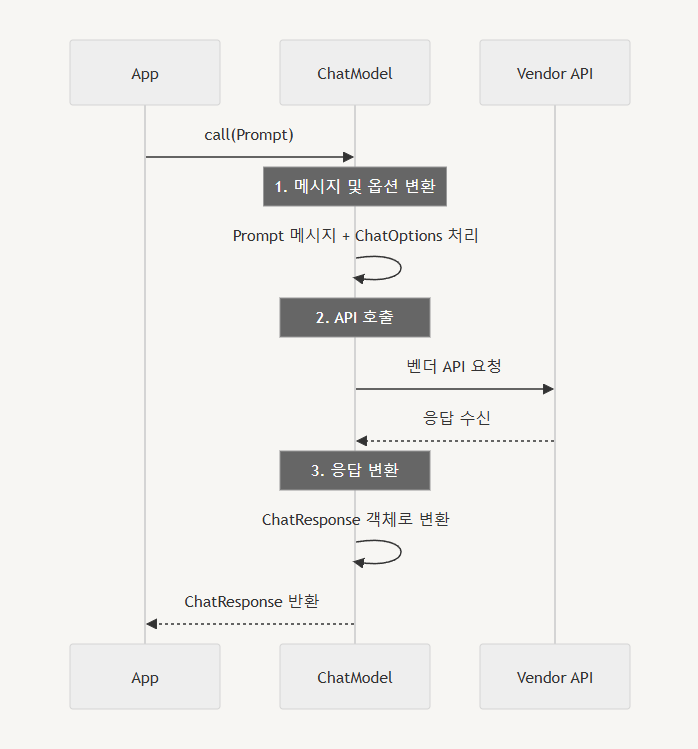
-
입력으로 받은
Prompt를 벤더의 API 형식에 맞게 변환합니다. -
변환된 메시지를 사용하여 벤더의 API를 호출합니다.
-
벤더로부터 받은 응답을
ChatResponse형식으로 변환하여 반환합니다.
요청 변환 과정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class OpenAiChatModel implements ChatModel {
@Override
public ChatResponse call(Prompt prompt) {
// 1. Spring AI Prompt → OpenAI API 형식 변환
OpenAiChatCompletionRequest request = convertToOpenAiRequest(prompt);
// 2. HTTP 요청 실행
OpenAiChatCompletionResponse apiResponse = openAiApi.chatCompletion(request);
// 3. OpenAI 응답 → Spring AI ChatResponse 변환
return convertToChatResponse(apiResponse);
}
private OpenAiChatCompletionRequest convertToOpenAiRequest(Prompt prompt) {
return OpenAiChatCompletionRequest.builder()
.model(prompt.getOptions().getModel())
.messages(convertMessages(prompt.getInstructions()))
.temperature(prompt.getOptions().getTemperature())
.maxTokens(prompt.getOptions().getMaxTokens())
.stop(prompt.getOptions().getStopSequences())
.build();
}
}
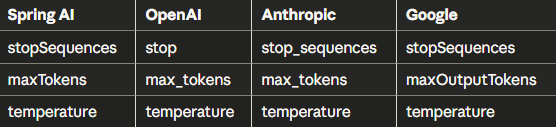
벤더별 파라미터 매핑
각 벤더마다 파라미터 이름이 다르지만, Spring AI가 자동으로 매핑해준다:
4. ChatResponse의 메타데이터 활용
ChatResponse에는 응답 텍스트뿐만 아니라 유용한 메타데이터가 포함된다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
ChatResponse response = chatModel.call(prompt);
// 기본 응답 텍스트
String content = response.getResult().getOutput().getContent();
// 토큰 사용량 정보
ChatResponseMetadata metadata = response.getMetadata();
Usage usage = metadata.getUsage();
System.out.println("프롬프트 토큰: " + usage.getPromptTokens());
System.out.println("생성된 토큰: " + usage.getGenerationTokens());
System.out.println("전체 토큰: " + usage.getTotalTokens());
// 모델 정보
System.out.println("사용된 모델: " + metadata.getModel());
// 완료 이유 (정상 완료, 길이 제한, 중단 시퀀스 등)
FinishReason finishReason = response.getResult().getMetadata().getFinishReason();
Spring AI로 구현하는 RAG 시스템
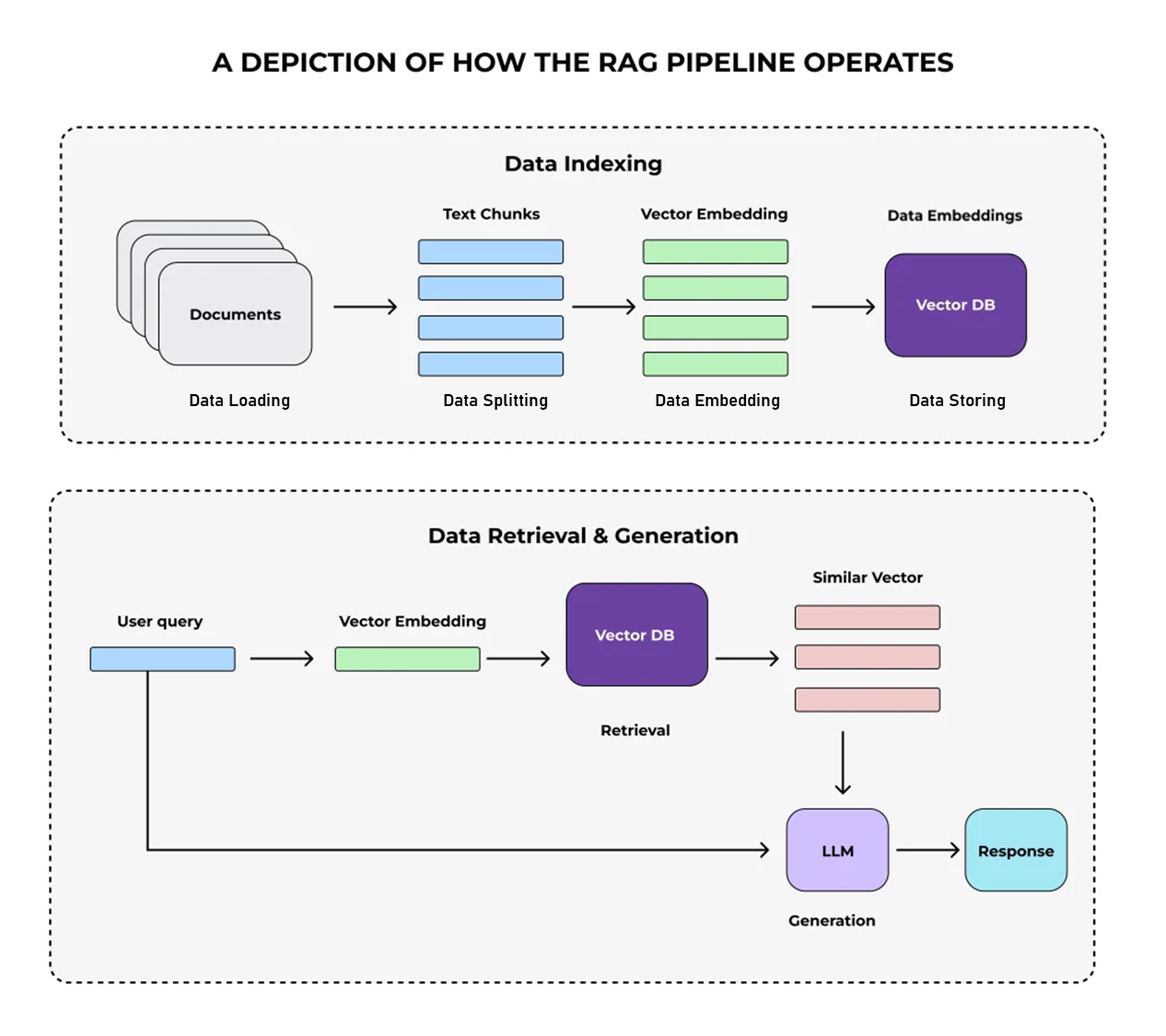
단순한 LLM 호출을 넘어, Spring AI는 RAG(Retrieval-Augmented Generation) 시스템 구축도 강력하게 지원한다. RAG는 외부 데이터를 검색하여 LLM에게 맥락을 제공함으로써, 더 정확하고 신뢰할 수 있는 답변을 생성하도록 도와주는 기술이다.
RAG가 필요한 이유
LLM은 아무리 뛰어난 모델이라도 학습한 지식 안에서만 답변할 수 있다. 특정 기업의 사내 문서나 최신 법률처럼 외부 도메인 지식이 필요한 경우에는, 전혀 엉뚱한 답을 하거나 틀린 정보(Hallucination)를 말하기도 한다.
RAG는 이런 문제를 해결하기 위해 등장한 개념으로, 크게 두 단계로 나뉜다:
Data Indexing: 문서를 청킹하고 벡터화하여 저장Data Retrieval & Generation: 질문과 유사한 문서를 검색하여 LLM에 컨텍스트로 제공
Spring AI RAG 핵심 컴포넌트
1. EmbeddingModel - 텍스트를 벡터로 변환
LLM과 검색 시스템을 연결하는 첫 번째 단계는 임베딩이다. Spring AI는 EmbeddingModel 인터페이스를 통해 다양한 벤더의 임베딩 모델을 쉽게 연동할 수 있게 해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public interface EmbeddingModel extends Model<EmbeddingRequest, EmbeddingResponse> {
EmbeddingResponse call(EmbeddingRequest request);
// 단일 텍스트 임베딩
default float[] embed(String text);
// 문서 임베딩
float[] embed(Document document);
// 다중 텍스트 임베딩
default List<float[]> embed(List<String> texts);
// 메타데이터와 함께 임베딩
default EmbeddingResponse embedForResponse(List<String> texts);
// 임베딩 차원 수
default int dimensions();
}
사용 예시:
1
2
3
4
5
6
7
8
9
10
11
// OpenAI 임베딩 모델 설정
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(apiKey)
.options(OpenAiEmbeddingOptions.builder()
.model("text-embedding-3-small")
.build())
.build();
// 텍스트를 벡터로 변환
float[] embedding = embeddingModel.embed("Spring AI는 훌륭한 프레임워크다");
System.out.println("임베딩 차원: " + embedding.length);
2. VectorStore - 벡터 저장 및 유사도 검색
벡터 저장소는 임베딩된 문서를 저장하고, 질문과 유사한 문서를 빠르게 검색해주는 핵심 컴포넌트다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public interface VectorStore extends DocumentWriter {
// 저장소 이름
default String getName() { return this.getClass().getSimpleName(); }
// 문서 추가
void add(List<Document> documents);
// 문서 삭제
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
// 유사도 검색
List<Document> similaritySearch(String query);
List<Document> similaritySearch(SearchRequest request);
}
단계별 벡터스토어 확장 전략:
- 1단계: 개발/테스트 - SimpleVectorStore
1
2
3
// 인메모리 벡터 저장소
VectorStore vectorStore = SimpleVectorStore.builder(embeddingModel)
.build();
- 2단계: 프로덕션 - PGVector
1
2
3
4
5
6
// PostgreSQL 기반 벡터 저장소
VectorStore prodStore = PgVectorStore.builder(jdbcTemplate, embeddingModel)
.dimensions(1536) // OpenAI text-embedding-3-small 차원
.distanceType(PgDistanceType.COSINE_DISTANCE)
.removeExistingVectorStoreTable(false)
.build();
- 3단계: 대규모 - Qdrant, Milvus
1
2
3
4
5
6
7
// 대규모 벡터 검색을 위한 전문 DB
VectorStore qdrantStore = QdrantVectorStore.builder()
.host("localhost")
.port(6333)
.collectionName("spring-ai-docs")
.embeddingModel(embeddingModel)
.build();
3. TextSplitter - 문서 청킹 전략
LLM은 긴 문서를 한 번에 처리하지 못하기 때문에, 문서를 적절한 길이로 나누는 작업이 필요하다.
1
2
3
4
5
6
7
8
9
10
11
12
public abstract class TextSplitter implements DocumentTransformer {
// 다중 문서 분할
public List<Document> split(List<Document> documents);
// 단일 문서 분할
public List<Document> split(Document document);
}
public class TokenTextSplitter extends TextSplitter {
protected List<String> doSplit(String text, int chunkSize);
}
청킹 전략별 활용:
- 토큰 기반 분할
1
2
3
4
TextSplitter tokenSplitter = TokenTextSplitter.builder()
.withChunkSize(500) // 500 토큰 단위
.withChunkOverlap(50) // 50 토큰 겹침
.build();
- 문단 기반 분할
1
2
3
4
TextSplitter paragraphSplitter = ParagraphTextSplitter.builder()
.withChunkSize(1000)
.withChunkOverlap(100)
.build();
- 커스텀 분할
1
2
3
4
5
6
7
TextSplitter customSplitter = new TextSplitter() {
@Override
protected List<String> doSplit(String text, int chunkSize) {
// 섹션 헤더 기준으로 분할하는 커스텀 로직
return Arrays.asList(text.split("(?=## )"));
}
};
완전한 RAG 구현 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
@Service
public class DocumentRAGService {
private final ChatModel chatModel;
private final EmbeddingModel embeddingModel;
private final VectorStore vectorStore;
private final TextSplitter textSplitter;
public DocumentRAGService(ChatModel chatModel,
EmbeddingModel embeddingModel,
VectorStore vectorStore) {
this.chatModel = chatModel;
this.embeddingModel = embeddingModel;
this.vectorStore = vectorStore;
this.textSplitter = TokenTextSplitter.builder()
.withChunkSize(500)
.withChunkOverlap(50)
.build();
}
// 1단계: 문서 인덱싱
public void indexDocument(String documentContent, Map<String, Object> metadata) {
// 1. 문서 생성
Document document = new Document(documentContent, metadata);
// 2. 청킹
List<Document> chunks = textSplitter.split(document);
// 3. 벡터 저장소에 저장 (자동으로 임베딩 생성됨)
vectorStore.add(chunks);
log.info("문서 인덱싱 완료: {} 개 청크", chunks.size());
}
// 2단계: RAG 기반 질의응답
public String answerQuestion(String question) {
// 1. 유사 문서 검색
SearchRequest searchRequest = SearchRequest.builder()
.query(question)
.topK(5) // 상위 5개 유사 문서
.similarityThreshold(0.7) // 유사도 임계값
.build();
List<Document> relevantDocs = vectorStore.similaritySearch(searchRequest);
if (relevantDocs.isEmpty()) {
return "관련된 문서를 찾을 수 없습니다.";
}
// 2. 컨텍스트 구성
String context = relevantDocs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
// 3. RAG 프롬프트 구성
String prompt = String.format("""
다음 문서들을 참고하여 질문에 답변해주세요.
=== 참고 문서 ===
%s
=== 질문 ===
%s
=== 답변 규칙 ===
- 참고 문서의 내용을 바탕으로만 답변해주세요
- 문서에 없는 내용은 추측하지 마세요
- 출처를 명시해주세요
""", context, question);
// 4. LLM 호출
ChatResponse response = chatModel.call(prompt);
return response.getResult().getOutput().getContent();
}
// 문서 업데이트
public void updateDocument(String documentId, String newContent) {
// 기존 문서 삭제
vectorStore.delete(Arrays.asList(documentId));
// 새 문서 인덱싱
Map<String, Object> metadata = Map.of("id", documentId);
indexDocument(newContent, metadata);
}
}
RAG 시스템 최적화 전략
-
검색 정확도 향상
-
메타데이터 필터링: 날짜, 카테고리, 작성자 등으로 검색 범위를 제한하여 관련성 높은 문서만 검색한다.
-
하이브리드 검색: 키워드 검색과 벡터 검색을 결합하여 정확도를 높인다. 키워드로 정확한 용어 매칭을, 벡터로 의미적 유사성을 모두 활용할 수 있다.
-
리랭킹: 초기 검색 결과를 다시 정렬하여 질문과 가장 관련성 높은 문서를 우선순위로 배치한다.
-
-
청킹 전략 최적화
-
계층적 청킹: 문서를 섹션 → 문단 → 문장 순으로 단계적 분할하여 문맥을 보존한다.
-
의미 기반 청킹: 고정 길이가 아닌 문맥상 완결된 단위로 분할한다. 표나 코드 블록 같은 구조화된 데이터는 온전하게 유지한다.
-
오버랩 전략: 청크 간 일정 부분을 겹치게 하여 문맥 손실을 방지한다. 보통 전체 길이의 10-20% 정도가 적절하다.
-
-
성능 최적화
-
배치 처리: 다수 문서를 한 번에 임베딩하여 API 호출 비용과 응답 시간을 줄인다.
-
캐싱: 자주 사용되는 임베딩 결과를 Redis나 메모리에 캐시하여 중복 계산을 방지한다.
-
벡터 압축: 임베딩 차원을 줄이거나 양자화하여 저장 공간과 검색 속도를 개선한다.
-
실전 구현 시 고려사항
1. 비동기 처리
LLM 호출은 보통 3-10초의 응답 시간이 소요되므로 비동기 처리가 필수다. Spring의 @Async 어노테이션을 활용하여 사용자 요청을 논블로킹으로 처리할 수 있다.
1
2
3
4
5
6
7
8
@Service
public class AsyncChatService {
@Async
public CompletableFuture<String> getChatResponseAsync(String message) {
return CompletableFuture.supplyAsync(() -> chatModel.call(message));
}
}
2. 스트리밍 응답
긴 답변의 경우 사용자 경험을 위해 실시간 스트리밍 응답을 제공하는 것이 좋다. Spring AI는 Reactive Streams를 지원한다.
3. 에러 처리 및 재시도
LLM 서비스는 네트워크 이슈나 토큰 제한으로 실패할 수 있으므로 Resilience4j나 Spring Retry를 활용한 재시도 로직이 필요하다.
마치며
Spring AI는 기존 Spring 개발자들이 AI 기능을 자연스럽게 통합할 수 있게 해주는 강력한 프레임워크다. 벤더 중립적인 추상화를 통해 모델 변경의 유연성을 제공하고, Spring 생태계의 장점들을 그대로 활용할 수 있다.
특히 RAG 시스템 구축을 위한 EmbeddingModel, VectorStore, TextSplitter 등의 컴포넌트들이 잘 추상화되어 있어서, 복잡한 문서 검색 기반 AI 서비스도 Spring 개발자라면 쉽게 구현할 수 있다.
실제 프로덕션 환경에서는 비동기 처리, 에러 처리, 토큰 사용량 모니터링, 벡터 저장소 확장성 등을 고려한 robust한 구현이 필요하며, Spring AI는 이런 요구사항들을 충족할 수 있는 충분한 확장성을 제공한다.
Spring AI를 활용하면 단순한 챗봇부터 고도화된 도메인 특화 AI 어시스턴트까지, 다양한 AI 서비스를 Spring 스타일로 우아하게 구현할 수 있을 것이다.